[转] RISC-V架构介绍
Posted hwbeta
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[转] RISC-V架构介绍相关的知识,希望对你有一定的参考价值。
1. RISC-V和其他开放架构有何不同
如果仅从“免费”或“开放”这两点来评判,RISC-V架构并不是第一个做到免费或开放的处理器架构。
在开始之前,我们先通过论述几个具有代表性的开放架构,来分析RISC-V架构的不同之处以及为什么其他开放架构没能取得足够的成功。
平民英雄——OpenRISC
OpenRISC是OpenCores组织提供的基于GPL协议的开放源代码RISC处理器。
OpenRISC具有以下特点:
OpenRISC被应用到很多公司的项目之中。可以说,OpenRISC是应用非常广泛的一种开源处理器实现。
OpenRISC的不足之处在于其侧重于实现一种开源的CPU Core,而非立足于定义一种开放的指令集架构,因此其架构的发展不够完整,指令集的定义也不具备上节中提到的RISC-V架构的优点,更加没有上升到成立专门的基金会组织的高度。OpenRISC更多的时候被认为是一个开源的Core,而非一种优美的指令集架构。此外,OpenRISC的许可证为GPL,这意味着所有的指令集改动都必须开源(而RISC-V则无此约束)。
豪门显贵——SPARC
SPARC架构作为经典的RISC微处理器架构之一,SPARC最早于1985年由Sun电脑所设计。SPARC也是SPARC国际公司的注册商标之一,这家公司于1989年成立,目的是向外界推广SPARC架构以及为该架构进行兼容性测试。该公司为了推广SPARC的生态系统,SPARC国际公司将标准开放,并授权予多家生产商采用,包括德州仪器、Cypress半导体和富士通等。由于SPARC架构也对外完全开放,因此,也出现了完全开放源码的LEON处理器。不仅如此,Sun公司还于1994年推动SPARC v8架构成为IEEE标准(IEEE Standard 1754-1994)。
由于SPARC架构的初衷是面向服务器领域而设计,其最大的特点是拥有一个大型的寄存器窗口,符合SPARC架构的处理器需要实现从72到640个之多的通用寄存器,每个寄存器宽度为64bits,组成一系列的寄存器组,称之为寄存器窗口。
这种寄存器窗口的架构,由于可以切换不同的寄存器组快速地响应函数调用与返回,因此,能够产生非常高的性能,但是这种架构由于功耗面积代价太大,而并不适用于PC与嵌入式领域处理器。而SPARC架构也不具备模块化的特点,使得用户无法裁剪和选择。很难作为一种通用的处理器架构对商用的x86和ARM架构形成替代。
设计这种超大服务器CPU芯片又非普通公司与个人所能涉足,而有能力设计这种大型CPU的公司也没有必要投入巨大的成本来挑战x86的统治地位。随着Sun公司的衰弱,SPARC架构现在基本上退出了人们的视野。感兴趣的读者请在网络上自行搜索文章《再见SPARC处理器,再见Sun》
名校优生——RISC-V
关于RISC-V在伯克利大学诞生的经历,本节在此不做重复赘述。
因为多年来在CPU领域已经出现过多个免费或开放的架构,很多高校也在科研项目中推出过多种指令集架构。因此,当笔者第一次听说RISC-V之时,以为又是一个玩具,或纯粹学术性质的科研项目而不以为意。
直到笔者亲自通读了一遍RISC-V的架构文档,不禁为其先进的设计理念所折服。同时,RISC-V架构的各种优点也得到了众多专业人士的青睐好评和众多商业公司的相继加盟。并且2016年RISC-V基金会的正式启动在业界引起了不小的影响。如此种种,使得RISC-V成为至今为止最具备革命性意义的开放处理器架构。
2. 简单就是美——RISC-V架构的设计哲学
RISC-V架构作为一种指令集架构,在介绍细节之前,让我们先了解设计的哲学。所谓设计的“哲学”便是其推崇的一种策略,譬如说我们熟知的日本车的设计哲学是经济省油,美国车的设计哲学是霸气外漏等。RISC-V架构的设计哲学是什么呢?是“大道至简”。
笔者最为推崇的一种设计原则便是:简单就是美,简单便意味着可靠。无数的实际案例已经佐证了“简单即意味着可靠的”真理,反之越复杂的机器越则越容易出错。
所谓大道至简,在IC设计的实际工作中,笔者曾见过最简洁的设计实现安全可靠,也曾见过最繁复的设计长时间无法稳定收敛。最简洁的设计往往是最可靠的,在大多数的项目实践中一次次的得到检验。
IC设计的工作性质非常特殊,其最终的产出是芯片,而一款芯片的设计和制造周期均很长,无法像软件代码那样轻易的升级和打补丁,每一次芯片的改版到交付都需要几个月的周期。不仅如此,芯片的一次制造成本费用高昂,从几十万美金到百千万美金不等。这些特性都决定了IC设计的试错成本极为高昂,因此能够有效的降低错误的发生就显得非常的重要。
现代的芯片设计规模越来越大,复杂度越来越高,并不是说要求设计者一味的逃避使用复杂的技术,而是应该将好钢用在刀刃上,将最复杂的设计用在最为关键的场景,在大多数有选择的情况下,尽量选择简洁的实现方案。
笔者在第一次阅读了RISC-V架构文档之时,不禁击节赞叹,拍案惊奇,因为RISC-V架构在其文档中不断地明确强调,其设计哲学是“大道至简”,力图通过架构的定义使得硬件的实现足够简单。其简单就是美的哲学,可以从几个方面容易看出,后续小节将一一加以论述。
无病一身轻——架构的篇幅
在处理器领域,目前主流的架构为x86与ARM架构,笔者曾经参与设计ARM架构的应用处理器,因此需要阅读ARM的架构文档,如果对其熟悉的读者应该了解其篇幅。经过几十年的发展,现代的x86与ARM架构的架构文档长达几百数千页。打印出来能有半个桌子高,可真是“著作等身”。
之所以现代x86与ARM架构的文档长达数千页,且版本众多,一个主要的原因是因为其架构的发展的过程也伴随了现代处理器架构技术的不断发展成熟。
并且作为商用的架构,为了能够保持架构的向后兼容性,其不得不保留许多过时的定义,或者在定义新的架构部分时为了能够将就已经存在的技术部分而显得非常的别扭。久而久之就变得极为冗长。
那么现代成熟的架构是否能够选择重新开始,重新定义一个简洁的架构呢,可以说是几乎不可能。其中一个重要的原因便是其无法向前兼容,从而无法得到用户的接受。试想一下如果我们买了一款新的搭配新的处理器的电脑或者手机回家,之前所有的软件都无法运行而变砖,那肯定是无法让人接受的。
而现在才推出的RISC-V架构,则具备了后发优势,由于计算机体系结构经过多年的发展已经成为比较成熟的技术,多年来在不断成熟的过程中暴露的问题都已经被研究透彻,因此新的RISC-V架构能够加以规避,并且没有背负向后兼容的历史包袱,可以说是无病一身轻。
目前的“RISC-V架构文档”分为“指令集文档”(riscv-spec-v2.2.pdf)和“特权架构文档”(riscv-privileged-v1.10.pdf)。“指令集文档”的篇幅为145页,而“特权架构文档”的篇幅也仅为91页。熟悉体系结构的工程师仅需一至两天便可将其通读,虽然“RISC-V的架构文档”还在不断地丰富,但是相比“x86的架构文档”与“ARM的架构文档”,RISC-V的篇幅可以说是极其短小精悍。
感兴趣的读者可以在RISC-V基金会的网站上(https://riscv.org/specifications/)无需注册便可免费下载其文档,如图1所示。
图1 RISC-V基金会网站上的架构文档
能屈能伸——模块化的指令集
RISC-V架构相比其他成熟的商业架构的最大一个不同还在于它是一个模块化的架构。因此,RISC-V架构不仅短小精悍,而且其不同的部分还能以模块化的方式组织在一起,从而试图通过一套统一的架构满足各种不同的应用。
这种模块化是x86与ARM架构所不具备的。以ARM的架构为例,ARM的架构分为A、R和M三个系列,分别针对于Application(应用操作系统)、Real-Time(实时)和Embedded(嵌入式)三个领域,彼此之间并不兼容。
但是模块化的RISC-V架构能够使得用户能够灵活选择不同的模块组合,以满足不同的应用场景,可以说是“老少咸宜”。譬如针对于小面积低功耗嵌入式场景,用户可以选择RV32IC组合的指令集,仅使用Machine Mode(机器模式);而高性能应用操作系统场景则可以选择譬如RV32IMFDC的指令集,使用Machine Mode(机器模式)与User Mode(用户模式)两种模式。而他们共同的部分则可以相互兼容。
浓缩的都是精华——指令的数量
短小精悍的架构以及模块化的哲学,使得RISC-V架构的指令数目非常的简洁。基本的RISC-V指令数目仅有40多条,加上其他的模块化扩展指令总共几十条指令。
3. RISC-V指令集架构简介
本章将对RISC-V的指令集架构多方面的特性进行简要介绍。
模块化的指令子集
RISC-V的指令集使用模块化的方式进行组织,每一个模块使用一个英文字母来表示。RISC-V最基本也是唯一强制要求实现的指令集部分是由I字母表示的基本整数指令子集,使用该整数指令子集,便能够实现完整的软件编译器。其他的指令子集部分均为可选的模块,具有代表性的模块包括M/A/F/D/C,如表1所示。
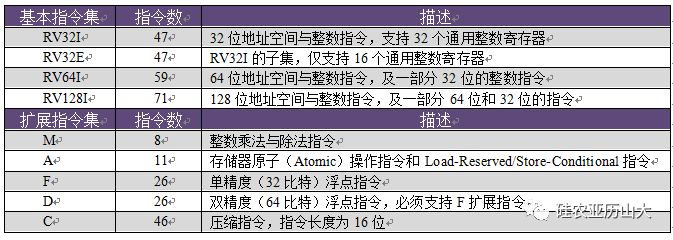
表1 RISC-V的模块化指令集
为了提高代码密度,RISC-V架构也提供可选的“压缩”指令子集,由英文字母C表示。压缩指令的指令编码长度为16比特,而普通的非压缩指令的长度为32比特。以上这些模块的一个特定组合“IMAFD”,也被称为“通用”组合,由英文字母G表示。因此RV32G表示RV32IMAFD,同理RV64G表示RV64IMAFD。
为了进一步减少面积,RISC-V架构还提供一种“嵌入式”架构,由英文字母E表示。该架构主要用于追求极低面积与功耗的深嵌入式场景。该架构仅需要支持16个通用整数寄存器,而非嵌入式的普通架构则需要支持32个通用整数寄存器。
通过以上的模块化指令集,能够选择不同的组合来满足不同的应用。譬如,追求小面积低功耗的嵌入式场景可以选择使用RV32EC架构;而大型的64位架构则可以选择RV64G。
除了上述的模块,还有若干的模块包括L、B、P、V和T等。这些扩展目前大多数还在不断完善和定义中,尚未最终确定,因此本文在此不做详细论述。
可配置的通用寄存器组
RISC-V架构支持32位或者64位的架构,32位架构由RV32表示,其每个通用寄存器的宽度为32比特;64位架构由RV64表示,其每个通用寄存器的宽度为64比特。
RISC-V架构的整数通用寄存器组,包含32个(I架构)或者16个(E架构)通用整数寄存器,其中整数寄存器0被预留为常数0,其他的31个(I架构)或者15个(E架构)为普通的通用整数寄存器。
如果使用了浮点模块(F或者D),则需要另外一个独立的浮点寄存器组,包含32个通用浮点寄存器。如果仅使用F模块的浮点指令子集,则每个通用浮点寄存器的宽度为32比特;如果使用了D模块的浮点指令子集,则每个通用浮点寄存器的宽度为64比特。
规整的指令编码
在流水线中能够尽早尽快的读取通用寄存器组,往往是处理器流水线设计的期望之一,这样可以提高处理器性能和优化时序。这个看似简单的道理在很多现存的商用RISC架构中都难以实现,因为经过多年反复修改不断添加新指令后,其指令编码中的寄存器索引位置变得非常的凌乱,给译码器造成了负担。
得益于后发优势和总结了多年来处理器发展的教训,RISC-V的指令集编码非常的规整,指令所需的通用寄存器的索引(Index)都被放在固定的位置,如图2所示。因此指令译码器(Instruction Decoder)可以非常便捷的译码出寄存器索引然后读取通用寄存器组(Register File,Regfile)。
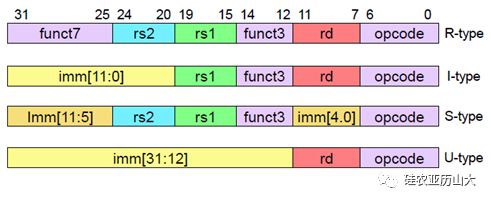
图2 RV32I规整的指令编码格式
简洁的存储器访问指令
与所有的RISC处理器架构一样,RISC-V架构使用专用的存储器读(Load)指令和存储器写(Store)指令访问存储器(Memory),其他的普通指令无法访问存储器,这种架构是RISC架构的常用的一个基本策略,这种策略使得处理器核的硬件设计变得简单。
存储器访问的基本单位是字节(Byte)。RISC-V的存储器读和存储器写指令支持一个字节(8位),半字(16位),单字(32位)为单位的存储器读写操作,如果是64位架构还可以支持一个双字(64位)为单位的存储器读写操作。
RISC-V架构的存储器访问指令还有如下显著特点:
为了提高存储器读写的性能,RISC-V架构推荐使用地址对齐的存储器读写操作,但是地址非对齐的存储器操作RISC-V架构也支持,处理器可以选择用硬件来支持,也可以选择用软件来支持。
由于现在的主流应用是小端格式(Little-Endian),RISC-V架构仅支持小端格式。有关小端格式和大端格式的定义和区别,本文在此不做过多介绍,若对此不甚了解的初学者可以自行查阅学习。
很多的RISC处理器都支持地址自增或者自减模式,这种自增或者自减的模式虽然能够提高处理器访问连续存储器地址区间的性能,但是也增加了设计处理器的难度。RISC-V架构的存储器读和存储器写指令不支持地址自增自减的模式。
RISC-V架构采用松散存储器模型(Relaxed Memory Model),松散存储器模型对于访问不同地址的存储器读写指令的执行顺序不作要求,除非使用明确的存储器屏障(Fence)指令加以屏蔽。
这些选择都清楚地反映了RISC-V架构力图简化基本指令集,从而简化硬件设计的哲学。RISC-V架构如此定义非常合理,能够达到能屈能伸的效果。譬如:对于低功耗的简单CPU,可以使用非常简单的硬件电路即可完成设计;而对于追求高性能的超标量处理器则可以通过复杂设计的动态硬件调度能力来提高性能。
高效的分支跳转指令
RISC-V架构有两条无条件跳转指令(Unconditional Jump),jal与jalr指令。跳转链接(Jump and Link)指令jal可用于进行子程序调用,同时将子程序返回地址存在链接寄存器(Link Register:由某一个通用整数寄存器担任)中。跳转链接寄存器(Jump and Link-Register)指令jalr指令能够用于子程序返回指令,通过将jal指令(跳转进入子程序)保存的链接寄存器用于jalr指令的基地址寄存器,则可以从子程序返回。
RISC-V架构有6条带条件跳转指令(Conditional Branch),这种带条件的跳转指令跟普通的运算指令一样直接使用2个整数操作数,然后对其进行比较,如果比较的条件满足时,则进行跳转。因此,此类指令将比较与跳转两个操作放到了一条指令里完成。
作为比较,很多的其他RISC架构的处理器需要使用两条独立的指令。第一条指令先使用比较指令,比较的结果被保存到状态寄存器之中;第二条指令使用跳转指令,判断前一条指令保存在状态寄存器当中的比较结果为真时则进行跳转。相比而言RISC-V的这种带条件跳转指令不仅减少了指令的条数,同时硬件设计上更加简单。
对于没有配备硬件分支预测器的低端CPU,为了保证其性能,RISC-V的架构明确要求其采用默认的静态分支预测机制,即:如果是向后跳转的条件跳转指令,则预测为“跳”;如果是向前跳转的条件跳转指令,则预测为“不跳”,并且RISC-V架构要求编译器也按照这种默认的静态分支预测机制来编译生成汇编代码,从而让低端的CPU也能得到不错的性能。
为了使硬件设计尽量简单,RISC-V架构特地定义了所有的带条件跳转指令跳转目标的偏移量(相对于当前指令的地址)都是有符号数,并且其符号位被编码在固定的位置。因此,这种静态预测机制在硬件上非常容易实现,硬件译码器可以轻松的找到这个固定的位置,并判断其是0还是1来判断其是正数还是负数,如果是负数则表示跳转的目标地址为当前地址减去偏移量,也就是向后跳转,则预测为“跳”。当然对于配备有硬件分支预测器的高端CPU,则可以采用高级的动态分支预测机制来保证性能。
简洁的子程序调用
为了理解此节,需先对一般RISC架构中程序调用子函数的过程予以介绍,其过程如下:
- 进入子函数之后需要用存储器写(Store)指令来将当前的上下文(通用寄存器等的值)保存到系统存储器的堆栈区内,这个过程通常称为“保存现场”。
- 在退出子程序之时,需要用存储器读(Load)指令来将之前保存的上下文(通用寄存器等的值)从系统存储器的堆栈区读出来,这个过程通常称为“恢复现场”。
“保存现场”和“恢复现场”的过程通常由编译器编译生成的指令来完成,使用高层语言(譬如C或者C++)开发的开发者对此可以不用太关心。高层语言的程序中直接写上一个子函数调用即可,但是这个底层发生的“保存现场”和“恢复现场”的过程却是实实在在地发生着(可以从编译出的汇编语言里面看到那些“保存现场”和“恢复现场”的汇编指令),并且还需要消耗若干的CPU执行时间。
为了加速这个“保存现场”和“恢复现场”的过程,有的RISC架构发明了一次写多个寄存器到存储器中(Store Multiple),或者一次从存储器中读多个寄存器出来(Load Multiple)的指令,此类指令的好处是一条指令就可以完成很多事情,从而减少汇编指令的代码量,节省代码的空间大小。但是此种“Load Multiple”和“Store Multiple”的弊端是会让CPU的硬件设计变得复杂,增加硬件的开销,也可能损伤时序使得CPU的主频无法提高,笔者在曾经设计此类处理器时便深受其苦。
RISC-V架构则放弃使用这种“Load Multiple”和“Store Multiple”指令。并解释,如果有的场合比较介意这种“保存现场”和“恢复现场”的指令条数,那么可以使用公用的程序库(专门用于保存和恢复现场)来进行,这样就可以省掉在每个子函数调用的过程中都放置数目不等的“保存现场”和“恢复现场”的指令。
此选择再次印证了RISC-V追求硬件简单的哲学,因为放弃“Load Multiple”和“Store Multiple”指令可以大幅简化CPU的硬件设计,对于低功耗小面积的CPU可以选择非常简单的电路进行实现,而高性能超标量处理器由于硬件动态调度能力很强,可以有强大的分支预测电路保证CPU能够快速的跳转执行,从而可以选择使用公用的程序库(专门用于保存和恢复现场)的方式减少代码量,但是同时达到高性能。
无条件码执行
很多早期的RISC架构发明了带条件码的指令,譬如在指令编码的头几位表示的是条件码(Conditional Code),只有该条件码对应的条件为真时,该指令才被真正执行。
这种将条件码编码到指令中的形式可以使得编译器将短小的循环编译成带条件码的指令,而不用编译成分支跳转指令。这样便减少了分支跳转的出现,一方面减少了指令的数目;另一方面也避免了分支跳转带来的性能损失。然而,这种“条件码”指令的弊端同样会使得CPU的硬件设计变得复杂,增加硬件的开销,也可能损伤时序使得CPU的主频无法提高,笔者在曾经设计此类处理器时便深受其苦。
RISC-V架构则放弃使用这种带“条件码”指令的方式,对于任何的条件判断都使用普通的带条件分支跳转指令。此选择再次印证了RISC-V追求硬件简单的哲学,因为放弃带“条件码”指令的方式可以大幅简化CPU的硬件设计,对于低功耗小面积的CPU可以选择非常简单的电路进行实现,而高性能超标量处理器由于硬件动态调度能力很强,可以有强大的分支预测电路保证CPU能够快速的跳转执行达到高性能。
无分支延迟槽
很多早期的RISC架构均使用了“分支延迟槽(Delay Slot)”,最具有代表性的便是MIPS架构,在很多经典的计算机体系结构教材中,均使用MIPS对分支延迟槽进行过介绍。分支延迟槽就是指在每一条分支指令后面紧跟的一条或者若干条指令不受分支跳转的影响,不管分支是否跳转,这后面的几条指令都一定会被执行。
早期的RISC架构很多采用了分支延迟槽诞生的原因主要是因为当时的处理器流水线比较简单,没有使用高级的硬件动态分支预测器,所以使用分支延迟槽能够取得可观的性能效果。然而,这种分支延迟槽使得CPU的硬件设计变得极为的别扭,CPU设计人员对此往往苦不堪言。
RISC-V架构则放弃了分支延迟槽,再次印证了RISC-V力图简化硬件的哲学,因为现代的高性能处理器的分支预测算法精度已经非常高,可以有强大的分支预测电路保证CPU能够准确的预测跳转执行达到高性能。而对于低功耗小面积的CPU,由于无需支持分支延迟槽,硬件得到极大简化,也能进一步减少功耗和提高时序。
无零开销硬件循环
很多RISC架构还支持零开销硬件循环(Zero Overhead Hardware Loop)指令,其思想是通过硬件的直接参与,通过设置某些循环次数寄存器(Loop Count),然后可以让程序自动地进行循环,每一次循环则Loop Count自动减1,这样持续循环直到Loop Count的值变成0,则退出循环。
之所以提出发明这种硬件协助的零开销循环是因为在软件代码中的for 循环(for i=0; i<="" p=""></N;>
然有得必有失,此类零开销硬件循环指令大幅地增加了硬件设计的复杂度。因此,零开销循环指令与RISC-V架构简化硬件的哲学是完全相反的,在RISC-V架构中自然没有使用此类零开销硬件循环指令。
简洁的运算指令
在本章第2.1节中曾经提到RISC-V架构使用模块化的方式组织不同的指令子集,最基本的整数指令子集(I字母表示)支持的运算包括加法、减法、移位、按位逻辑操作和比较操作。这些基本的运算操作能够通过组合或者函数库的方式完成更多的复杂操作(譬如乘除法和浮点操作),从而能够完成大多数的软件操作。
整数乘除法指令子集(M字母表示)支持的运算包括,有符号或者无符号的乘法和除法操作。乘法操作能够支持两个32位的整数相乘得到一个64位的结果;除法操作能够支持两个32位的整数相除得到一个32位的商与32位的余数。
单精度浮点指令子集(F字母表示)与双精度浮点指令子集(D字母表示)支持的运算包括浮点加减法,乘除法,乘累加,开平方根和比较等操作,同时提供整数与浮点,单精度与双精度浮点彼此之间的格式转换操作。
很多RISC架构的处理器在运算指令产生错误之时,譬如上溢(Overflow)、下溢(Underflow)、非规格化浮点数(Subnormal)和除零(Divide by Zero),都会产生软件异常。RISC-V架构的一个特殊之处是对任何的运算指令错误(包括整数与浮点指令)均不产生异常,而是产生某个特殊的默认值,同时,设置某些状态寄存器的状态位。RISC-V架构推荐软件通过其他方法来找到这些错误。再次清楚地反映了RISC-V架构力图简化基本的指令集,从而简化硬件设计的哲学。
优雅的压缩指令子集
基本的RISC-V基本整数指令子集(字母I表示 )规定的指令长度均为等长的32位,这种等长指令定义使得仅支持整数指令子集的基本RISC-V CPU非常容易设计。但是等长的32位编码指令也会造成代码体积(Code Size)相对较大的问题。
为了满足某些对于代码体积要求较高的场景(譬如嵌入式领域),RISC-V定义了一种可选的压缩(Compressed)指令子集,由字母C表示,也可以由RVC表示。RISC-V具有后发优势,从一开始便规划了压缩指令,预留了足够的编码空间,16位长指令与普通的32位长指令可以无缝自由地交织在一起,处理器也没有定义额外的状态。
RISC-V压缩指令的另外一个特别之处是,16位指令的压缩策略是将一部分普通最常用的的32位指令中的信息进行压缩重排得到(譬如假设一条指令使用了两个同样的操作数索引,则可以省去其中一个索引的编码空间),因此每一条16位长的指令都能一一找到其对应的原始32位指令。因此,程序编译成为压缩指令仅在汇编器阶段就可以完成,极大的简化了编译器工具链的负担。
RISC-V架构的研究者进行了详细的代码体积分析,如图3所示,通过分析结果可以看出,RV32C的代码体积相比RV32的代码体积减少了百分之四十,并且与ARM,MIPS和x86等架构相比都有不错的表现。
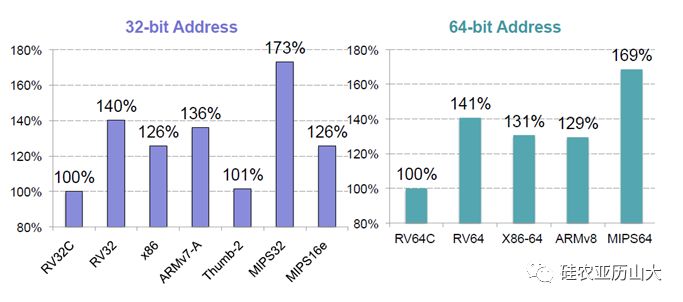
图3 各指令集架构的代码密度比较(数据越小越好)
特权模式
RISC-V架构定义了三种工作模式,又称特权模式(Privileged Mode):
- Machine Mode:机器模式,简称M Mode。
- Supervisor Mode:监督模式,简称S Mode。
- User Mode:用户模式,简称U Mode。
RISC-V架构定义M Mode为必选模式,另外两种为可选模式。通过不同的模式组合可以实现不同的系统。
RISC-V架构也支持几种不同的存储器地址管理机制,包括对于物理地址和虚拟地址的管理机制,使得RISC-V架构能够支持从简单的嵌入式系统(直接操作物理地址)到复杂的操作系统(直接操作虚拟地址)的各种系统。
CSR寄存器
RISC-V架构定义了一些控制和状态寄存器(Control and Status Register,CSR),用于配置或记录一些运行的状态。CSR寄存器是处理器核内部的寄存器,使用其自己的地址编码空间和存储器寻址的地址区间完全无关系。
CSR寄存器的访问采用专用的CSR指令,包括CSRRW、CSRRS、CSRRC、CSRRWI、CSRRSI以及CSRRCI指令。
中断和异常
中断和异常机制往往是处理器指令集架构中最为复杂而关键的部分。RISC-V架构定义了一套相对简单基本的中断和异常机制,但是也允许用户对其进行定制和扩展。
矢量指令子集
RISC-V架构目前虽然还没有定型矢量(Vector)指令子集,但是从目前的草案中已经可以看出,RISC-V矢量指令子集的设计理念非常的先进,由于后发优势及借助矢量架构多年发展成熟的结论,RISC-V架构将使用可变长度的矢量,而不是矢量定长的SIMD指令集(譬如ARM的NEON和Intel的MMX),从而能够灵活的支持不同的实现。追求低功耗小面积的CPU可以选择使用长度较短的硬件矢量进行实现,而高性能的CPU则可以选择较长的硬件矢量进行实现,并且同样的软件代码能够彼此兼容。
自定制指令扩展
除了上述阐述的模块化指令子集的可扩展、可选择,RISC-V架构还有一个非常重要的特性,那就是支持第三方的扩展。用户可以扩展自己的指令子集,RISC-V预留了大量的指令编码空间用于用户的自定义扩展,同时,还定义了四条Custom指令可供用户直接使用,每条Custom指令都有几个比特位的子编码空间预留,因此,用户可以直接使用四条Custom指令扩展出几十条自定义的指令。
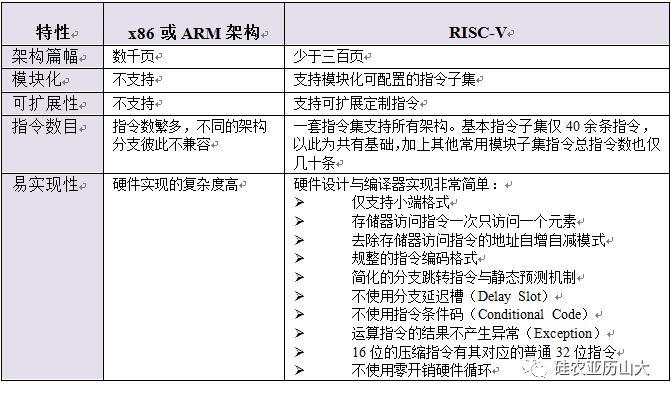
总结与比较
处理器设计技术经过几十年的衍进,随着大规模集成电路设计技术的发展直至今天,呈现出如下特点:
- 由于高性能处理器的硬件调度能力已经非常强劲且主频很高,因此,硬件设计希望指令集尽可能的规整、简单,从而,使得处理器可以设计出更高的主频与更低的面积。
- 以IoT应用为主的极低功耗处理器更加苛求低功耗与低面积。
- 存储器的资源也比早期的RISC处理器更加丰富。
如上种种这些因素,使得很多早期的RISC架构设计理念(依据当时技术背景而诞生),时至今日不仅不能帮助现代处理器设计,反而成了负担桎梏。某些早期RISC架构定义的特性,一方面使得高性能处理器的硬件设计束手束脚;另一方面又使得极低功耗的处理器硬件设计背负不必要的复杂度。
得益于后发优势,全新的RISC-V架构能够规避所有这些已知的负担,同时,利用其先进的设计哲学,设计出一套“现代”的指令集。本节再次将其特点总结如表2所示。
表2 RISC-V指令集架构特点总结
以上是关于[转] RISC-V架构介绍的主要内容,如果未能解决你的问题,请参考以下文章