对英文文档中的单词与词组进行频率统计
Posted successfullyreleased
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对英文文档中的单词与词组进行频率统计相关的知识,希望对你有一定的参考价值。
一、程序分析
1、以只读模式读取文件到字符串
def process_file(path): try: with open(path, ‘r‘) as file: text = file.read() except IOError: print("Read File Error!") return None return text
2、对字符串进行数据清洗,返回一个字典
import re word_list = re.sub(‘[^a-zA-Z0-9n]‘, ‘ ‘, textString).lower().split()
使用正则表达式过滤掉文档中的特殊字符,把它们全部替换为空格,方便后续的分隔操作。(忽略大小写,所以全部使用小写字母)
2.1、只考虑单词频率统计
for word in word_list: if word in word_freq: word_freq[word] += 1 else: word_freq[word] = 1
判断单词列表中的单词是否在单词频率字典中。
如果这个单词在字典中,则该单词的个数加1;
如果这个单词不在字典中,则以这个单词为键,赋值为1,表示这个单词第一次出现。
2.2、考虑单词和词组的频率
2.2.1、数据结构
词组是由单词连接构成的,一个单词既可以与前面的单词构成词组,也可以与后面的单词构成词组。
同时,一个单词可能在文章中多次出现,并且和前后的单词构成多种不同的词组。
这也就表示几乎每一个单词可以一前一后发散出去,这与图状结构颇为类似。
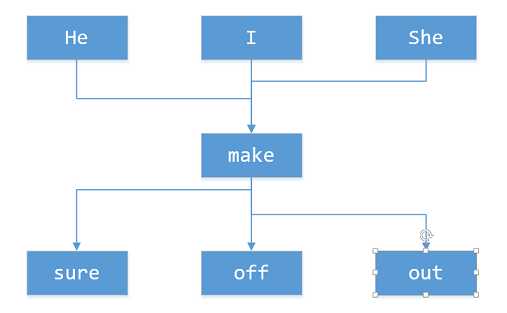
选择图状结构与当前的问题颇为契合。但是,目前python没有一种已知的图类来供我们操作。(自定义类暂不作考虑)
于是我想到了树状结构,砍去了单词向前的发散,只保留向后的。至此,问题就变成了构建森林。
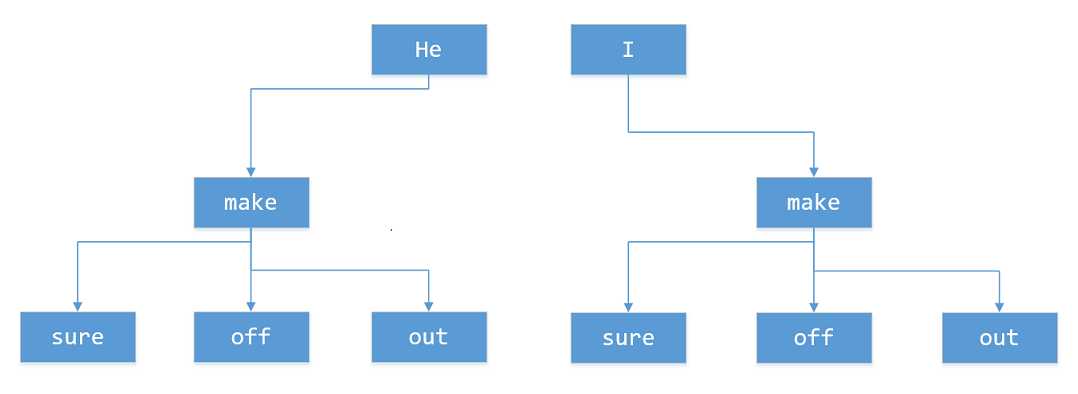
而在python中,森林是比较容易表示的。用一个字典放置每一棵树的根节点,字典套字典,就形成了森林。
可能你们要问单词和词组的统计个数放在哪。我使用“Value”作键,键值number这样一种结构放在该单词的字典中。
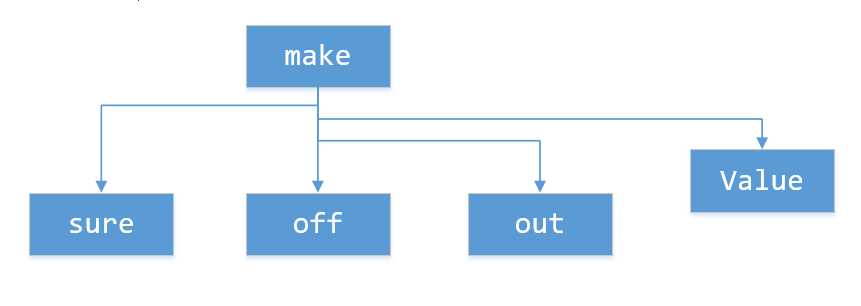
具体的字典示例样本参见sample.json
2.2.2、具体流程
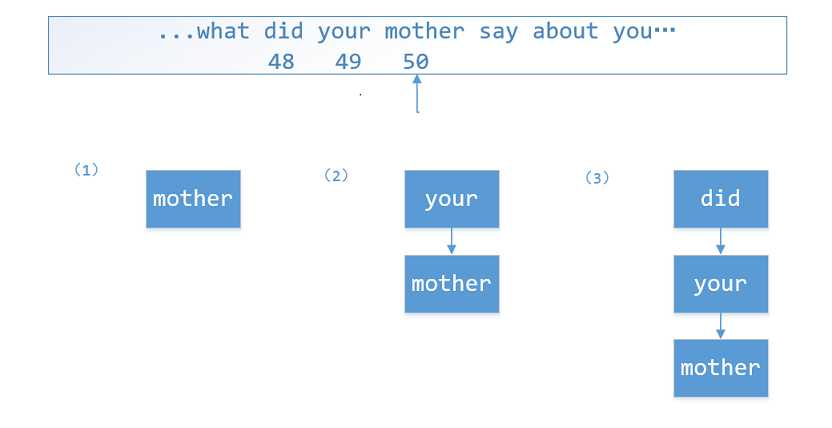
以索引停在50,词组限制单词个数为3为例:
(1)在树的根节点中寻找mother节点,找不到就创建mother节点。
"mother":{ "Value":1 }
(2)在树的根节点中寻找your节点,找到了继续寻找mother节点,找不到就创建mother节点。(不可能找不到,因为索引经过49之后肯定存在your根节点)
(3)以此类推,在树的根节点中寻找did节点,找到了继续寻找your节点,,找到了继续寻找mother节点,找不到就创建mother节点......
具体实现:
count = len(word_list)
i = 0
while i < count: # 因为需要用到索引遍历列表,只能使用while来遍历列表
finish = i
start = i - num + 1 # num表示词组的单词个数限制,start表示以该单词作为词组结尾的第一个单词的索引
if start < 0:
start = 0 # 处理开始时索引前面没有单词的特殊情况
index = i
while index >= start: # 做num次建立节点
if word_list[i] in get_dict_value(word_freq, word_list[index: finish]).keys():
get_dict_value(word_freq, word_list[index: finish])[word_list[i]][‘Value‘] += 1
else:
get_dict_value(word_freq, word_list[index: finish]).update({word_list[i]: {‘Value‘: 1}})
index -= 1
i += 1
get_dict_value函数
def get_dict_value(word_freq={}, keys=[]): """如果keys为字符串,返回word_freq字典中以keys为键的值。 如果keys为列表,则使用eval()函数进行字符串拼接,深度查找word_freq字典中以keys为键的值。""" if type(keys).__name__ == ‘str‘: return word_freq[keys] else: count = len(keys) if count == 0: return word_freq elif count == 1: return word_freq[keys[0]] elif count == 2: return word_freq[keys[0]][keys[1]] elif count == 3: return word_freq[keys[0]][keys[1]][keys[2]] #对寻找三个单词以下的词组进行特化 else: string = "word_freq[‘" string += "‘][‘".join(keys) string += "‘]" return eval(string) #动态寻找字典的值的一般版本
2.2.3、字典格式化
数据已经存储到了森林中,接下来就是如何把森林格式化成普通的字典。
相比深度优先遍历,我选择的是更易理解与实现的广度优先遍历。
广度优先遍历的原理我不再赘述。
def format_dict(word_freq={}): """对统计短语的情况生成的复杂字典进行格式化,格式化后的形式为<str,int>""" formated_word_freq = {} phrases = [] for word in word_freq.keys(): #将所有根节点放入队列中 phrases.append(word) while len(phrases) > 0: #只要队列还有元素,就表明还没有遍历结束 phrase = phrases[0] if len(get_dict_value(word_freq, phrase)) == 1 and type(phrase).__name__ == ‘list‘: formated_word_freq[‘ ‘.join(phrase)] = get_dict_value(word_freq, phrase)[‘Value‘] #搜索到叶子节点了,这个节点存入格式化好的字典中 else: for next_word in get_dict_value(word_freq, phrase): #除"Value"键值对以外的键都入队 temp = [] if type(phrase).__name__ == ‘str‘: temp.append(phrase) else: temp.extend(phrase) if next_word != ‘Value‘: temp.append(next_word) phrases.append(temp) phrases.pop(0) #搜索完队列的第一个节点的子节点,这个节点出队 # print(formated_word_freq) return formated_word_freq
3、输出字典(没有改动)
def output_result(word_freq): if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: print(item)
4、主函数
if __name__ == "__main__": import argparse parser = argparse.ArgumentParser() parser.add_argument(‘path‘) #路径 parser.add_argument(‘num‘) #词组单词个数 args = parser.parse_args() path = args.path num = int(args.num) buffer = process_file(path) if buffer: word_freq = process_buffer(buffer, num) if num != 1: word_freq = format_dict(word_freq) output_result(word_freq)
命令行接受两个参数,一个是英文文档的路径,还有一个是构成一个词组的最大单词个数(为1时即单词统计)。没有这个限制,森林里就会出现一棵从第一个单词到最后一个单词的树。
二、代码风格说明
基本遵从PEP8,PEP8 涵盖了诸如空格、函数/类/方法之间的换行、import、对已弃用功能的警告之类的寻常东西,是一个不错的准则。
def get_dict_value(word_freq={}, keys=[]): """如果keys为字符串,返回word_freq字典中以keys为键的值。 如果keys为列表,则使用eval()函数进行字符串拼接,深度查找word_freq字典中以keys为键的值。""" if type(keys).__name__ == ‘str‘: return word_freq[keys] else: count = len(keys) if count == 0: return word_freq elif count == 1: return word_freq[keys[0]] elif count == 2: return word_freq[keys[0]][keys[1]] elif count == 3: return word_freq[keys[0]][keys[1]][keys[2]] #对寻找三个单词以下的词组进行特化 else: string = "word_freq[‘" string += "‘][‘".join(keys) string += "‘]" return eval(string) #动态寻找字典的值的一般版本
注释基本也只在关键地方才有,不必面面俱到。
三、程序运行命令、运行结果截图
运行命令:
python statistic.py Gone_with_the_wind.txt 1
python statistic.py Gone_with_the_wind.txt 2
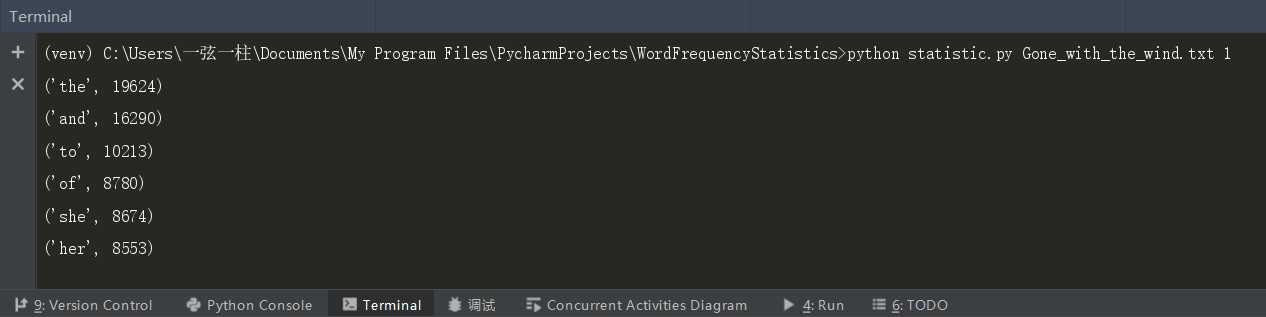
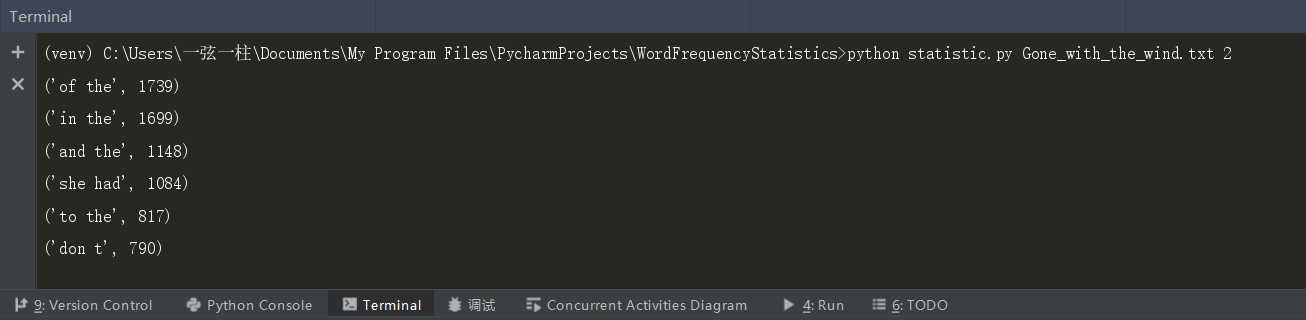
四、简单性能分析
运行命令:
python -m cProfile -o result.out -s cumulative statistic.py Gone_with_the_wind.txt 2
python gprof2dot.py -f pstats result.out | dot -Tpng -o result.png
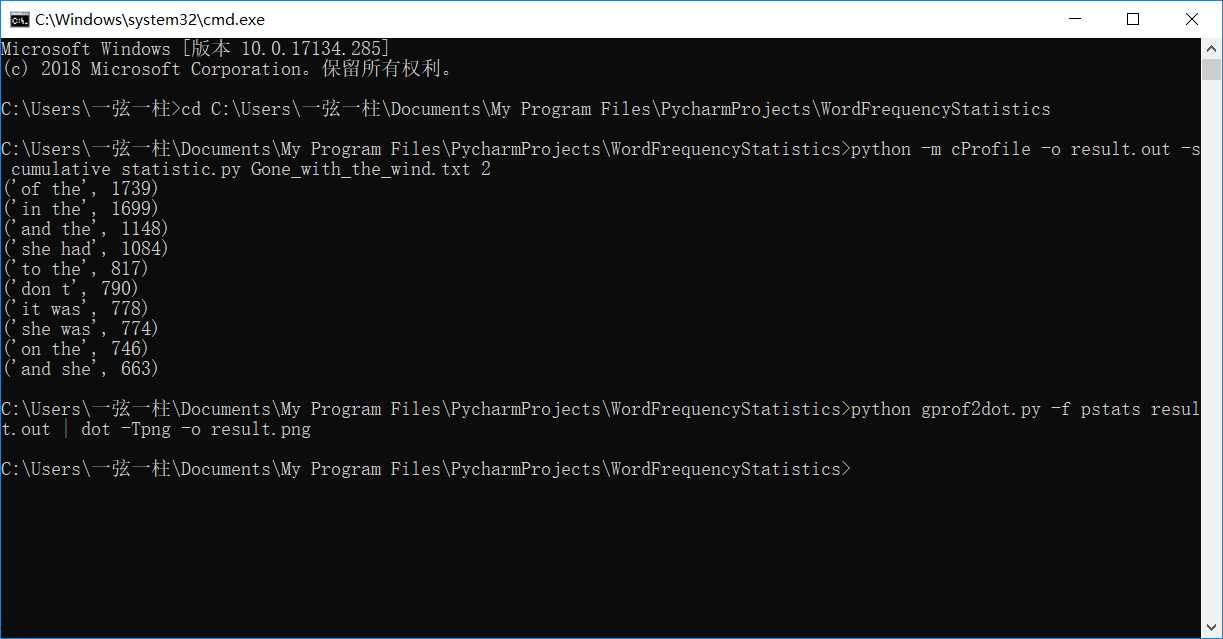
单词统计性能分析:
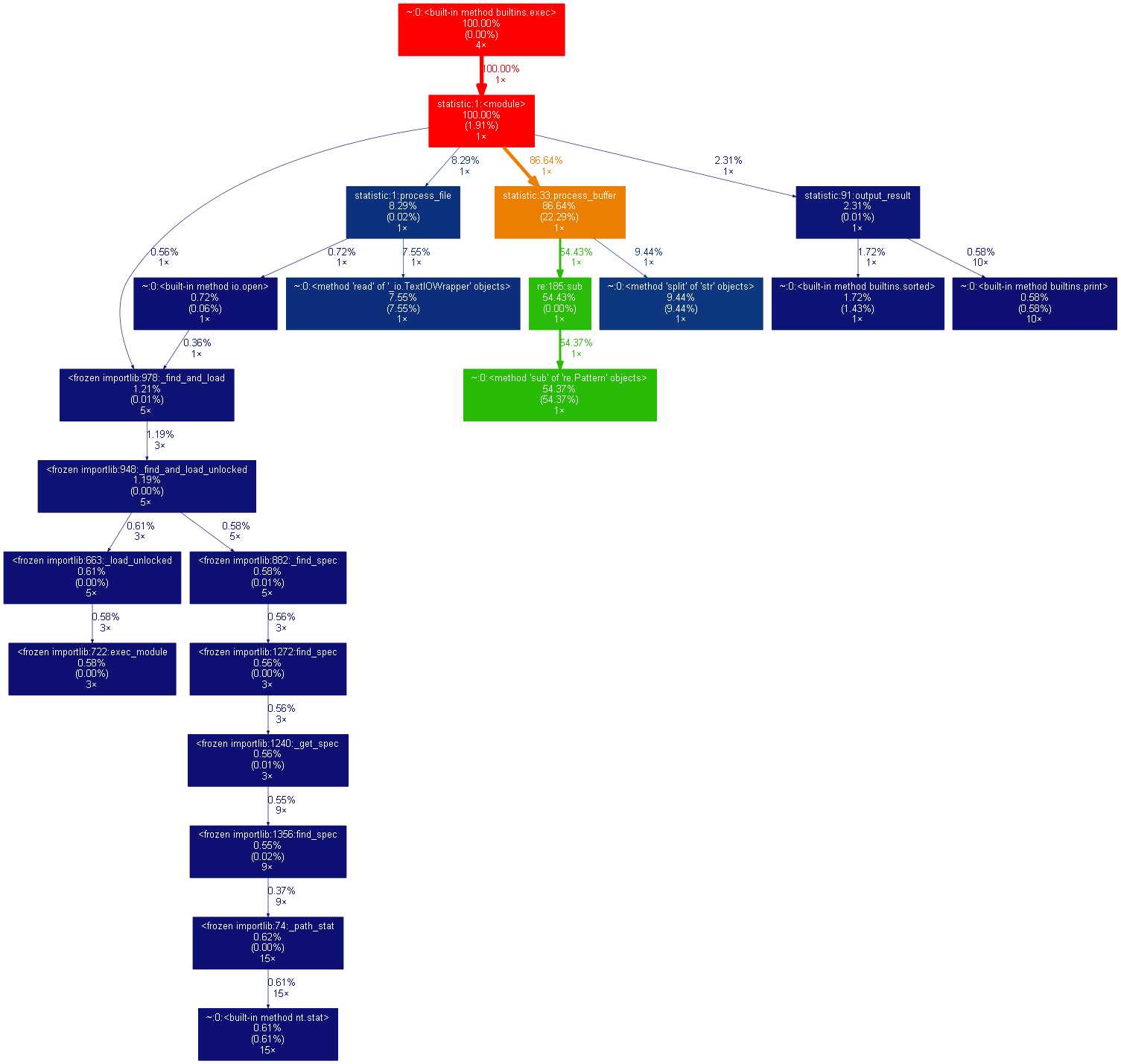
词组统计性能分析:
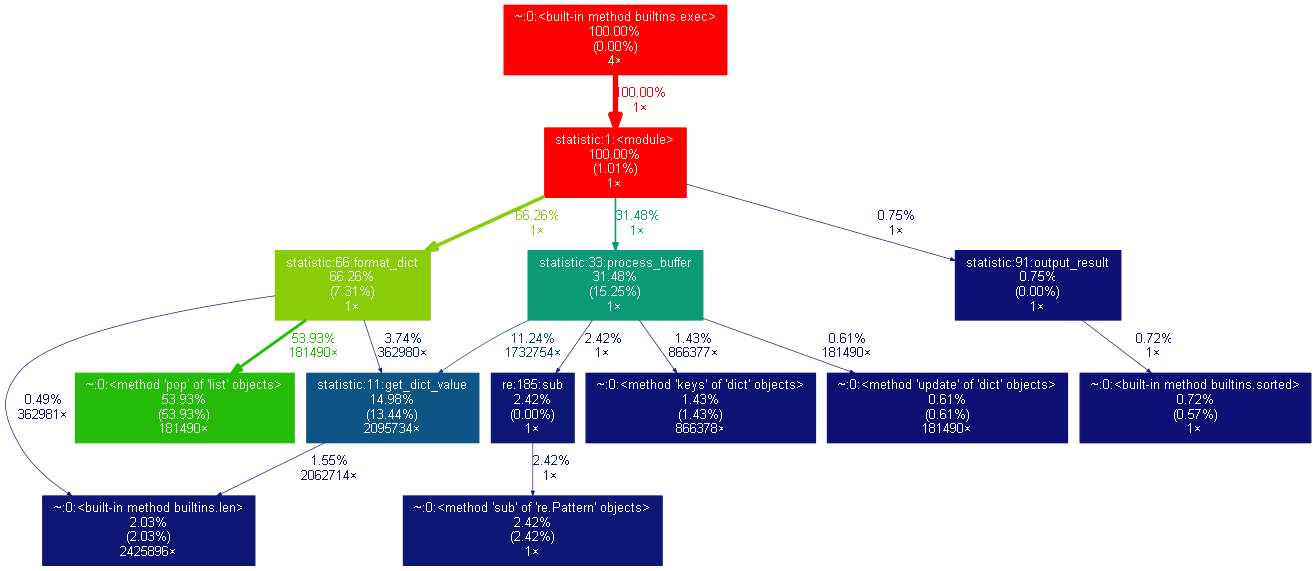
在进行单词统计时,时间有五成花费在过滤特殊字符上,有三成花费在创建字典上。
而在词组统计中,过滤特殊字符只占了一成,两层时间在创建森林,六成时间在格式化森林。其中,尤其以list的pop()函数占用时间最多,将近一半的时间用来出队。
程序优化:尝试在不pop()得情况下修改广度优先遍历。尝试另一种数据结构,森林比图占的内存多。
修改中...
以上是关于对英文文档中的单词与词组进行频率统计的主要内容,如果未能解决你的问题,请参考以下文章