double类型的数据在计算时准确性的错误
Posted muailiulan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了double类型的数据在计算时准确性的错误相关的知识,希望对你有一定的参考价值。
浮点数 浮点数是属于有理数中某特定子集的数的数字表示,在计算机中用以近似表示任意某个实数。具体的说,这个实数由一个整数或定点数(即尾数)乘以某个基数(计算机中通常是2)的整数次幂得到,这种表示方法类似于基数为10的科学记数法。
浮点计算是指浮点数参与的运算,这种运算通常伴随着因为无法精确表示而进行的近似或舍入。
一个浮点数a由两个数m和e来表示:a = m × b^e。在任意一个这样的系统中,我们选择一个基数b(记数系统的基)和精度p(即使用多少位来存储)。m(即尾数)是形如±d.ddd...ddd的p位数(每一位是一个介于0到b-1之间的整数,包括0和b-1)。如果m的第一位是非0整数,m称作规格化的。有一些描述使用一个单独的符号位(s 代表+或者-)来表示正负,这样m必须是正的。e是指数。
由此可以看出,在计算机中表示一个浮点数,其结构如下:
尾数部分(定点小数) 阶码部分(定点整数)数符±尾数m阶符±阶码e
这种设计可以在某个固定长度的存储空间内表示定点数无法表示的更大范围的数。
例如,一个指数范围为±4的4位十进制浮点数可以用来表示43210,4.321或0.0004321,但是没有足够的精度来表示432.123和43212.3(必须近似为432.1和43210)。当然,实际使用的位数通常远大于4。
此外,浮点数表示法通常还包括一些特别的数值:+∞和??∞(正负无穷大)以及NaN(‘Not a Number‘)。无穷大用于数太大而无法表示的时候,NaN则指示非法操作或者无法定义的结果。
众所周知,计算机中的所有数据都是以二进制表示的,浮点数也不例外。然而浮点数的二进制表示法却不像定点数那么简单了。
先澄清一个概念,浮点数并不一定等于小数,定点数也并不一定就是整数。所谓浮点数就是小数点在逻辑上是不固定的,而定点数只能表示小数点固定的数值,具用浮点数或定点数表示某哪一种数要看用户赋予了这个数的意义是什么。
C++中的浮点数有6种,分别是:
float:单精度,32位
unsigned float:单精度无符号,32位
double:双精度,64位
unsigned double:双精度无符号,64位
long double:高双精度,80位
unsigned long double:高双精度无符号,80位(嚯,应该是C++中最长的内置类型了吧!)
然而不同的编译器对它们的支持也略有不同,据我所知,很多编译器都没有按照IEEE规定的标准80位支持后两种浮点数的,大多数编译器将它们视为double,或许还有极个别的编译器将它们视为128位?!对于128位的long
double我也仅是听说过,没有求证,哪位高人知道这一细节烦劳告知。
下面我仅以float(带符号,单精度,32位)类型的浮点数说明C++中的浮点数是如何在内存中表示的。先讲一下基础知识,纯小数的二进制表示。(纯小数就是没有整数部分的小数,讲给小学没好好学的人)
纯小数要想用二进制表示,必须先进行规格化,即化为 1.xxxxx * ( 2 ^ n ) 的形式(“^”代表乘方,2 ^ n表示2的n次方)。对于一个纯小数D,求n的公式如下:
n = 1 + log2(D); // 纯小数求得的n必为负数
再用 D / ( 2 ^ n ) 就可以得到规格化后的小数了。接下来就是十进制到二进制的转化问题,为了更好的理解,先来看一下10进制的纯小数是怎么表示的,假设有纯小数D,它小数点后的每一位数字按顺序形成一个数列:
{k1, k2, k3, ... , kn}
那么D又可以这样表示:
D = k1 / (10 ^ 1 ) + k2 / (10 ^ 2 ) + k3 / (10 ^
3 ) + ... + kn / (10 ^ n )
推广到二进制中,纯小数的表示法即为:
D = b1 / (2 ^ 1 ) + b2 / (2 ^ 2 ) + b3 / (2 ^ 3 ) +
... + bn / (2 ^ n )
现在问题就是怎样求得b1, b2, b3,……,bn。算法描述起来比较复杂,还是用数字来说话吧。声明一下,1 / ( 2 ^ n )这个数比较特殊,我称之为位阶值。
例如0.456,第1位,0.456小于位阶值0.5故为0;第2位,0.456大于位阶值0.25,该位为1,并将0.45减去0.25得0.206进下一位;第3位,0.206大于位阶值0.125,该位为1,并将0.206减去0.125得0.081进下一位;第4位,0.081大于0.0625,为1,并将0.081减去0.0625得0.0185进下一位;第5位0.0185小于0.03125……
最后把计算得到的足够多的1和0按位顺序组合起来,就得到了一个比较精确的用二进制表示的纯小数了,同时精度问题也就由此产生,许多数都是无法在有限的n内完全精确的表示出来的,我们只能利用更大的n值来更精确的表示这个数,这就是为什么在许多领域,程序员都更喜欢用double而不是float。
float的内存结构,我用一个带位域的结构体描述如下:
struct MYFLOAT
{
bool bSign : 1; // 符号,表示正负,1位
char cExponent : 8; // 指数,8位
unsigned long ulMantissa : 23; // 尾数,23位
};
符号就不用多说了,1表示负,0表示正
指数是以2为底的,范围是 -128 到 127,实际数据中的指数是原始指数加上127得到的,如果超过了127,则从-128开始计,其行为和X86架构的CPU处理加减法的溢出是一样的。
比如:127 + 2 = -127;-127 - 2 =
127
尾数都省去了第1位的1,所以在还原时要先在第一位加上1。它可能包含整数和纯小数两部分,也可能只包含其中一部分,视数字大小而定。对于带有整数部分的浮点数,其整数的表示法有两种,当整数大于十进制的16777215时使用的是科学计数法,如果小于或等于则直接采用一般的二进制表示法。科学计数法和小数的表示法是一样的。
小数部分则是直接使用科学计数法,但形式不是X * ( 10 ^ n ),而是X * ( 2 ^ n )。拆开来看。
0 00000000 0000000000000000000000
符号位 指数位 尾数位
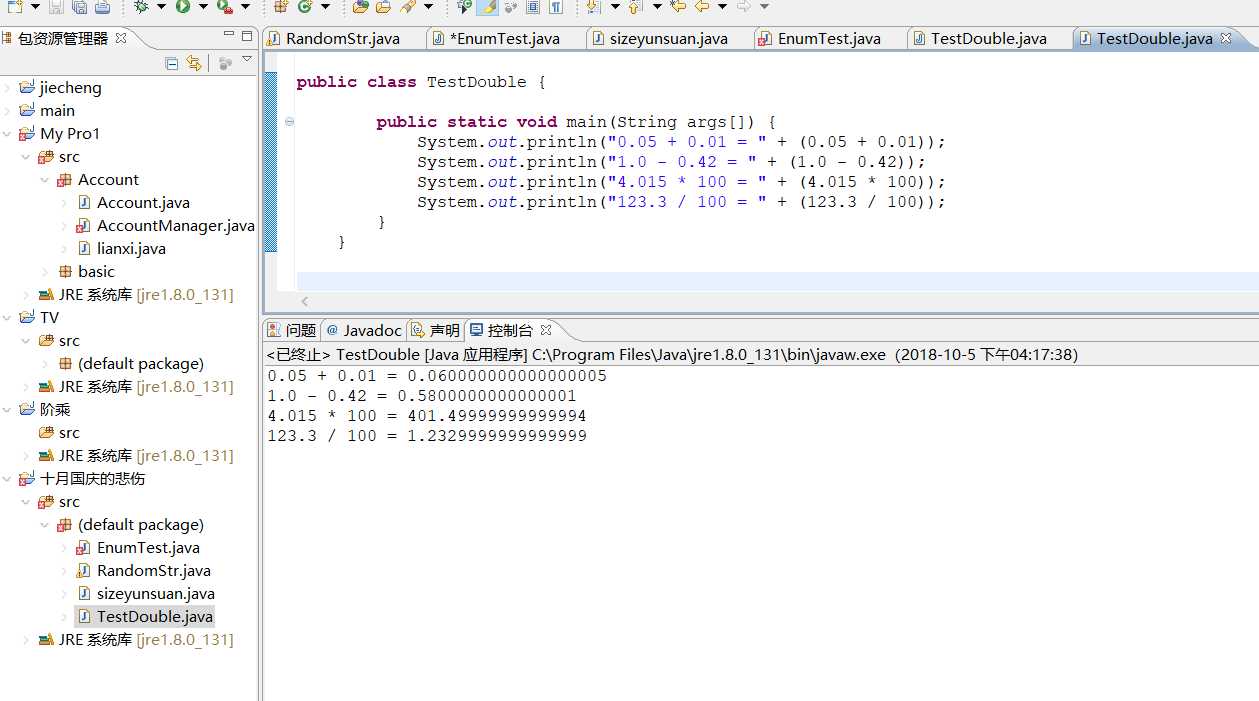
以上是关于double类型的数据在计算时准确性的错误的主要内容,如果未能解决你的问题,请参考以下文章
java中怎样把double基本数据类型包装在Double类
public class DistanceUtil private static final double EARTH_RADIUS = 6378137; private static doub