FPGA构建人工神经网络系统应用实例——视障人士便携导航系统
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FPGA构建人工神经网络系统应用实例——视障人士便携导航系统相关的知识,希望对你有一定的参考价值。
现场可编程门阵列(FPGA)技术不断呈现增长势头, 2013年全球FPGA市场已经增长至35亿美元。 1984年Xilinx刚刚创造出FPGA时,它还是简单的胶合逻辑片,而如今在信号处理和控制应用中,它已经取代了自定制专用集成电路(ASIC)和处理器。今天来自北邮数据科学中心的杨阳来为大家解读如在使用FPGA构建人工神经网络系统。

以下为杨阳老师演讲实录
源起:使用FPGA搭建视障人士便携导航系统
在刚刚过去的第八届华为杯中国大学生智能设计竞赛,我们用PaddlePaddle来搭建一个人工神经网络放到我们自己的硬件平台里,实现了基于深度学习的视障人士便携导航系统,获得了二等奖。我们选择这个题目的原因,是考虑中国有大批的视障人群,这些视障人群在出行方面会遇到不少困难。我们传统的方式需要一些专门的人力、物力帮助视障人士出行,但是这种传统方式有一定的缺陷性,一般来说需要专人的陪同,另一方面,如果希望视障人士有很好的出行体验的话,我们需要很昂贵的导盲系统设备。
我们后来想到了应用FPGA加上深度学习的技术来设计一套完整的盲人的视障导航系统,本身FPGA进行深度学习的时候功耗特别低,小型化,而且速度也比较快。因此,我们的主要设计工作是分两部分:一部分是高层的PaddlePaddle深度学习算法设计,另一部分是关于底层的FPGA硬件设计。
首先我们通过大规模的行人出行指示图象,用PaddlePaddle进行大规模的训练,然后在PaddlePaddle里搭建一套深度学习神经网络,将这些深度神经网络的参数训练好之后写到FPGA里。
当时我们做了一个六层网络作为核心的单元,网络系数是通过PaddlePaddle对行人的指示标志图象训练获得,指示标志的样本我们采用了一个国外的实验室给的一个数据集,比赛的时间比较短,来不及自己采集,直接就用了一个别人的实验室给我的一个行人指示标志的图片,一共是3400张,这就是给一个例子,比如说这样的情况行人是允许通过的,因为前面可能有斑马线,这种情况可能是前面施工就禁止通行。
完成了算法设计,生成了参数,我们就想把这些参数烧录到硬件当中,形成具有实际功能的作品。我们的系统开发采用的是zynq7000系列,这个芯片有一个好处分为是它的下层是包括了传统的pl端,就是所谓普通LPG的逻辑电路,为我们整个发板带了一些丰富的外设提供了便利。比如说包括一些hdmi的口,USB2.0的口,因为我们盲人的摄像头采用USB2.0的摄像头。
图一 FPGA并行执行结构
zynq7000包括神经前馈网络模块、AXI直接存储器接入模块。用AXI这款芯片有一个好处,上层的AIM芯片和底层FPGA的逻辑是通过AXI总线直接连接。第三部分是实时图象的数据输入模块,还有一个侦提取模块。最核心的是这个,实现了一个将PaddlePaddle的参数直接导入进来以后的模块,我们采用的是vivado hls、opencl1.0的方式,现在的方式都支持高层,比如说你对C或者C++比较熟悉的时候就可以采用这个方式进行开发。我后面也会讲到如何利用高层语言进行一个转换,就避免了要重新去学习一些底层的繁琐的硬件代码。
采用深度前馈网络模块的好处是它可以使用层级模型,并发执行,统一内核。LPG里天然生成逻辑是有很多的计算单元,这些计算单元会划分成一个大块,它叫NDRange。NDRange可以进行一系列矩阵的运算,进行深度学习。训练完了之后将得到的深度神经网络可以让FPGA进行配套,这样很容易就可以把网络捎写到FPGA里,这样完成了矩阵的乘法。采用FPGA也是因为有并行的执行结构。
图二、数据的读入、处理显示以及输出过程流图
整个我们当时做的系统流程就是像这样的情况:首先我们要导入PaddlePaddle生成的网络参数,然后初始化深度的神经网络,接下来USB摄像头捕捉一些图象送到这个总线当中,接下来AXI直接读入数据,写入缓存,接下来就是FPGA处理数据,接下来是实时显示并输出,行人在路上走的时候可以实时看到图象,并且能够实时输出。
因为时间关系,我们当时只做在了显示器上。显示器会给出一个,信息显示你能否通行或者不能通行,实际上我们后续希望做出一个音频的给出一个信号,有一个声音提示行人。
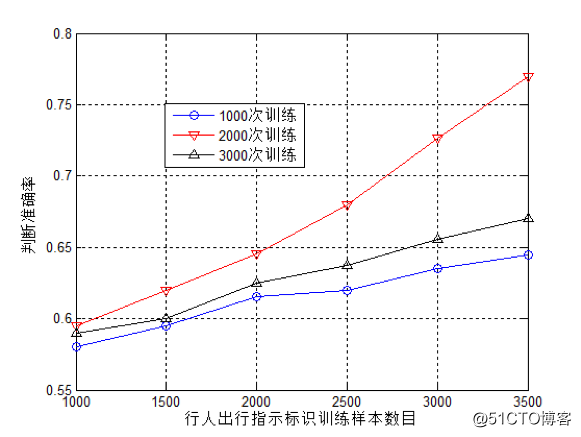
图三、行人指示标识图像训练样本数目vs. 判断准确率
参赛的时候训练集比较有限,我们采用的图片一共3400张,所以整个训练袭来,我们最高准确率也只达到了75%。深度学习进行行人指示能否通过和不通过本身是一个概率的事情,我们达到了最高是2000次训练的,实际上这条曲线3000次训练没有2000次训练好,因为3000次达到了一个过拟合的情况,所以反而没有2000次的好。但是总体趋势是这样,随着PaddlePaddle的训练图片数目的不断增大,准确率不断上升。如果我们后期加大数据集的话,可能准确率还会有所上升。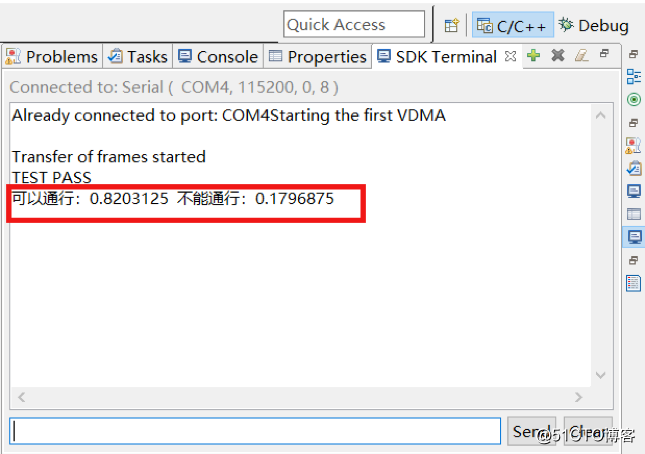
图四、单张行人指示标识图像判断结果示例
这个地方给出了一个单张行人指示标识的判断结果,最后判断出来的时候实际上是一个概率事件,你最后出来的时候,我们用的是一个什么,判断一下这个是0.8,我们认为比不能通行的概率大就可以通行。
FPGA的性能优势
使用FPGA,可以大大降低功耗,如果你把整个深度神经网络在GPU上或者CPU上实现,功耗会非常高,而用FPGA功耗最低可达1.725瓦。这两个参数我们测的时候是采用了看GPU实际运行中的额定功率,GPU功耗是比较大的。而且使用GPU识别的时候,不便于小型化,因为不可能背着GPU出去到处走。用FPGA功耗比较低是一个亮点,超低的功耗使得FPGA在续航和小型化方面优点比较明显,体积小是另一个亮点。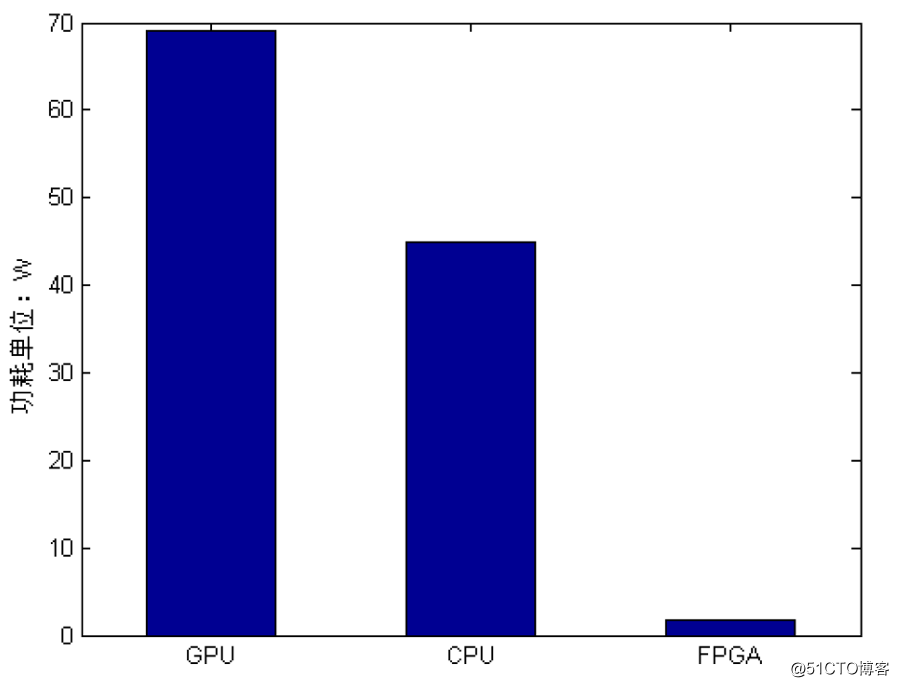
图五、GPU、CPU与FPGA功耗对比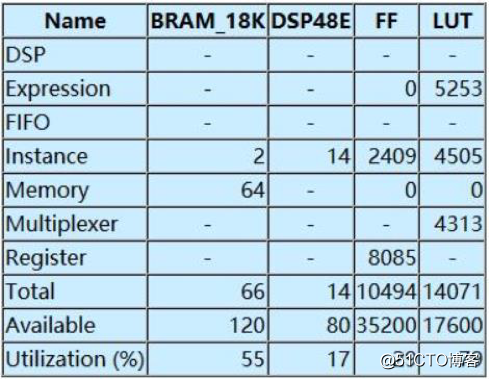
图六、系统资源占用情况
然后我们给出了一个资源占用情况分析,因为你在FPGA当中做的是定点数的计算,所以我们要对网络,因为你不管是PaddlePaddle生成出来的参数也好,你最后写入到FPGA的时候可能要考虑到从一个浮点数转到静点数。所以我们就要采点数,这和本身芯片设计有关系,芯片大小决定了你能放多大的深度神经网络,我们当时使用的是六层的神经网络,资源占用率是达到了79%,满足了芯片的要求,后期可以选择更大的FPGA的芯片。
FPGA的应用潜力
传统的深度学习框架很多都是跑在GPU和CPU上,对于FPGA目前为止好像还没有成熟的深度学习框架,在这个地方我希望通过一个抛砖引玉的思路给大家一个思路,如果大以后有兴趣可以在FPGA上实现深度学习框架。现在很多主流的厂商,他们都在做自己的一些想在自己的FPGA上搭自己的深度学习框架。
应用背景是随着大数据的爆发式增长,人工智能技术也得到了快速的发展,高性能计算的需求日益增长,可以看到像这样的数据中心,还有一些人工智能的判断,包括百度的阿波罗做无人驾驶这方面,我们在传统计算当中已经不能满足我们现在需要的这种计算的速度,所以我们需要用FPGA进行一个加速,传统芯片提升功耗比方面遇到了一个极大的挑战。
与计算平台的对比,实际上可以看到如果你采用传统的ASIC开发芯片,功耗是很低的,但是开发周期是非常长的,因为你要把所有的可能性想好之后做定制,定制需要的ASIC芯片。GPU开发周期短,性能也好,但是功耗太高了。FPGA介于这两者之间,开发周期较短,性能好,也比较适合做深度学习的计算,功耗特别低,所以一般来说我们可以考虑使用介于两者之间的FPGA进行一个开发。
深度学习分为两部分,首先第一部分是训练,第二部分是推断。训练这一部分是从已有的深度学习学习到新的能力,推断是将学习的新能源应用到新数据当中,比如说形成一个深度神经网络的话就可以捎入到需要的芯片当中。很多的深度学习框架都不支持FPGA,但是前段时间PaddlePaddle提供了一些支持FPGA的接口,所以大家有兴趣可以看一下提供的接口的链接:https://github.com/PaddlePaddle/paddle-mobile/tree/ca32dc7f40e75080d203b7de3cd1ae30feb612c9/src/operators/kernel/fpga。
这个地方我们希望PaddlePaddle可以做更好的支持,首先是支持FPGA上训练和推断,第二是优化FPGA的计算加速,训练模型在FPGA和CPU,GPU之间可以无缝对接,有了这样的深度学习框架可以在GPU上跑,可以在CPU上跑,也可以在FPGA上跑。
使用FPGA搭建CNN模型
如何在FPGA上面搭一个深度学习框架,我们当时采用的是xilinx的开发板,其实也可以采用其他的开发板,这个板子也挺贵的,两万三一个。当时采用的操作系统是centos,开发环境是vivado、SDX,上层是支持C的,在上层的时候可以用C或者C++进行开发,底层实际运行可以进行一个转换,效率上可能会低一些,但是会加速你的开发的周期,这样的话可以用上层的语言。首先通过我们的主机端,通过板子构成一整个的深度学习框架的开发的硬件环境,他有一些包括里面的PCl-e的控制器,整个框架支持C++和Opencl的开发,有了这样的硬件环境对于你后期想在这上面部署一个深度学习框架其实是有好处的。
框架是如何实现,这是一个自己向上的设计和思路,我们分了几部分,第一部分blob,进行封装数据的读写。第二部分采用layer,把封装好的数据利用blob进行不同功能的具体计算,接下来用net进行组合,就是把所有的每一个层进行串起来,串起来之后把每一个层组合神经网络,最后有一个solve控制神经网络的流程。
设备端可以做一个优化,实际上FPGA比较适合来做定点数的,浮点数对于FPGA来说不是一个特别有优势的功能,我们的定点数实际上位宽比较少,节省资源。第二个是整型的数据,利于硬件的运算,这儿给出了一个例子,当然这个例子其实在网上大家也可以看到很多定点数和浮点数的转换。
最后你可以看到精度损失是比较小的,一般是可以忽略的。实际上最后也给出了一个引证,我们在FPGA上,如果想去搭深度学习框架,如果采用定点数,实际上是有一定的可能性的。我们当时比较了一下,进行一次两次的加法,乘法节省的时间分别达到40%和29%,所以从这个图上可以看到32位单精度浮点数,我们的定点数位宽Q=11的时候可以节省相应的资源。同时我们用了手写数字的数据集运行了一下数据集,如果在FPGA上搭这样的一个深度学习的框架,其实你可以看到定点和浮点这两个准确率几乎可以达到一致。
其实FPGA里还有一个很好的特色就是有一个pipeline,就是所谓的流水线,用定点数据依赖,增加算法硬件实现的并行性的数字设计方法,用串型的计算,比如说8个周期进行传统的计算的时候,比如说8个周期是一个串型的计算,利用这个流水线把每个单元进行并行化,实际上可以看到采用更少的时间周期可以进行并行的计算,可以大大降低逻辑资源。
实录结束
杨阳
2015年博士毕业于北京邮电大学信息与通信工程学院,同年进入清华大学电子系从事博士后研究工作,目前就职于北京邮电大学,任职讲师,研究兴趣方向为人工智能、智能硬件与通信网络,国家自然科学基金青年基金获得者,中国博士后科学基金面上项目获得者,发表SCI期刊论文6篇,EI期刊17篇,申请国际专利3项,国内专利4项,参与国家国家重大专项项目一项。指导留学生3名,硕士研究生四名并获得国家级学科竞赛奖励四项。
以上是关于FPGA构建人工神经网络系统应用实例——视障人士便携导航系统的主要内容,如果未能解决你的问题,请参考以下文章