第6天数据类型之元组,字典,集合
Posted huwentao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第6天数据类型之元组,字典,集合相关的知识,希望对你有一定的参考价值。
元组(不可变,有序,多个值)
元组类型就是一个不可变的列表,为什么会有元组呢?因为在我们写程序的过程中可能会出现这样的一个情况,也就是为了防止一些不必要的bug,一些重要的数据别人是可以读取的,但是不能够进行更改,这个时候我们就需要用到元组了。对于列表而言,python中对于元祖的存储相对来说更为存储空间的。(因为它不必再像列表一样维护更改操作了)
既然元组本身就是一个不可变的列表了,那它的除了修改列表的操作之外的一些操作和列表是完全一样的,此处就不再陈述了,但是此处我要说的是元组的不可变究竟指的是什么不可变?例如下面的操作:
tuple1 = (‘a‘, ‘b‘, ‘c‘, [‘a‘, ‘b‘, ‘c‘]) print(tuple1) tuple1[3].append(‘d‘) print(tuple1) 结果: (‘a‘, ‘b‘, ‘c‘, [‘a‘, ‘b‘, ‘c‘]) (‘a‘, ‘b‘, ‘c‘, [‘a‘, ‘b‘, ‘c‘, ‘d‘]) # 不是说元组不可变吗,为什么此处还是可以对元组进行添加数据呢
这个现象的原因是因为无论是列表还是元组存放值得时候并不是把里面的内容直接存放到了列表或者元组中,而是把这些值对应的内存空间放在了元组中,我们通常所说的不改变元组也就是指不改变元组内存储的内存空间地址而已。如上面的例子,tuple1更改的是元组中最后一项列表的值,但是对于列表而言是一个可变的类型,就算是里面的值增加了一个,它的内存地址是不会改变的,因此存在元组中的内存地址也就不会发生改变了。
元组的方法(和列表是一样的)
index取对应的索引值,没有就报错
count,得到对应元素的个数
元组需要注意的地方:元组内如果只有一个内容的话,需要加上逗号,否则就是包含的意思。如下图
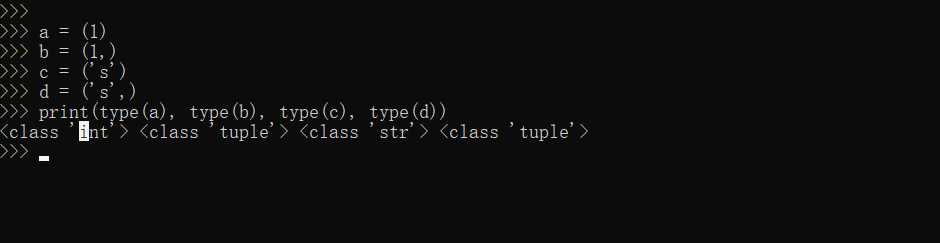
元组练习:
#简单购物车,要求如下: 实现打印商品详细信息,用户输入商品名和购买个数,则将商品名,价格,购买个数加入购物列表,如果输入为空或其他非法输入则要求用户重新输入 msg_dic={ ‘apple‘:10, ‘tesla‘:100000, ‘mac‘:3000, ‘lenovo‘:30000, ‘chicken‘:10, }


‘‘‘ #简单购物车,要求如下: 实现打印商品详细信息,用户输入商品名和购买个数,则将商品名,价格, 购买个数加入购物列表,如果输入为空或其他非法输入则要求用户重新输入 msg_dic={ ‘apple‘:10, ‘tesla‘:100000, ‘mac‘:3000, ‘lenovo‘:30000, ‘chicken‘:10, } ‘‘‘ msg_dic={ ‘apple‘:10, ‘tesla‘:100000, ‘mac‘:3000, ‘lenovo‘:30000, ‘chicken‘:10, } # 购物列表 shop_list = [] for key, value in msg_dic.items(): print(‘{name}, {price} |‘.format(name=key, price=value), end=‘ ‘) print() temp_info = ‘请‘ while True: shop_name = input(temp_info + ‘输入商品名称:‘).strip() if shop_name not in msg_dic: print(‘您输入的商品不存在!‘) temp_info = ‘请重新‘ continue break temp_info = ‘请‘ while True: shop_count = input(temp_info + ‘请输入商品个数:‘).strip() if not shop_count.isdigit(): print(‘您输入的有误!‘) temp_info = ‘请重新‘ continue shop_count = int(shop_count) break shop_list.append((shop_name, shop_count, msg_dic[shop_name])) print(‘您的购物车为:‘) print(shop_list)
字典(可变,多个值,无序)
字典的定义(字典的key必须是不可变类型,value可以是任意类型)
a = {‘name‘: ‘hu‘, ‘age‘: 18} # ==> a = dict({‘name‘: ‘hu‘, ‘age‘: 18})
a = {1 : [], 1.1: [], ‘name‘: [], (1,2,3): []} # 这个是正确的定义方式
a = {1 : [], 1.1: [], ‘name‘: [], (1,2,3): [], [1,2,3]: 1} # 这个是错误的,因为key中有列表,列表是可变类型
字典的转换
a = dict([(‘name‘, ‘hu‘), (‘age‘, 18)]) # 只能转换如下类型的,一个列表或者元组里面包含一个个的小元组的情况,并且小元组里面只有两个值,一个代表key,一个代表value b = dict(((‘name‘, ‘hu‘), (‘age‘, 18))) print(a, b)
字典的取值(因为字典是无序的,因此字典本身是不能通过索引进行取值的,更不能切片)
# 列表是不能通过索引直接赋值的方式添加的,但是字典是可以的
a = {‘name‘: ‘hu‘, ‘age‘: 18} res = a[‘name‘] # 如果有key,就是把值直接取出来 print(res) a[‘sex‘] = ‘male‘ # 如果没有,就是直接在字典中添加key和value print(a)
字典的方法
keys, values, items,对于python2和python3此方法的返回值是不一样的,python3返回的是一个列表的生成器,而python2是直接把字典的key,value已经items直接以列表的形式返回回来了。这对于一些比较大的数据字典而言,python3明显要比python2更加的节省内存。
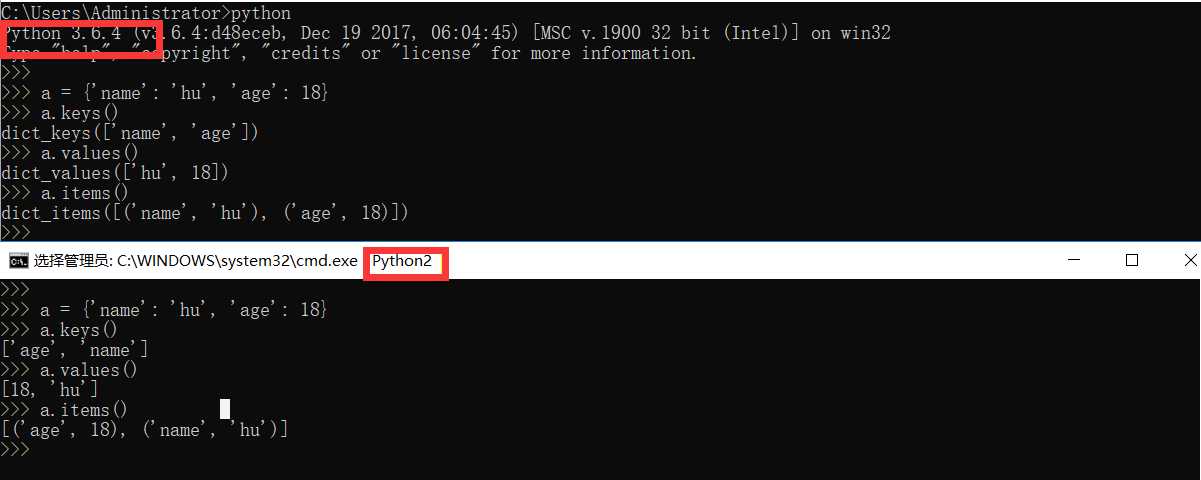
clear, copy函数
a = {‘name‘: ‘hu‘, ‘age‘: 18}
b = a.copy() # 完整的复制一个字典
a.clear() # 把字典给清空掉
print(a, b)
update更新方法
# update方法,update里面的参数可以是字典{},也可以是以下形式的列表[(), ()] # 如果更新的内容原字典中是有的,就直接更新,如果没有,就添加 a = {‘name‘: ‘hu‘, ‘age‘: 18} a.update({‘name‘: ‘agon‘, ‘sex‘: ‘male‘}) print(a) # 结果: # {‘name‘: ‘agon‘, ‘age‘: 18, ‘sex‘: ‘male‘}
setdefault方法
# setdefault有两个参数,第一个参数是key,如果key在原字典中存在,则直接返回原字典对应的key的值 # 如果原字典中key不存在,则添加key到原字典中,value的值为第二个参数,并且返回第二个参数 a = {‘name‘: ‘hu‘, ‘age‘: 18} res = a.setdefault(‘sex‘, None) print(a, res) # 结果: # {‘name‘: ‘hu‘, ‘age‘: 18, ‘sex‘: None} None
pop, popitem删除方法
# pop根据key去删除相应的键值对,返回对应的key的值,如果key不存在会报错 # popitem随机的删除一个键值对,以元组的形式返回这个键值对,如果字典为空也会报错 a = {‘name‘: ‘hu‘, ‘age‘: 18} res1 = a.pop(‘name‘) print(res1) res2 = a.popitem() print(res2) #结果: # hu # (‘age‘, 18)
fromkeys方法
#fromkeys可以通过已经给定的key快速的创建一个初始化的字典 res1 = {}.fromkeys(‘str‘, None) res2 = {}.fromkeys([‘name‘, ‘age‘, ‘sex‘], None) print(res1) print(res2) # 结果 # {‘s‘: None, ‘t‘: None, ‘r‘: None} # {‘name‘: None, ‘age‘: None, ‘sex‘: None}
get方法
# 通过a[‘name‘]也是可以得到字典的值得,但是当key不存在的时候会报错,所以我们一般通过get方法去得到相应的值
a = {‘name‘: ‘hu‘, ‘age‘: 18} res1 = a.get(‘name‘) res2 = a.get(‘sex‘) # 如果字典中不存在,不会报错,会返回一个None print(res1, res2) 结果: hu None
字典练习:
1. 有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中
‘‘‘ 1 有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中 即: {‘k1‘: 大于66的所有值, ‘k2‘: 小于66的所有值} ‘‘‘ a = [11,22,33,44,55,66,77,88,99,90] di = {} for i in a: if i > 66: di.setdefault(‘k1‘, []) di[‘k1‘].append(i) if i < 66: di.setdefault(‘k2‘, []) di[‘k2‘].append(i) print(di)
2. 统计s=‘hello alex alex say hello sb sb‘中每个单词的个数
‘‘‘ 2 统计s=‘hello alex alex say hello sb sb‘中每个单词的个数 结果如:{‘hello‘: 2, ‘alex‘: 2, ‘say‘: 1, ‘sb‘: 2} ‘‘‘ d = {} s = ‘hello alex alex say hello sb sb‘ for word in s.split(): d.setdefault(word, s.count(word)) print(d)
‘‘‘ 2 统计s=‘hello alex alex say hello sb sb‘中每个单词的个数 结果如:{‘hello‘: 2, ‘alex‘: 2, ‘say‘: 1, ‘sb‘: 2} ‘‘‘ d = {} s = ‘hello alex alex say hello sb sb‘ s_set = set(s.split()) for word in s_set: d[word] = s.count(word) print(d)
集合(可变,无序,存多个值)
集合的定义
# 集合定义的过程需要注意的 # 1. 值必须是不可变类型 # 2. 没有重复 # 3. 没有顺序 a = {1, 1.1, ‘str‘, (1, 2)} # ==>a = set({1, 1.1, ‘str‘, (1, 2)})
集合的转换
# 集合的转换过程 # 1.转换的必须是可迭代类型 # 2.转换的值中不能包含有可变类型 a1 = set(‘str[1,2,3]‘) a2 = set((1,2)) a3 = set([1, 2, 3]) # a3 = set([1, 2, [1,2,3]]) # 这个是错误的 a4 = set({‘a‘: 1, ‘b‘: 2, ‘c‘: [1, 2, 3]}) print(a1, a2, a3, a4)
集合运算
# 集合有交集,并集,差集,对称差集,父子关系,相等 pythons = {‘hu‘, ‘zhou‘, ‘zhang‘, ‘li‘, ‘yang‘} linuxs = {‘hu‘, ‘li‘, ‘yang‘, ‘xiao‘, ‘chen‘, ‘ti‘, ‘bai‘} # 交集 print(pythons & linuxs) print(pythons.intersection(linuxs)) # 并集 print(pythons | linuxs) print(pythons.union(linuxs)) # 差集 print(pythons - linuxs) # 在python中但是不在Linux中 print(linuxs - pythons) # 在linux中但是不在python中 print(pythons.difference(linuxs)) print(linuxs.difference(pythons)) # 对称差集 print(pythons ^ linuxs) print(pythons.symmetric_difference(linuxs)) # 相等 print(pythons == linuxs) # 父子 print(pythons >= linuxs) # 判断pythons是否包含linuxs
集合方法
a = {1, 2, 3}
# 添加
a.add(4) # 添加的值如果存在,就不变
print(a)
# 删除
a.pop() # 随机删除
a.remove(3) # 删除元素,必须存在
a.discard(3) # 元素如果存在则删除,如果不存在,就不变
# 更新
b = {1, 4, 5}
a.update(b) # 有则不变,没有则添加
print(a)
res = a.isdisjoint(b) # 如果两个集合没有交集,则返回True,否则Flase
print(res)
集合的练习
1. 第一题
一.关系运算 有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合 pythons={‘alex‘,‘egon‘,‘yuanhao‘,‘wupeiqi‘,‘gangdan‘,‘biubiu‘} linuxs={‘wupeiqi‘,‘oldboy‘,‘gangdan‘} 1. 求出即报名python又报名linux课程的学员名字集合 2. 求出所有报名的学生名字集合 3. 求出只报名python课程的学员名字 4. 求出没有同时这两门课程的学员名字集合
pythons={‘alex‘,‘egon‘,‘yuanhao‘,‘wupeiqi‘,‘gangdan‘,‘biubiu‘}
linuxs={‘wupeiqi‘,‘oldboy‘,‘gangdan‘}
# 1. 求出即报名python又报名linux课程的学员名字集合
print(pythons.intersection(linuxs))
# 2. 求出所有报名的学生名字集合
print(pythons.update(linuxs))
# 3. 求出只报名python课程的学员名字
print(pythons.difference(linuxs))
# 4. 求出没有同时这两门课程的学员名字集合
print(pythons.symmetric_difference(linuxs))
2. 第二题
二.去重 1. 有列表l=[‘a‘,‘b‘,1,‘a‘,‘a‘],列表元素均为可hash类型,去重,得到新列表,且新列表无需保持列表原来的顺序 2.在上题的基础上,保存列表原来的顺序 3.去除文件中重复的行,肯定要保持文件内容的顺序不变 4.有如下列表,列表元素为不可hash类型,去重,得到新列表,且新列表一定要保持列表原来的顺序 l=[ {‘name‘:‘egon‘,‘age‘:18,‘sex‘:‘male‘}, {‘name‘:‘alex‘,‘age‘:73,‘sex‘:‘male‘}, {‘name‘:‘egon‘,‘age‘:20,‘sex‘:‘female‘}, {‘name‘:‘egon‘,‘age‘:18,‘sex‘:‘male‘}, {‘name‘:‘egon‘,‘age‘:18,‘sex‘:‘male‘},
# 1. 有列表l=[‘a‘,‘b‘,1,‘a‘,‘a‘],列表元素均为可hash类型,去重,得到新列表,且新列表无需保持列表原来的顺序 l = [‘a‘, ‘b‘, 1, ‘a‘, ‘a‘] new_l = list(set(l)) print(new_l) # 2.在上题的基础上,保存列表原来的顺序 new_l = [] for l_item in l: if l_item not in new_l: new_l.append(l_item) print(new_l) # 3.去除文件中重复的行,肯定要保持文件内容的顺序不变 # 4.有如下列表,列表元素为不可hash类型,去重,得到新列表,且新列表一定要保持列表原来的顺序 l=[ {‘name‘:‘egon‘,‘age‘:18,‘sex‘:‘male‘}, {‘name‘:‘alex‘,‘age‘:73,‘sex‘:‘male‘}, {‘name‘:‘egon‘,‘age‘:20,‘sex‘:‘female‘}, {‘name‘:‘egon‘,‘age‘:18,‘sex‘:‘male‘}, {‘name‘:‘egon‘,‘age‘:18,‘sex‘:‘male‘}, ] new_l = [] for l_item in l: if l_item not in new_l: new_l.append(l_item) print(new_l)
作业1
打印省、市、县三级菜单
可返回上一级
可随时退出程序
menu = { ‘北京‘: { ‘海淀‘: { ‘五道口‘: { ‘soho‘: {}, ‘网易‘: {}, ‘google‘: {} }, ‘中关村‘: { ‘爱奇艺‘: {}, ‘汽车之家‘: {}, ‘youku‘: {}, }, ‘上地‘: { ‘百度‘: {}, }, }, ‘昌平‘: { ‘沙河‘: { ‘老男孩‘: {}, ‘北航‘: {}, }, ‘天通苑‘: {}, ‘回龙观‘: {}, }, ‘朝阳‘: {}, ‘东城‘: {}, }, ‘上海‘: { ‘闵行‘: { "人民广场": { ‘炸鸡店‘: {} } }, ‘闸北‘: { ‘火车战‘: { ‘携程‘: {} } }, ‘浦东‘: {}, }, ‘山东‘: {}, } ‘‘‘ #要求: 打印省、市、县三级菜单 可返回上一级 可随时退出程序 ‘‘‘ flag = True # 用来控制是否退出程序 while flag: # 第一层 for key in menu: print(key) choice = input(‘第一层>>: ‘).strip() if choice == ‘b‘: continue if choice == ‘q‘: flag = False print(‘退出!‘) break if choice not in menu: print(‘请重新输入!‘) continue while flag: menu_2 = menu[choice] for key in menu_2: print(key) choice2 = input(‘第二层>>: ‘).strip() if choice2 == ‘b‘: break if choice2 == ‘q‘: flag = False print(‘退出!‘) break if choice2 not in menu_2: print(‘请重新输入!‘) continue while flag: menu_3 = menu[choice][choice2] for key in menu_3: print(key) choice3 = input(‘第三层>>: ‘).strip() if choice3 == ‘b‘: break if choice3 == ‘q‘: flag = False print(‘退出!‘) break if choice3 not in menu_3: print(‘请重新输入!‘) continue while flag: menu_4 = menu[choice][choice2][choice3] for key in menu_4: print(key) choice4 = input(‘第四层>>: ‘).strip() if choice4 == ‘b‘: break if choice4 == ‘q‘: flag = False print(‘退出!‘) break if choice4 not in menu_4: print(‘请重新输入!‘) continue
menu = { ‘北京‘:{ ‘海淀‘:{ ‘五道口‘:{ ‘soho‘:{}, ‘网易‘:{}, ‘google‘:{} }, ‘中关村‘:{ ‘爱奇艺‘:{}, ‘汽车之家‘:{}, ‘youku‘:{}, }, ‘上地‘:{ ‘百度‘:{}, }, }, ‘昌平‘:{ ‘沙河‘:{ ‘老男孩‘:{}, ‘北航‘:{}, }, ‘天通苑‘:{}, ‘回龙观‘:{}, }, ‘朝阳‘:{}, ‘东城‘:{}, }, ‘上海‘:{ ‘闵行‘:{ "人民广场":{ ‘炸鸡店‘:{} } }, ‘闸北‘:{ ‘火车战‘:{ ‘携程‘:{} } }, ‘浦东‘:{}, }, ‘山东‘:{}, } layers = [menu, ] while True: # 获取到当前层的数据 current_layers = layers[-1] for key in current_layers: print(key) choice = input(‘>> ‘).strip() # 根据用户的输入判断是哪种情况 if choice == ‘b‘: if len(layers) == 1: continue layers.pop(-1) continue if choice == ‘q‘: print(‘退出!‘) break if choice not in current_layers: print(‘请重新输入!‘) continue if choice in current_layers: layers.append(current_layers[choice])
以上是关于第6天数据类型之元组,字典,集合的主要内容,如果未能解决你的问题,请参考以下文章