廖雪峰Python总结1
Posted pythonlearing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了廖雪峰Python总结1相关的知识,希望对你有一定的参考价值。
1.输入输出
输入?
2.文本编辑器中,需要把Tab键自动转换为四个空格,确保不混用Tab和空格。
3.数据类型和变量
1.整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(包括除法),而浮点数运算则可能会有四舍五入的误差。
2.字符串内部既包含‘又包含"的话,可以用转义字符来标识。可以用r来表示字符串不用转义
‘I‘m "OK"!‘ #表示的字符串是: I‘m "OK"!
3.如果字符串内部有很多换行,用 写在一行不好阅读,为了简化,Python允许用‘‘‘..‘‘‘的格式表示多行内容,例如:
print(‘‘‘Line1 ...Line2 ...Line3‘‘‘) # Line1 Line2 Line3
4.空值是python中特殊的值,用None表示,None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
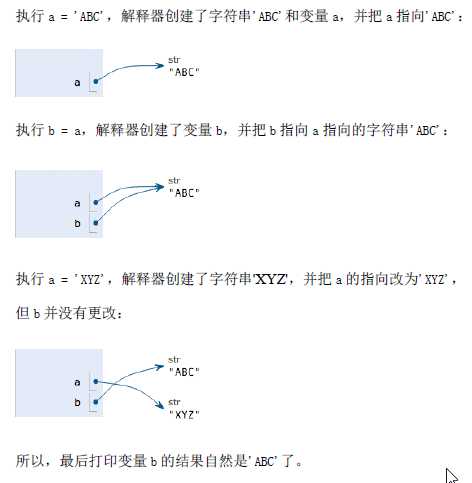
5.变量的赋值
6.除法运算
- 10/3:
- 10//3:整除,两个整数的除法任然是整数(只取除法的整数部分)
7.python的整数没有大小限制,浮点数也没有大小限制,但是超出一定范围就表示为Inf
4.字符串和编码
- 在计算机内存中,统一使用Unicode编码,当需要保就存到硬盘或者需要传输时,就换成UTF-8编码
- 用记事本编辑的时候,从文件读取的UTF-8字符被转换成Unicode字符到内存里,编辑完成后,保存的时候再把Unicode编码转换为UTF-8保存到文件
- 浏览网页时,服务器会动态的把生成的Unicode内存转换为UTF-8在传输到浏览器
由于Python源代码也是一个文本文件,所以当源代码中包含中文时,在保存源代码是,就需要务必指定UTF-8编码,当Python解释器读取源码时,为了让它按照UTF-8编码读取,通常在开头写上这两行:

第一行注释是为了告诉LInux/OS X系统,这是一个Python可执行文件,Windows系统会忽略这个注释。
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则你在源代码中写的中文输出可能会有乱码
5.“可变”的tuple
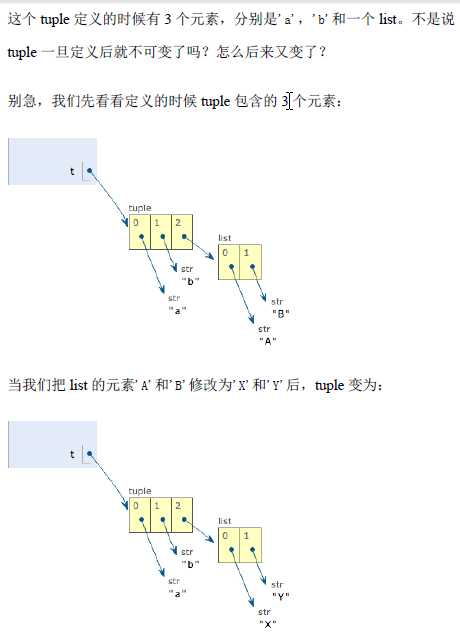
表面上看,tuple的元素确实变了,当其实变得不是tuple的元素,而是list的元素,tuple一开始指向的list并没有改成别的list,所以tuple所谓的“不变”是说:tuple中的每个元素,指向永远不变,指向一个list就不能之下你其他对象,但是指向的这个list本身是可变的。
6.str是不可变对象

7.函数参数
必选参数在前,变化大的参数放在前面,变化小的参数放在后面,变化小的参数就可以作为默认参数。
默认参数必须指向不可变对象:




此外,当多任务环境下同时读取对象不需要加锁,同时读取一点问题都没有,我们在编程时,如果可以设计一个不变对象,就尽量设计成不变对象。
可变参数:
定义可变参数和定义一个list或tuple相比,仅仅在参数面前加了一个*号。在函数内部,参数接收到的是一个tuple,因此,函数代码不变,但是调用该函数时可以传入任意个参数,包括0个。例如:
def calc(*numbers): sum=0 for i in numbers: sum=sum+n*n return sum
当已经有一个list或者tuple时,要调用一个可变参数的话,可以在list或者tuple前面加一个*号,把list或者tuple的元素变成可变参数传递进去,例如:
num=[1,2,3]
calc(*num)
*num表示吧num这个list的所有元素作为可变参数传递进去。
关键字参数
关键字参数语序在传入0个或者任意个含参数名的参数,这些关键字参数在函数内部自动组装成为一个dict。例如:
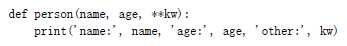
参数包含关键字参数**kw


使用命名关键字参数,要特别注意,*不是参数,而是特殊分隔符。如果缺少*,Python解释器将无法识别位置参数和命名关键字参数。
参数组合:
Python中定义函数,可以用必选参数,默认参数,可变参数,关键字参数,命名关键字参数,都可组合使用。但是可变参数无法和命名关键字参数混合。
参数顺序必须是:必选参数,默认参数,可变参数/命名关键字参数,关键字参数。


*args是可变参数,args接收的是一个tuple;
**kw是关键字参数,kw接收的是一个dict。
以上是关于廖雪峰Python总结1的主要内容,如果未能解决你的问题,请参考以下文章