003-文本分析
Posted mjerry
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了003-文本分析相关的知识,希望对你有一定的参考价值。
停用词

1.语料中大量出现
2.没啥大用
3.留着过年嘛?
Tf-idf:关键词提取
《中国的蜜蜂养殖》: 进行词频(Term Frequency,缩写为TF)统计
出现次数最多的词是----“的”、“是”、“在”----这一类最常用的词(停用词)
“中国”、“蜜蜂”、“养殖”这三个词的出现次数一样多,重要性是一样的?
"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见
"逆文档频率"(Inverse Document Frequency,缩写为IDF)
如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性
正是我们所需要的关键词

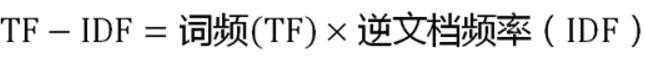
《中国的蜜蜂养殖》:假定该文长度为1000个词,"中国"、"蜜蜂"、"养殖"各出现20次,则这三个词的"词频"(TF)都为0.02
搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数。
包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张
Tf-idf:关键词提取
相似度

相似度
句子A:我喜欢看电视,不喜欢看电影。
句子B:我不喜欢看电视,也不喜欢看电影。
分词:
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
语料库:我,喜欢,看,电视,电影,不,也。
词频:
句子A:我1,喜欢2,看2,电视1,电影1,不1,也0。
句子B:我1,喜欢2,看2,电视1,电影1,不2,也1。
词频向量:
句子A:[1, 2, 2, 1, 1, 1, 0]
句子B:[1, 2, 2, 1, 1, 2, 1]
word2vector
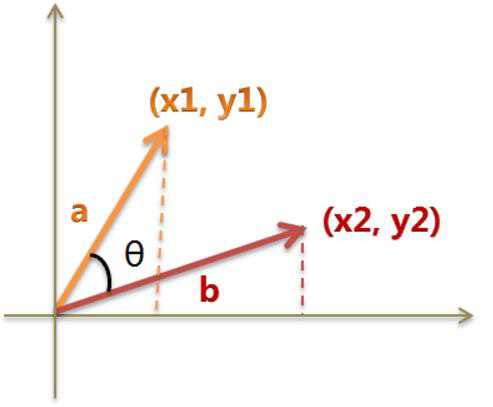
相似度(向量内积)
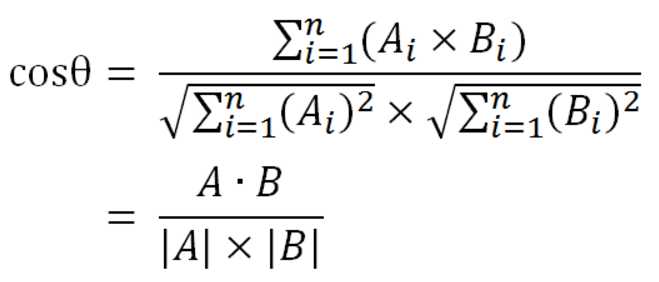
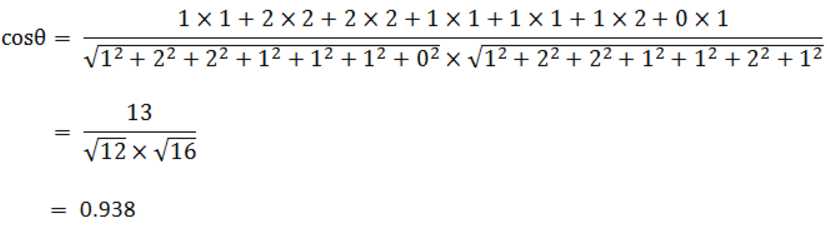
以上是关于003-文本分析的主要内容,如果未能解决你的问题,请参考以下文章