网页爬虫小记:两种方式的爬取网站内容
Posted gxyandwmm
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网页爬虫小记:两种方式的爬取网站内容相关的知识,希望对你有一定的参考价值。
此处进行简单的分类,对于普通的网页爬取内容,如果没有登录界面可以直接使用Jsoup的API进行爬取;
如果网站是在打开目标也之前需要进行登录,此时需要先使用用户加密码实现登录获取Cookie然后进行登录;
本文就第二种方式进行分析:
方式一、 httpClient中的PostMethod 或者 GetMethod
使用httpClient进行获得Cookie:
import org.apache.commons.httpclient.Cookie; import org.apache.commons.httpclient.HttpClient; import org.apache.commons.httpclient.NameValuePair; import org.apache.commons.httpclient.cookie.CookiePolicy; import org.apache.commons.httpclient.methods.GetMethod; import org.apache.commons.httpclient.methods.PostMethod; public class HttpLogin { public static void main(String[] args) { // 登陆前 Url String loginUrl = "http://passport.mop.com/?targetUrl=http://hi.mop.com/?&g=1447141423230&loginCheck=UNLOGINED";
// http客户端 HttpClient httpClient = new HttpClient(); // 模拟登陆,按实际服务器端要求选用 Post 或 Get 请求方式 PostMethod postMethod = new PostMethod(loginUrl); // 设置登陆时要求的信息,用户名和密码 NameValuePair[] data = { new NameValuePair("username", "**"), new NameValuePair("password", "**") }; postMethod.setRequestBody(data);
try { // 设置 HttpClient 接收 Cookie,用与浏览器一样的策略 httpClient.getParams().setCookiePolicy(CookiePolicy.BROWSER_COMPATIBILITY); int statusCode = httpClient.executeMethod(postMethod); // 获得登陆后的 Cookie Cookie[] cookies = httpClient.getState().getCookies(); StringBuffer tmpcookies = new StringBuffer(); for (Cookie c : cookies) { tmpcookies.append(c.toString() + ";"); System.out.println("cookies = "+c.toString()); }
//登录后需要登录的网页
String loginUrl = "http://passport.mop.com/?targetUrl=http://hi.mop.com/?&g=1447141423230&loginCheck=UNLOGINED";if(statusCode==302){//重定向到新的URL System.out.println("模拟登录成功"); // 进行登陆后的操作 GetMethod getMethod = new GetMethod(dataUrl); // 每次访问需授权的网址时需带上前面的 cookie 作为通行证 getMethod.setRequestHeader("cookie", tmpcookies.toString()); // 你还可以通过 PostMethod/GetMethod 设置更多的请求后数据 // 例如,referer 从哪里来的,UA 像搜索引擎都会表名自己是谁,无良搜索引擎除外 postMethod.setRequestHeader("Referer", "http://passport.mop.com/"); postMethod.setRequestHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/31.0.1650.63 Safari/537.36"); httpClient.executeMethod(getMethod); // 打印出返回数据,检验一下是否成功 String text = getMethod.getResponseBodyAsString(); System.out.println(text); } else { System.out.println("登录失败"); } } catch (Exception e) { e.printStackTrace(); } } }
使用 httpClient 方式获得 cookie 后就可以使用 jsoup的API进行解析html操作,获取所需的信息;
方式二、使用jsoup自带的API方式
private static Integer TIMEOUT = 10000; private static String USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36"; private static String URL="登陆请求发送的url"; public static Map getLoginCookeis(){ try { //此处数据需要在页面上登陆页面,测试一下,获取登录时发送的登陆请求数据 Map map = new HashMap(); map.put("username", "用户名"); map.put("password", "密码");
Map map1 = new HashMap(); map1.put("ASPSESSIONIDASBTBDDT", "ACABMBFDKBGHOLHBHMKKMHLA"); map1.put("Sailing", "Skin="); map1.put("wwwkechengbiaonetjecas", "UserName=%D5%C5%C8%CB%C0%FB&AdminLoginCode=&AdminName=%D5%C5%C8%CB%C0%FB&LastPassword=v0rdu3g775Uqy735&UnreadMsg=&UserPassword=877b0591474be1fb&RndPassword=v0rdu3g775Uqy735&AdminPassword=877b0591474be1fb"); //发送登录请求 Connection.Response rs = Jsoup.connect(URL) .postDataCharset("GB2312")//编码格式 .data(map)//请求参数 .userAgent(USER_AGENT) .cookies(map1)//cookies .timeout(TIMEOUT)//超时 .method(Connection.Method.POST) .execute(); map1 = rs.cookies();//获取登录的cookies
//*** 获取到cookie后,后边就可以使用cookie进行二次登录,然后获取网页目的信息,进行爬取操作;
return map1; } catch (IOException ex) { Logger.getLogger(KechengbiaoLogin.class.getName()).log(Level.SEVERE, null, ex); return null; } }
贴一张详细代码图:
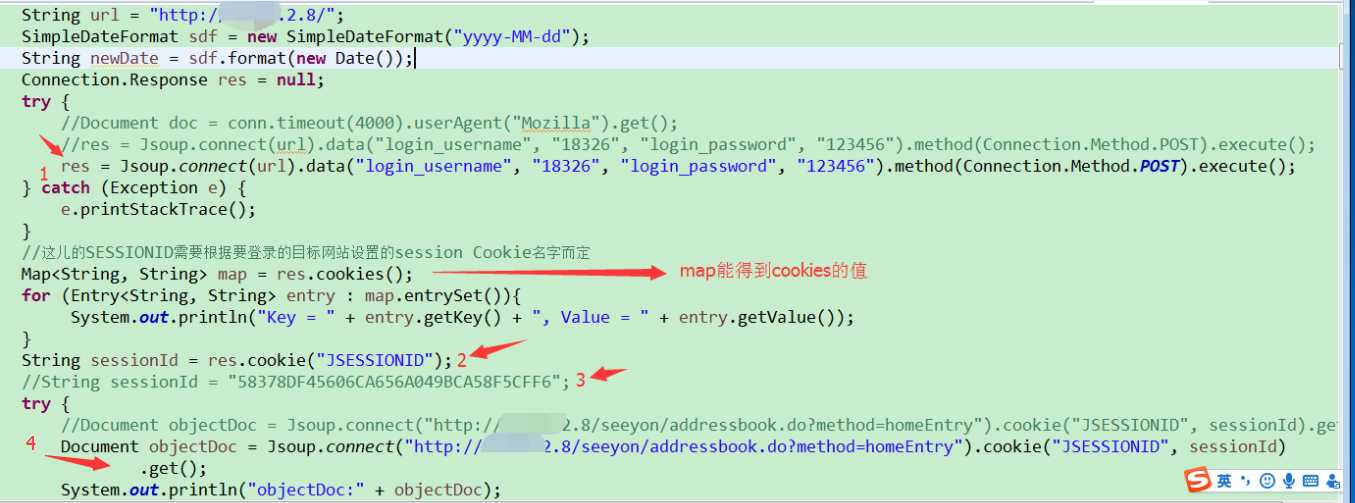
以上是关于网页爬虫小记:两种方式的爬取网站内容的主要内容,如果未能解决你的问题,请参考以下文章