AI生成图像竟如此真实了?Stable Diffusion Model本地部署教程
Posted 小嗷犬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI生成图像竟如此真实了?Stable Diffusion Model本地部署教程相关的知识,希望对你有一定的参考价值。

✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。
🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
本文目录
图像生成
Stable Diffusion Model 是一个基于扩散模型的图像生成模型。早在模型刚刚兴起的时候,博主就有所关注,尝试过本地部署,但是由于设备硬件配置限制,最终也没有能够真正的在本地跑起来。
考虑到人工智能各个领域的模型都是往着大模型方向发展,所以博主觉得如果当时跑不起来,在不更新硬件的情况下,以后也没有机会再跑了。
当时各个在线 AI 图片生成平台生成的效果往往都不尽人意,并且不支持自己训练模型,博主就很长一段时间没有再关注这个领域了。
前几天偶然发现 AI 生成图片的效果有明显的提升,甚至可以说是有些惊艳了。于是博主在网上恶补了这段时间的相关知识,发现进步似乎比我想象的还要大。
stable-diffusion-webui
stable-diffusion-webui 是 AUTOMATIC1111 大佬在 Github 上开源的一个专用于图片生成模型的 WebUI,可以在本地部署,支持导入模型和自己训练。
重要的是,该项目的部署方式非常简单,不需要任何的编程基础,环境也会帮你自动配置好;GUI 的操作也非常简单,所见即所得。

你所做的只是要安装 git,下载项目,然后点击运行脚本,就可以了,部署和使用门槛大大降低。
Stable Diffusion Model
除了 stable-diffusion-webui 外,我们还需要一个图片生成模型才能生成图片。
模型可以自己训练,但我推荐第一次还是直接下载别人训练好的模型,这样可以直接体验。各种的 Stable Diffusion 模型可以在 Civitai 上找到。
现在的各种模型对硬件要求各不相同,有的模型不仅效果好于从前,而且硬件要求也比原来更低了。
博主使用的显卡为 NVIDIA GeForce RTX 3050 Ti Laptop GPU,只有 4G 显存。以前的模型连生成 128x128 的图片都会爆显存,现在的模型却可以生成 512x768 的图片。
硬件门槛也没有以前那么高了。
本地部署
本教程的设备要求:
- 显卡为 NVIDIA 显卡,显存大于 4G
- 硬盘空间足够
- Windows 系统
安装 git
首先,我们需要安装 git,如果你已经安装了 git,可以跳过这一步。
git 是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。
git 的安装非常简单,只需要在 git 官网 下载安装包,然后正常安装就可以了。
stable-diffusion-webui 需要使用它来自动配置环境。
项目下载
点击以下链接下载项目 release:
stable-diffusion-webui
项目部署
下载完成后,解压到任意目录,然后双击运行 update.bat,更新项目为最新版本。
当出现以下信息时,说明项目已经是最新的:
然后双击运行 run.bat,运行项目。首次运行会安装环境,所以需要等待一段时间。环境安装时出现错误通常属于 GitHub 的连接问题,可以自行设置代理。
安装的环境是 Pytorch 和 CUDA 以及一些 Python 第三方库和 Github 上的项目,安装过程中会自动下载。stable-diffusion-webui 自带 Python,所以不需要自己安装 Python 环境。
当出现以下信息时,说明 WebUI 已经运行在本地了:

在浏览器中访问 local URL,即可打开 WebUI。
模型导入
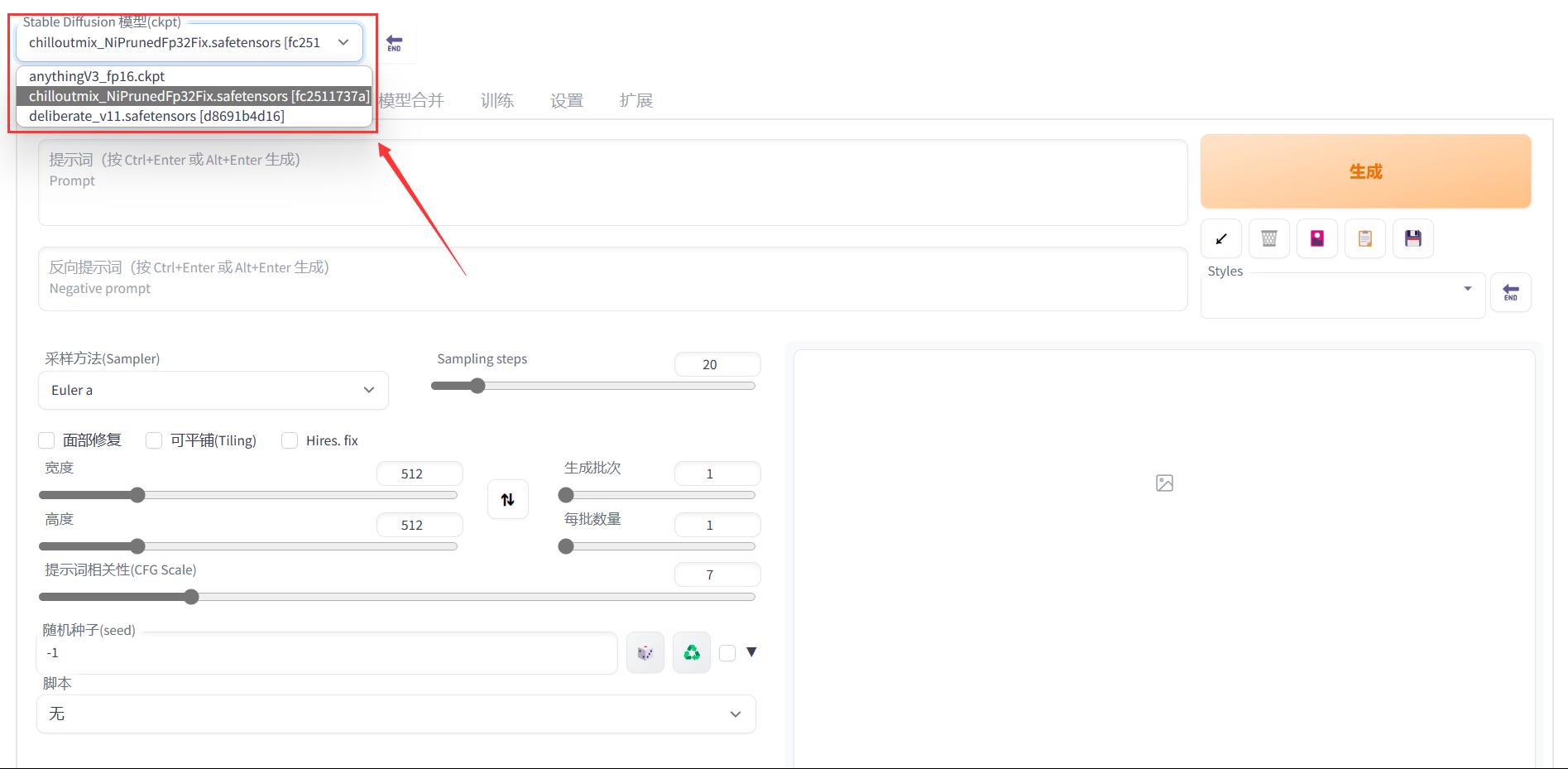
将 .safetensors 或 .ckpt 后缀的模型文件放入以下目录下,然后重启 WebUI 即可。
sd.webui/webui/models/Stable-diffusion/
多个模型之间还可以通过 WebUI 切换。
中文支持
在 WebUI 的 Extentions 中,选择 install from URL,输入以下 URL,点击 install:
https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN

安装完成之后,在 Settings 的 User interface 中,选择 Localization (requires restart),选择 zh-CN。
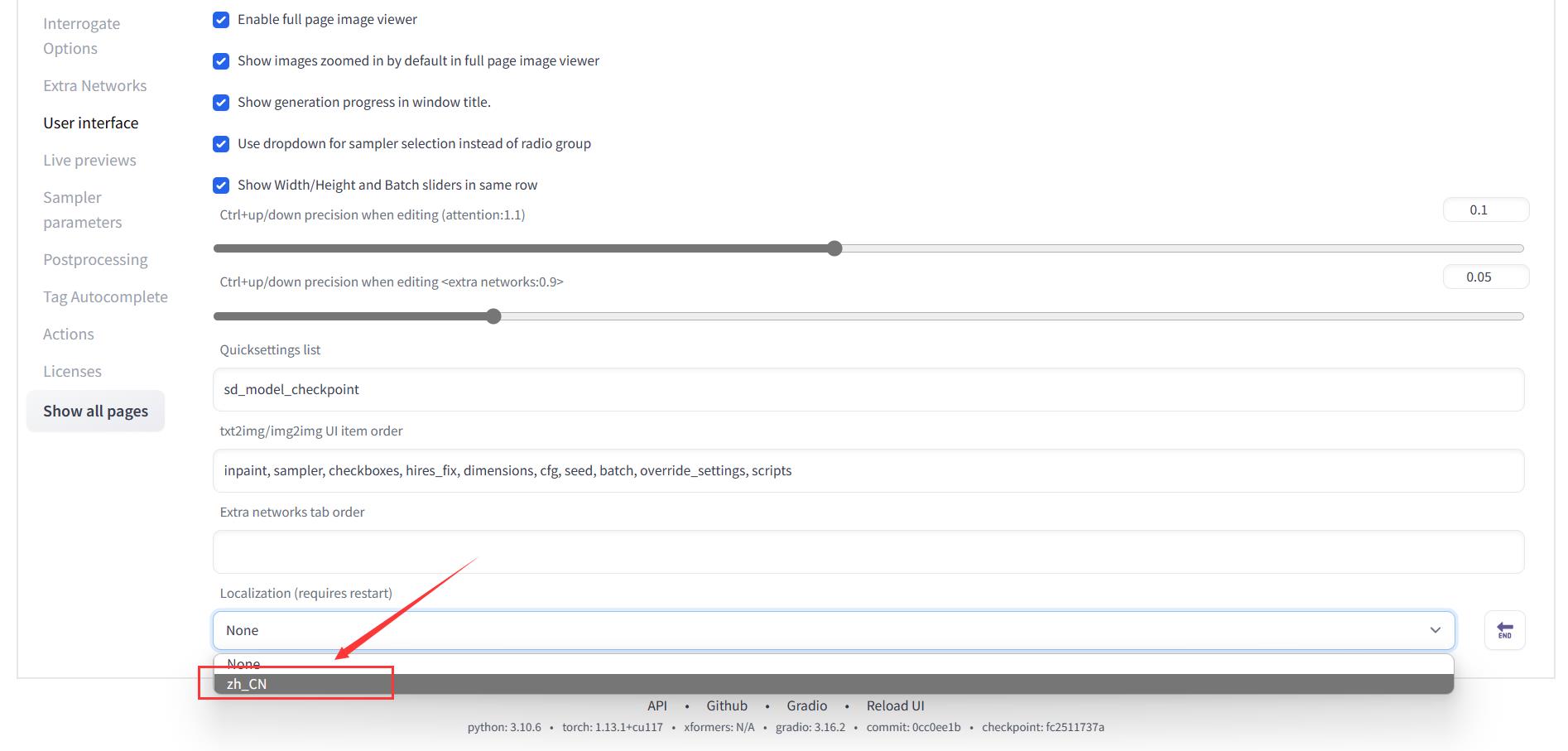
回到 Settings 最上面点击 Apply settings,然后点击 Reload UI。

UI汉化效果:

其他内容的安装
- Lora 文件可以放在
sd.webui/webui/models/Lora/下,通过 Prompt 输入 Lora 指令使用 - VAE 文件可以放在
sd.webui/webui/models/VAE/下,在设置的 Stable Diffusion 版面设置模型的 VAE - extensions 文件可以放在
sd.webui/webui/extensions/下,通过 WebUI 的 Extentions 版面启用 - textual inversion 文件可以放在
sd.webui/webui/embeddings/下,通过 Prompt 输入关键词使用
相关资源都可以在 Civitai 上找到,可以自行下载、安装、体验。
一些生成图片的展示
以下图片来自相同模型,使用同一 Prompt 进行随机生成:
图片被判定违规,图片效果请见:小嗷犬的技术小站 - AI生成图像竟如此真实了?Stable Diffusion Model本地部署教程
不同采样方法之间的比较
同一模型可以选择不同的采样方式进行采样,生成的图片也会有所不同。
以下图片都来自相同模型、相同 Prompt、相同 Seed 的生成结果,只是采样方法不同,其他参数完全一致。
图片被判定违规,对比图片效果请见:小嗷犬的技术小站 - AI生成图像竟如此真实了?Stable Diffusion Model本地部署教程
以上是关于AI生成图像竟如此真实了?Stable Diffusion Model本地部署教程的主要内容,如果未能解决你的问题,请参考以下文章