曼城新闻情报站Django框架的爬虫
Posted lkd8477604
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了曼城新闻情报站Django框架的爬虫相关的知识,希望对你有一定的参考价值。
前面写了曼城新闻的爬虫脚本,现在把它放到Django框架中来。直接把py文件copy到Django目录下,然后在view里import一下调用就好了。后面想要定时爬新闻也不难。
之前的爬虫脚本没有import lxml也没有报错,但是放到Django后不import一下会报错。
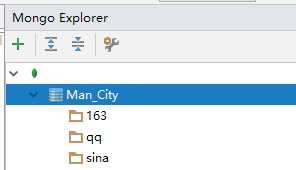
关于Django的创建以及url,static配置就不细说了。由于Mongodb不在Django默认支持范围中,所以setting里要追加这两行
from mongoengine import connect connect(db=‘Man_City‘, host=‘localhost‘, port=27017)
注意看我的Mongodb目录,db不要填错了
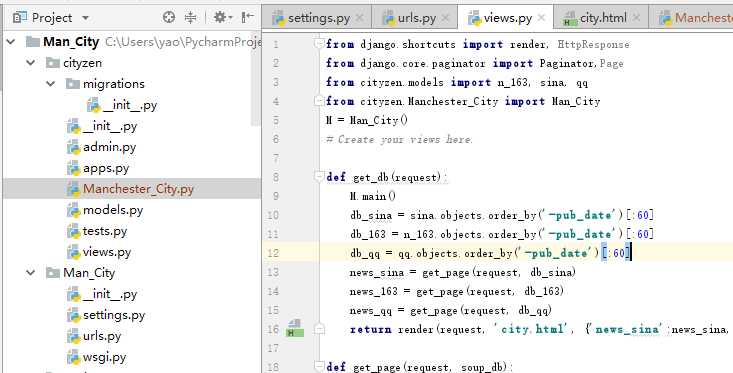
model里建3个类
from django.db import models from mongoengine import * # Create your models here. class n_163(Document): title = StringField(max_length=100) url = StringField(max_length=64) pub_date = StringField(max_length=32) meta={ ‘collection‘: ‘163‘ } class sina(Document): title = StringField(max_length=100) url = StringField(max_length=64) pub_date = StringField(max_length=32) meta={‘collection‘:‘sina‘} class qq(Document): title = StringField(max_length=100) url = StringField(max_length=64) pub_date = StringField(max_length=32) meta={‘collection‘:‘qq‘}
view里面调用数据库
from django.shortcuts import render, HttpResponse from django.core.paginator import Paginator,Page from cityzen.models import n_163, sina, qq from cityzen.Manchester_City import Man_City M = Man_City() # Create your views here. def get_db(request): M.main() #按日期只显示60条新闻 db_sina = sina.objects.order_by(‘-pub_date‘)[:60] db_163 = n_163.objects.order_by(‘-pub_date‘)[:60] db_qq = qq.objects.order_by(‘-pub_date‘)[:60] news_sina = get_page(request, db_sina) news_163 = get_page(request, db_163) news_qq = get_page(request, db_qq) return render(request, ‘city.html‘, {‘news_sina‘:news_sina, ‘news_163‘:news_163, ‘news_qq‘:news_qq}) def get_page(request, soup_db): #Django自带的翻页功能,每页显示10条新闻 page = request.GET.get(‘page‘, 1) paginator = Paginator(soup_db, 10) page_loaded = paginator.page(page) return page_loaded
后台的功能基本完成了,前端我用的是Semantic UI,把需要用到的3个文件放到tempalates目录下,就像用jquery那样调用就好了,官网上有很多实用的模版,抄过来改改就能用。
city.htm
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <script src="/static/Semantic-UI-CSS-master/jquery-1.11.3.min.js"></script> <link rel="stylesheet" href="/static/Semantic-UI-CSS-master/semantic.css"> <script src="/static/Semantic-UI-CSS-master/semantic.js"></script> </head> <body> <div style="background: url(/static/man_bg.jpg) no-repeat"> <h1 class="ui header center aligned">曼城情报站</h1> <div class="ui top attached tabular menu"> <a class="active item" data-tab="first">新闻</a> <a class="item" data-tab="second">赛后数据</a> <a class="item" data-tab="third">排名</a> </div> <div class="ui bottom attached active tab segment" data-tab="first"> {# 新闻#} <div class="ui equal width grid"> <div class="column"> <div class="ui segment" data-tab="news_first"><img src="/static/sina_sport.PNG" style="margin: auto" class="small"></div> </div> <div class="column"> <div class="ui segment" data-tab="news_second" id="163"><img src="/static/163_sport.PNG" style="margin: auto" class="small"></div> </div> <div class="column"> <div class="ui segment" data-tab="news_third" id="qq"><img src="/static/qq.PNG" style="margin: auto" class="small"></div> </div> </div> <div class="ui bottom attached active tab segment" data-tab="news_first" > {# 新浪新闻内容#} <ul> {% for item in news_sina %} <span><a href="{{ item.url }}">{{ item.title }} {{ item.pub_date }}</a></span> {# semantic ui分割条#} <div class="ui horizontal divider"></div> {% endfor %} </ul> {# 翻页div#} <div class="pagination"> {% if news_sina.has_previous %} <a href="?page={{ news_sina.previous_page_number }}">pre</a> {% endif %} <span>{{ news_sina.number }} of {{ news_sina.paginator.num_pages }}</span> {% if news_sina.has_next %} <a href="?page={{ news_sina.next_page_number }}">Next</a> {% endif %} </div> </div> <div class="ui bottom attached tab segment" data-tab="news_second"> {# 网易新闻内容#} <ul> {% for item in news_163 %} <span><a href="{{ item.url }}">{{ item.title }} {{ item.pub_date }}</a></span> <div class="ui horizontal divider"></div> {% endfor %} </ul> {# 翻页div#} <div class="pagination"> {% if news_163.has_previous %} <a href="?page={{ news_163.previous_page_number }}">pre</a> {% endif %} <span>{{ news_163.number }} of {{ news_163.paginator.num_pages }}</span> {% if news_163.has_next %} <a href="?page={{ news_163.next_page_number }}">Next</a> {% endif %} </div> </div> <div class="ui bottom attached tab segment" data-tab="news_third"> {# 腾讯新闻内容 #} <ul> {% for item in news_qq %} <span><a href="{{ item.url }}">{{ item.title }} {{ item.pub_date }}</a></span> <div class="ui horizontal divider"></div> {% endfor %} </ul> {# 翻页div#} <div class="pagination"> {% if news_qq.has_previous %} <a href="?page={{ news_qq.previous_page_number }}">pre</a> {% endif %} <span>{{ news_qq.number }} of {{ news_qq.paginator.num_pages }}</span> {% if news_qq.has_next %} <a href="?page={{ news_qq.next_page_number }}">Next</a> {% endif %} </div> </div> </div> <div class="ui bottom attached tab segment" data-tab="second">赛后数据内容</div> <div class="ui bottom attached tab segment" data-tab="third">排名内容</div> <h4 class="ui horizontal inverted divider" style="color: black">Design by John </h4> </div> <script> $(‘.menu .item‘).tab(); $(‘.column .segment‘).tab() $(‘#163‘).click(function () { }) </script> </body> </html>
初步完成的成果如下。
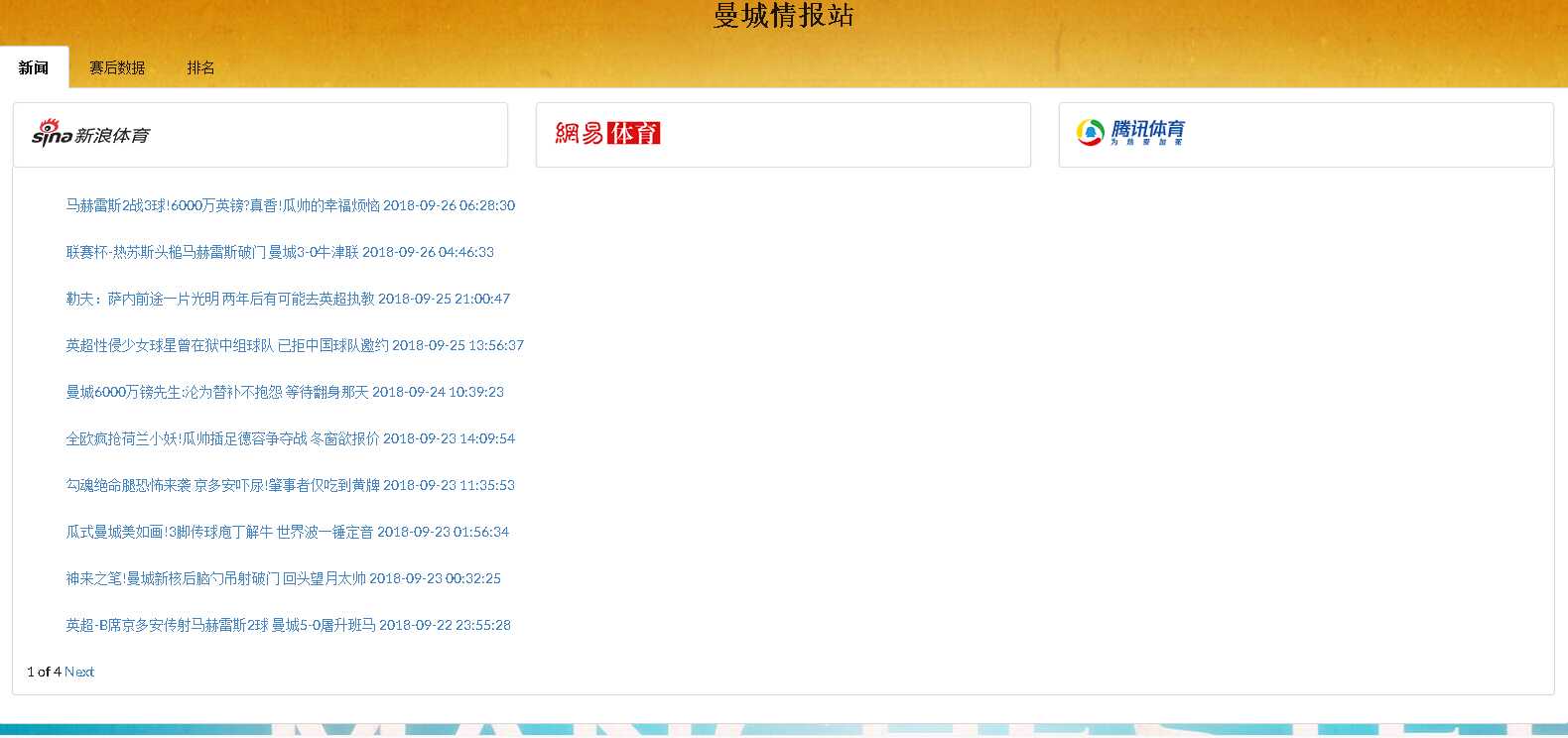
总结:
用Semantic UI的确比自己写前端代码快且美观多了,不过只是用到了其中小部分内容,还有很多模块需要熟悉。对于爬取的数据没怎么处理,只是对日期做了数据清洗,把字符串格式的日期转化为可排序的日期格式排列,由于是存入数据前就做了这些处理,所以后面调取使用就方便多了。做分页的时候是直接用的Django自带的分页功能,page会直接显示在网页上面,然后在三个新闻站点上切换的时候页码也会随便变化,这让人不爽,所以后面会改用ajax翻页。还有曼城赛后数据分析打算做成图表的形式,再加入英超排行榜就差不多完成一个雏形了。
以上是关于曼城新闻情报站Django框架的爬虫的主要内容,如果未能解决你的问题,请参考以下文章