Flink kafka producer with transaction support
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink kafka producer with transaction support相关的知识,希望对你有一定的参考价值。
Background
In flink 1.5 above, it provides a new kafka producer implementation: FlinkKafkaProducer011, aligning with kafka 0.11 above that supports transaction. Kafka transaction allows multiple kafka messages sent by producer to deliver in an atomic way --> either all success or all fail. The messages can belong to different partitions. Before flink 1.5, it provides exact once semantics only for its internal state via check point. However, if you write stream state to external storage such as kafka or database, there is no guarantee. In flink 1.5, an important new class TwoPhaseCommitSinkFunction is introduced to support extactly once semantic for externa storage. FlinkKafkaProducer011 leverage this feature, so before we look at FlinkKafkaProducer011, we will briefly go through what TwoPhaseCommitSinkFunction does.
TwoPhaseCommitSinkFunction
As its name suggests, TwoPhaseCommitSinkFunction provides a template to implement two phase commit protocol so that writing to external storage and flink checkpoint reaches consensus on success/failure. It provides the following abstract methods:
- beginTransaction
- preCommit
- commit
- abort
- invoke(TXN transaction, IN value, Context context)
The sequence diagram below shows how these methods are invoked (highlighted in red)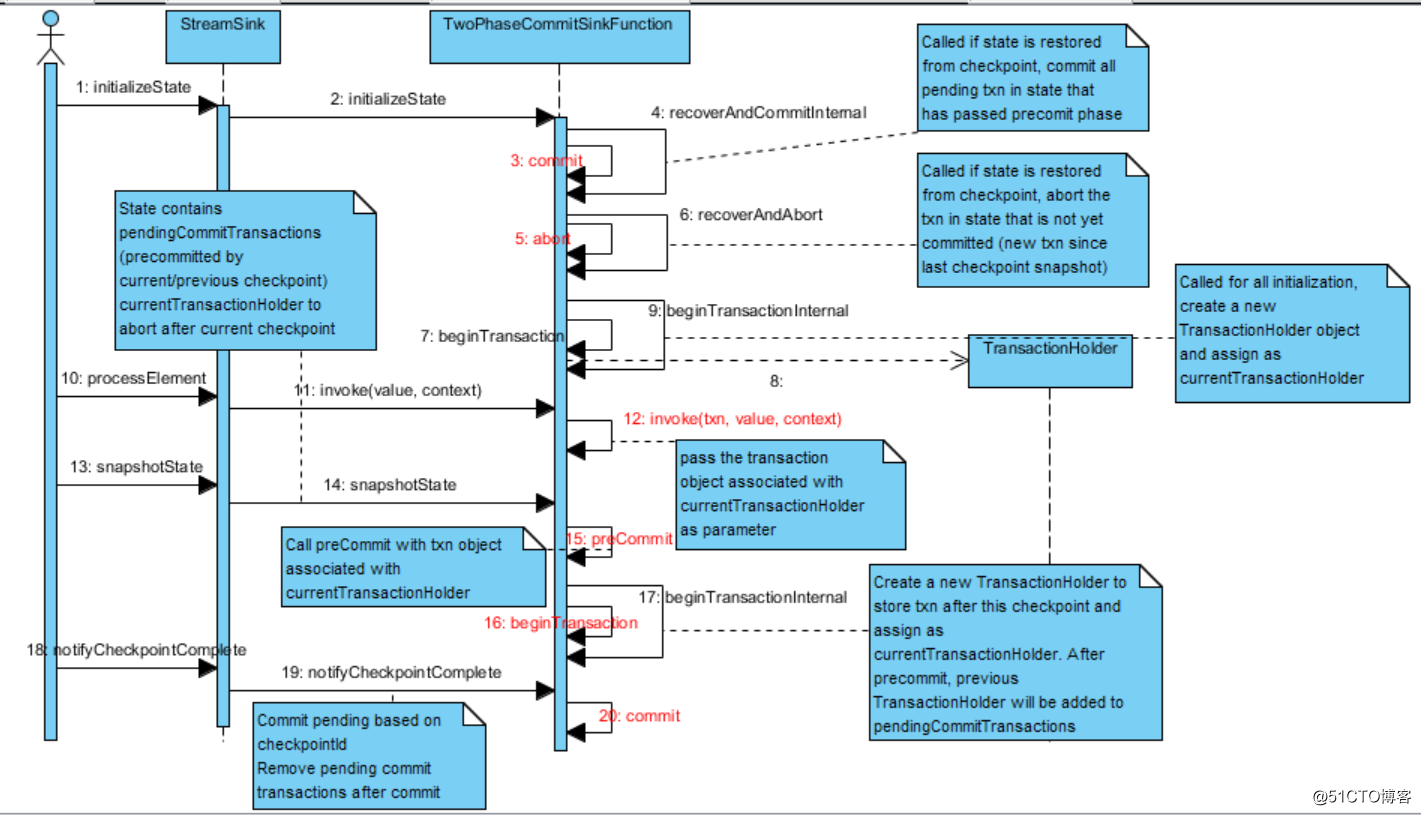
In a typical two phase commit protocol for database, the precommit operation usually involves writing db operations to a WAL file (write ahead log). Once the db operation is persisted, even if server crashed afterwards, it can always recover db operations from log and apply to database, so commit can always success.
Internally, TwoPhaseCommitSinkFunction keeps pendingTransactions : an orderedMap (LinkedHashMap) that records current pending transactions that not yet committed. Key is the checkpoint id that transaction occurs, value is the transaction holder object that contains transaction start time and transaction information. Normally the map contains only one transaction state entry corresponding to the current checkpoint. Under rare situation, it can contain transaction state entry from previous checkpoint if previous checkpoint failed or acknowledgement is delayed.
On snapshot state (snapshotState):
Current transaction holder is put into pendingTransactions. Precommit is called to perform the prepare step in two phase commit. A new transaction is started and internal state is updated to reflect the latest current transaction holder and pendingTransactions.
On checkpoint notification (notifyCheckpointComplete):
All pending transactions in pendingTransactions that have id less than or equals the notified checkpoint id will be committed. Committed transaction is removed from pendingTransactions.
Checkpoint recovery (initializeState)
RecoverAndCommit method will be called on each of the pendingTransactions. While for the current transaction in state (precommit method not yet called), recoverAndAbort method is called
To summarize:
Transaction scope aligns with the checkpoint frequency, indicating that all records between two commits will belong to a single transaction.
Prepare (precommit) step must succeed for snapshot to complete.
Kafka transaction api
KafkaProducer.initTransactions()
KafkaProducer.beginTransaction()
KafkaProducer.sendOffsetsToTransaction(offsets, consumerGroupId)
KafkaProducer.commitTransaction()
KafkaProducer.abortTransaction()
Besides a special property "transactional.id" needs to be assigned to ProducerConfig. This raises an important implication that there can be only one active transaction per producer at any time.
initTransactions method: Ensures any transactions initiated by previous instances of the producer with the same transactional.id are completed. If the previous instance had failed with a transaction in progress, it will be aborted. If the last transaction had begun completion, but not yet finished, this method awaits its completion
Also: initTransactions method assigns an internal producer id and epoch number. Each producer restart will generate a new epoch number, thus allow kafka transaction manager to detect and reject transaction request that was sent before producer restart.
sendOffsetsToTransaction method: used when read from one kafka topic and send data to an other topic (Eg, kafka streaming). so that consumer offset shifts only if producer successfully send data (exactly once)
Combine both
FlinkKafkaProducer011 supports 3 modes: exactly once, at least once or none. Under exactly once mode, a new KafkaProducer will be created on each call to beginTransaction whereas under the other two modes, existing KafkaProducer from current state will be reused. Another important difference is that kafka transaction is only enabled for exactly once mode. As discussed previously, beginTransaction method can be called from initializeState method or snapshotState method. A new KafkaProducer with a different transaction id ensures that producer records sent between two checkpoints belong to different transactions, so that each one can be committed or rolled back separately.
The difference between at least once or none mode is the precommit behavior. for exactly once and at least once mode, kafkaProducer is flushed in precommit to make sure that records in producer buffer are sent to broker before checkpoint snapshot completes. Otherwise, if flink crashes after the current checkpoint, unsent records in producer buffer are lost.

Transaction state object: KafkaTransactionState contains a transient flink kafka producer. transaction id, producer id and epoch. The kafka producer reference act as a shortcut to retrieve kafka producer from current transactionHolder in various lifecycle stage. On state recovery from checkpoint, kafka producer in transaction state will be null and need to be re-created. To commit, transaction id, producer id and epoch for the new kafka producer need to match the previous kafka producer before crash. Otherwise, broker cannot associate commit request with the producer for previous transaction and reject it. See FlinkKafkaProducer.resumeTransaction method on how transaction state, producer id and epoch is set. To abort, only transaction id matters, as there can be only one pending transaction per transaction id.
Another interesting aspect worth exploration is how the unique transaction id is generated. As flink kafka producer runs in parallel, generating a distributed, yet globally unique transaction id is a challenge.
The transaction id can be recycled after commit, so we do not need an unbounded sequence but a range of unique values.
The id range generated will be from startIndex + subtaskIndex * poolSize to startIndex + (subtaskIndex + 1) * poolSize - 1
Start index is stored in NextTransactionalIdHint in flink list state object. Each time a new transaction id range is requested, it will be incremented byNumberOfParallelSubtasks * kafkaProducersPoolSize;
But why not just use java uuid? I think there are two reasons:
Java uuid is purely random, where a monotonically increasing transaction id sequence is more desirable for tracking and monitoring purpose.
If flink crashes before the first checkpoint complete, there is no information about transaction id in state. In this case, system has to guess possible transaction ids within a range and try to abort each of them. With purely random uuid, even guess is not possible.
Other thoughts
Currently, only transaction id is pooled for reuse. for exactly once mode, a new kafka producer is created on each checkpoint snapshot. Depending on the checkpoint interval, this might be an overhead. Why not pool kafka producer directly instead?
以上是关于Flink kafka producer with transaction support的主要内容,如果未能解决你的问题,请参考以下文章
FlinkFlink kafka producer 分区策略 (flink写入数据不均匀 与 数据写入 分区无数据 )
kafka producer生产数据到kafka异常:Got error produce response with correlation id 16 on topic-partition...Er
spring集成kafka运行时报错:Failed to construct kafka producer] with root cause
Flink with Avro Confluent Kafka-Registry