如何在手机上跑深度神经网络
Posted jermmyhsu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在手机上跑深度神经网络相关的知识,希望对你有一定的参考价值。
这天,老板跟你说,希望能在手机上跑深度神经网络,并且准确率要和 VGG、GoogleNet 差不多。
接到这个任务后你有点懵逼,这些网络别说计算量大,就连网络参数也要 100MB 的空间才存得下,放在手机上跑?开玩笑呗。
老板又说,怎么实现是你的事,我要的只是这个功能。
你默默地点了点头。
初步尝试:MobileNet v1
问题出在哪
要在手机上跑深度网络,需要在模型参数和计算量上进行优化。
那深度神经网络的计算量和参数量主要体现在哪呢?这里以 VGG16 为例:
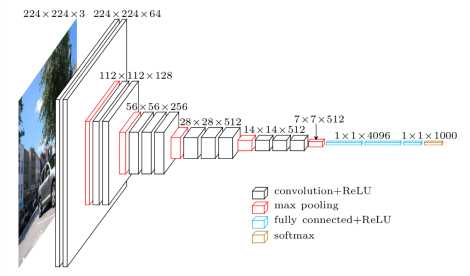
第一层卷积: [224 x 224 x 3] --> [224 x 224 x 64],卷积核大小为 3 x 3(简单起见,这里计算量的计算忽略激活函数)
计算量为:(3 imes 3 imes 3 imes 224 imes 224 imes 64 approx 8.7 imes 10^7)
参数量为:(3 imes 3 imes 3 imes 64 = 1728)
第二层卷积:[112 x 112 x 64] --> [112 x 112 x 128],卷积核大小为 3 x 3。
计算量为:(3 imes 3 imes 64 imes 112 imes 112 imes 128 approx 9.2 imes 10^8)
参数量为:(3 imes 3 imes 64 imes 128 = 73728)
......
第一层全连接层:[14 x 14 x 512] --> [4096]。
计算量为:(14 imes 14 imes 512 imes 4096 approx 4.1 imes 10^8)
参数量为:(4096 imes 1000 = 4096000)
......
两相对比,同时考虑到网络中卷积层比全连层多,就不难发现深度卷积网络中的计算量主要由卷积层承包,而参数则集中在全链接层。因此,要想对模型做优化,可以在卷积层的计算上做点手脚,同时减小全连接层的维度。
Separable Convolution
虽然找到了问题所在,但具体要如何优化卷积层的计算量呢?幸运的是,你在搜索的过程中发现已经有人针对这个问题给出了解决方案:Separable Convolution。这是一种对卷积运算进行分解的方法。
以下例子摘自文末链接:卷积神经网络中的Separable Convolution
假设现在需要做这样一个卷积操作:[64 x 64 x 3] --> [64 x 64 x 4],那么通常的操作是这样的(假设卷积核大小为 3 x 3):
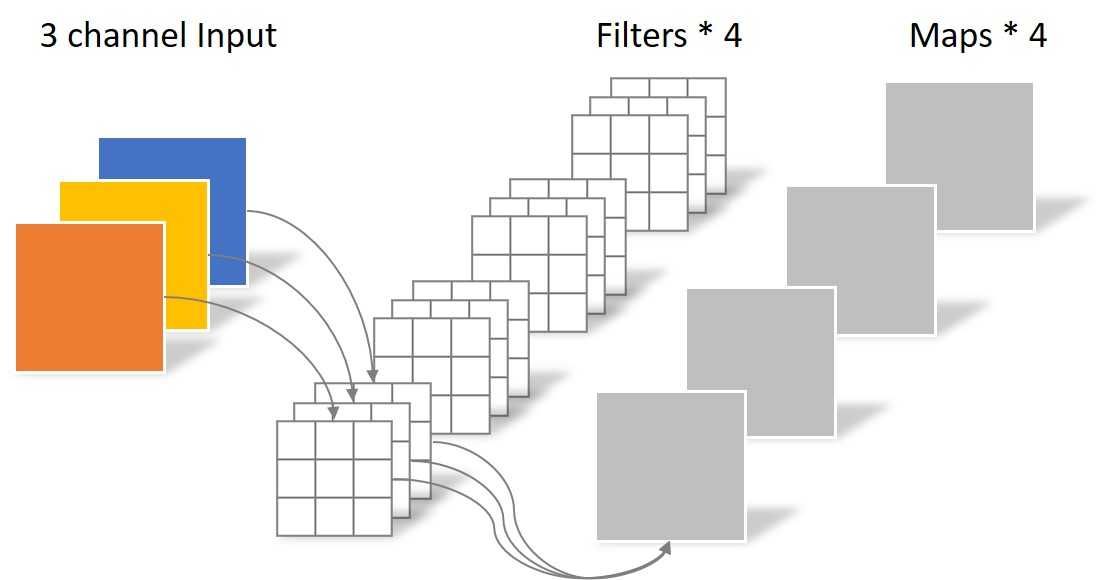
这种做法的计算量为:(3 imes 3 imes 3 imes 64 imes 64 imes 4 = 442368),
参数量为:(3 imes 3 imes 3 imes 4 = 108)。
而 Separable Convolution 会将该操作分解为两步:Depthwise Convolution 和 Pointwise Convolution。
Depthwise Convolution 的过程其实非常简单,顾名思义,Depthwise 就是每个通道单独做一遍卷积:
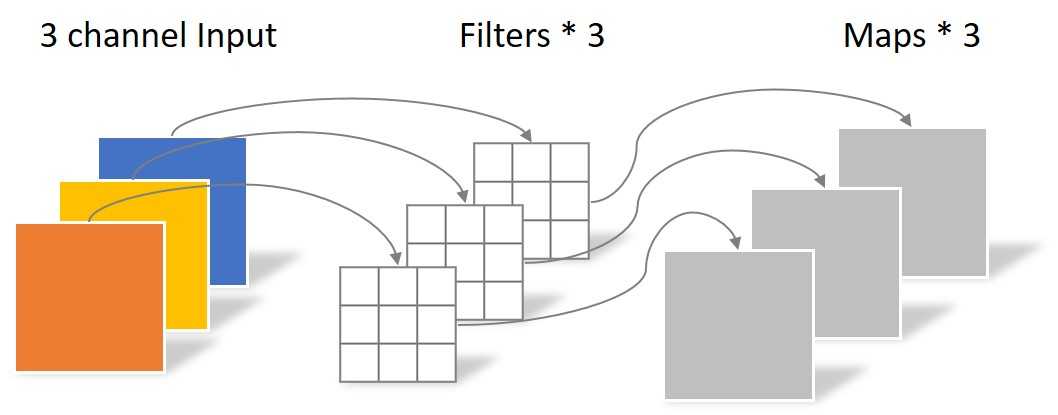
这种做法的效果是:[64 x 64 x 3] --> [64 x 64 x 3],由于是 Depthwise 的,所以只需要三个 [3 x 3 x 1] 的 filter 即可。
因此计算量为:(3 imes 3 imes 64 imes 64 imes 3=110592),
参数量为:(3 imes 3 imes 3 = 27)。
不过 Depthwise 将不同通道之间的联系断开了,而且输出的通道数与输入是一样的。为了得到 [64 x 64 x 4] 的输出,还需要经过 Pointwise Convolution。
Pointwise Convolution 的过程在 Depthwise 之后进行,它是用一个 [1 x 1] 的卷积核把 [64 x 64 x 3] 的 feature map 转换为 [64 x 64 x 4]:
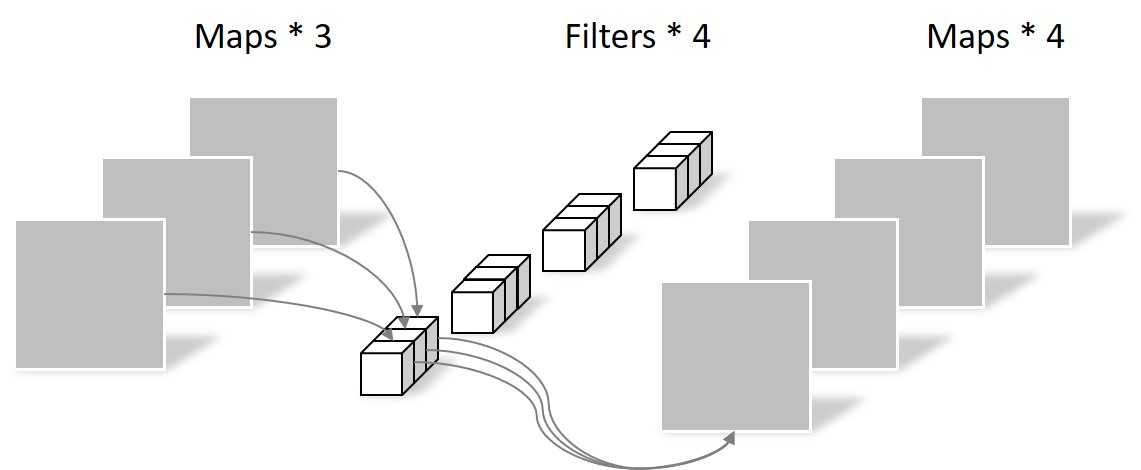
计算量为:(1 imes 1 imes 64 imes 64 imes 3 imes 4=49152),
参数量为:(1 imes 1 imes 3 imes 4 = 12)。
我们发现,通过 Separable Convolution 这种分解的方法也可以拼凑出一个 [64 x 64 x 4] 的 feature map,
而这种方法的计算量为:(110592 + 49152=159744),而总的参数量为:(27 + 12 = 39)。
对比原先的 442368 (计算量) 和 108 (参数量),简直实惠了好多。
于是,你通过这种套路构造出了一个适合手机端运行的深度网络,并简化了全连接层的参数:
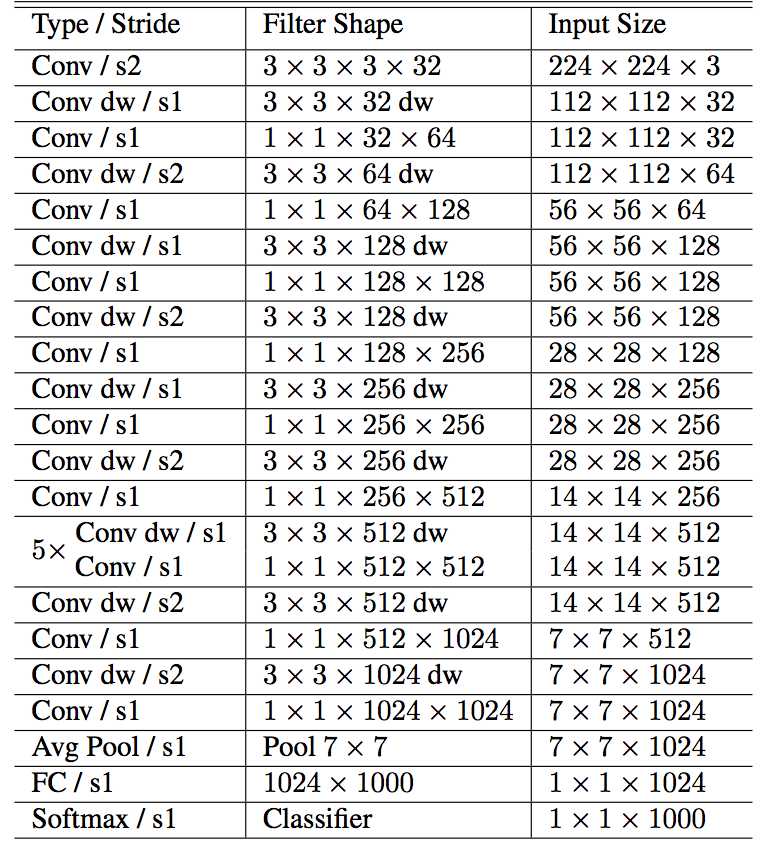
图中的 Conv dw 指的就是 Depthwise Convolution。由于是为手机设计的网络,因此你取了个形象的名字:Mobilenet。
不过,这个网络的精度会不会下降呢?你赶紧在 ImageNet 数据集上做了实验:
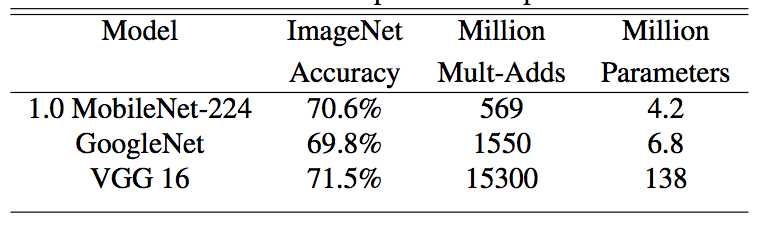
这个结果实在是太感人了,精度几乎和 GoogleNet 相当,但计算量却只有后者的三分之一,参数量也减少了三分之一(当然也可能是图像分类这个问题相对简单)。
为了方便对模型大小的进一步调整,你提供了两个额外的参数: (alpha)、 ( ho)。(alpha) 又称为 Width Multiplier,主要用来控制 feature map 的 channel 数目,因为在某些任务中,很多 feature map 的 channel 可能包含很少的信息,因此少一些,而有些情况可能需要更多的 channel。(alpha=1) 时就是上文中提出的基准网络。( ho) 则是图像的分辨率,由它控制输入图片的大小。
进阶:ShuffleNet v1
Separable Convolution 其实就是 MobileNet v1 的精华了,个人认为,MobileNet v1 能取得成功主要还是那些大网络在处理简单任务时存在大量的冗余,所以 MobileNet v1 用更少的参数量拼凑出同样大小的 feature map 时,性能并没有明显下降。
而 ShuffleNet v1 则是在此基础上进一步压榨卷积操作,它的重点放在了 Pointwise Convolution 上。Pointwise Convolution 的作用是把 feature map 的所有 channel 信息联系起来,但这种联系可能本身就存在冗余。举个例子,一个 [64 x 64 x 4] 的 feature map,通过 [1 x 1 x 4] 的卷积核后,可以得到 [64 x 64 x 1] 的输出,这个 [1 x 1 x 4] 的卷积核其实就是把原来 feature map 上每个位置的所有 channel 信息(一个 [1 x 1 x 4] 的通道向量)进行加权求和,得到下一层 feature map 上的一个点。不过,真的有必要融和整个通道向量的信息吗?如果只对两个通道的信息进行相加,得到的结果会比四个通道差吗?为了探究这个问题,炼丹师们把原来的 Pointwise Convolution 改造成了 Group Convolution,这个 Group Convolution 其实也不是什么新鲜玩意,当年 AlexNet 刚出来的时候,由于显存不足,就曾将卷积操作分为两组,用两张显卡来装 feature map,这种做法导致更少的参数量和计算量,而且在某些任务中并不会对性能产生很大影响。ShuffleNet v1 的炼丹师显然发现了这一点。
Group Convolution 的操作非常简单,还是举之前的例子:一个 [64 x 64 x 4] 的 feature map,要想进一步得到 [64 x 64 x 2] 的 feature map,直接用 Pointwise Convolution 处理的话,需要一个 [1 x 1 x 4 x 2] 的卷积张量。但用上 Group Convolution 后,我们可以这样操作,用一个 [1 x 1 x 2 x 1] 的卷积张量对原来 feature map 四层通道中的前面两层进行卷积操作,得到一个 [64 x 64 x 1] 的 feature map,之后,用另一个 [1 x 1 x 2 x 1] 的卷积张量继续对后面两层进行卷积操作,同样得到一个 [64 x 64 x 1] 的 feature map,这两块 feature map 拼在一起,最终得到一个 [64 x 64 x 2] 的 feature map。
仔细数数,原来 Pointwise Convolution 的计算量为:(1 imes 1 imes 64 imes 64 imes 4 imes 2=32768),参数量为:(1 imes 1 imes 4 imes 2=8),而现在拆成 Group Convolution 后,计算量为:(1 imes 1 imes 64 imes 64 imes 2 imes 2=16384),参数量为:(1 imes 1 imes 2 imes 2=4),计算量和参数量都减少了一半。
鸡贼的读者可能还发现,如果把 Group Convolution 做到极致,每个 Group 只有一个 channel 的话,就变成 Depthwise + Pointwise Convolution 了,哈哈,原来又是拼凑游戏,笑出声。
不过,仅仅用 Group Convolution,说性能不会影响很多人是不信的,毕竟本身就是 Pointwise Convolution,相邻点之间的信息已经忽略了,要是通道上的信息也忽略太多,难免会存在问题。所以,ShuffleNet v1 的 Shuffle 该登场了。炼丹师为了增强 Group Convolution 的鲁棒性,在对通道进行相加时,故意打乱了通道顺序。这样一来,在上面的例子中,本来是 1、2 通道结合得到一个新的点,就变成了 1、3 通道结合,2、4 通道结合了。
这也就是这篇论文的精华所在:
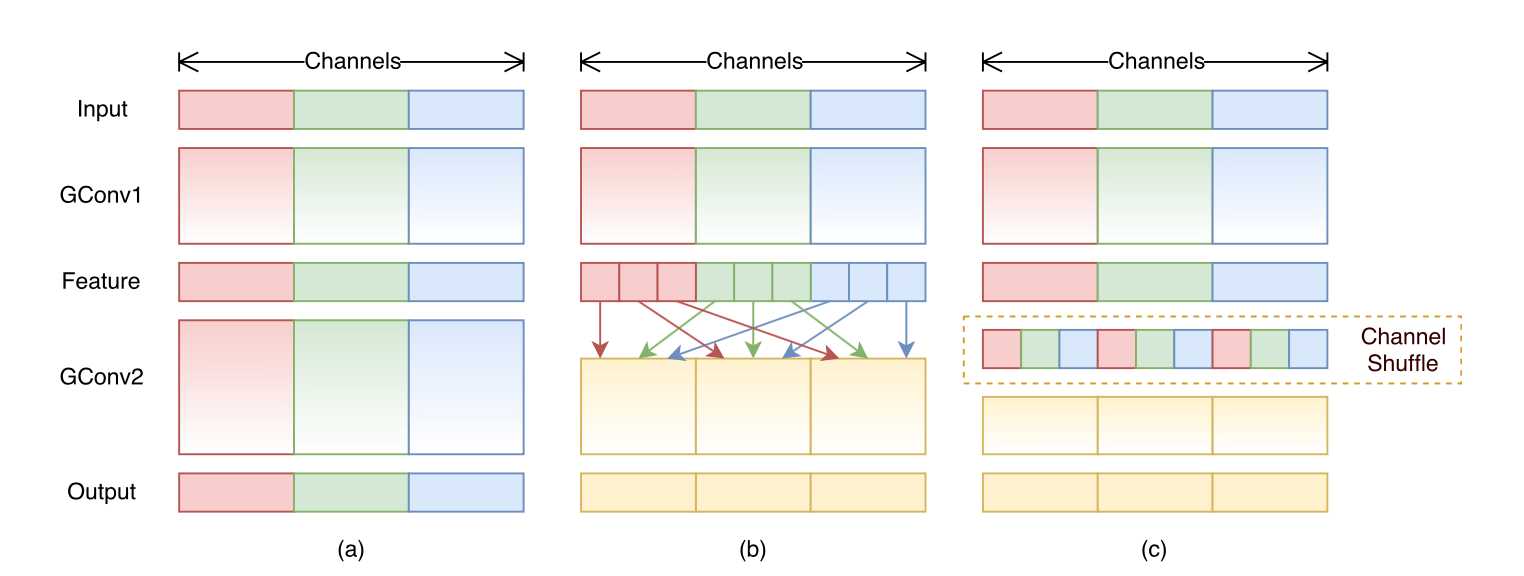
当然啦,估计是考虑到 Group Convolution 本身损失的信息有点严重,论文又特意加了 ResNet 中的短路连接,算是弥补了一点信息:
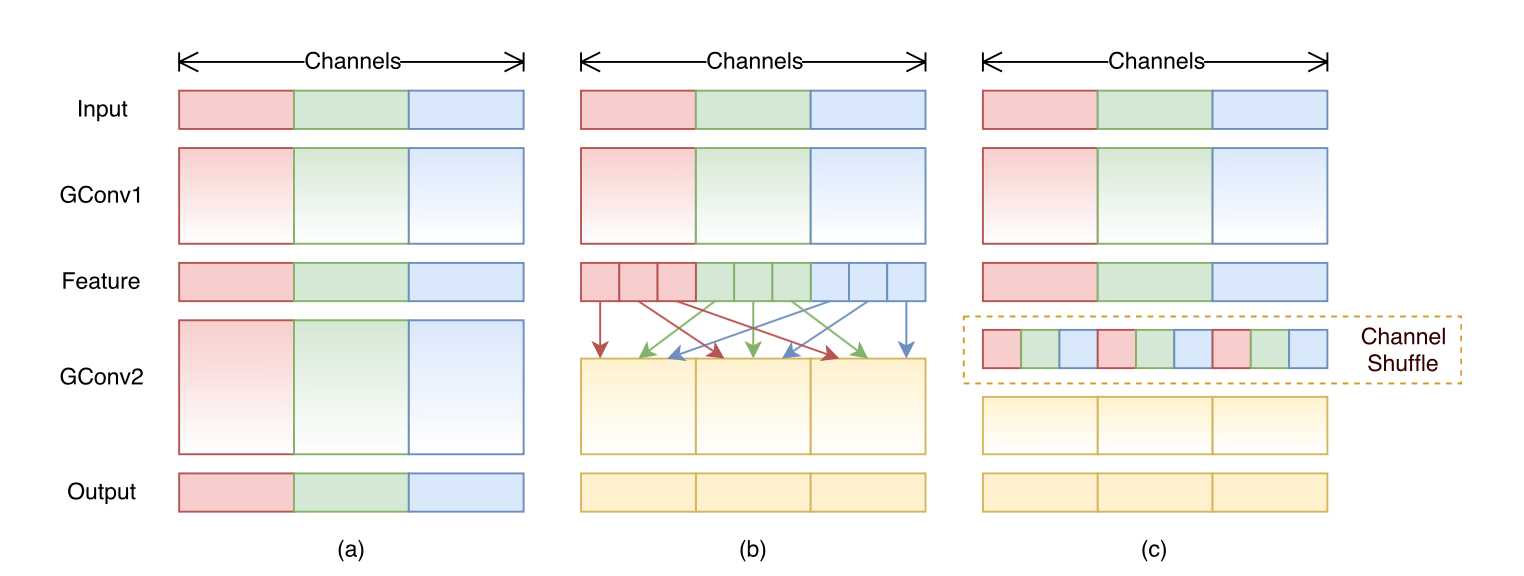
下图给出的是论文中关于 Shuffle 操作的实验:
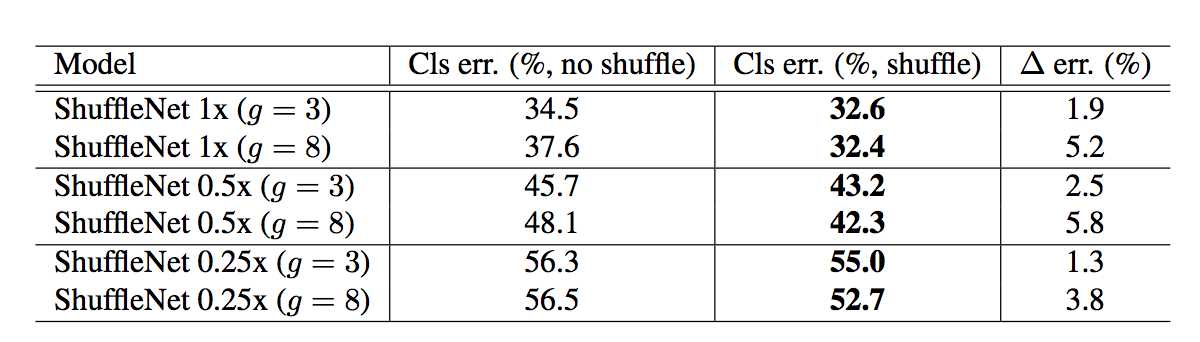
Cls err 是 ImageNet 数据集上的错误分类率,数值越小证明结果越好,g 则表示 group 的数量。实验结果给出这样一个信息:当 group 的数量越多时,shuffle 的作用也越明显。这一点也很好理解,因为 group 越多,丢失的信息也越多,这时如果能把 channel 打散,那么不同组之间的 channel 信息就有了交流的通道,能在一定程度上增加鲁棒性。
总结
总的来说,MobileNet v1 作为第一个进行手机端优化的工作,其亮点主要是 Depthwise Convolution 和 Pointwise Convolution。ShuffleNet v1 则是在 MobileNet v1 的基础上加入了 Group Convolution,并通过 Shuffle 的方法提高鲁棒性,同时加入短路连接保持网络的表达能力。
参考
以上是关于如何在手机上跑深度神经网络的主要内容,如果未能解决你的问题,请参考以下文章