教材学习内容总结
第五章
队列
1.队列是先进先出的数据结构(FIFO)与栈不同,队列的两端可分别进行操作
2.first与front相同,返回首段的值
3.API中的队列方法,有add,element,offer,peek,poll,remove
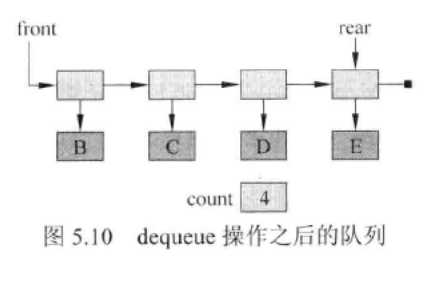
4.用链表实现队列时,enqueue和dequeue的算法复杂度均为O(1)
5.用数组实现队列时,enqueue和dequeue的算法复杂度均为O(n),因为无论将索引值定为头或者尾,插入或删除时,总会使得所有元素位置发生改变。
6.非环形数组实现的元素位移,将产生O(n)的复杂度。
7.由数组实现的队列中,rear和栈中的top类似,表示队列中的元素个数,以及数组中下一个空闲单元。
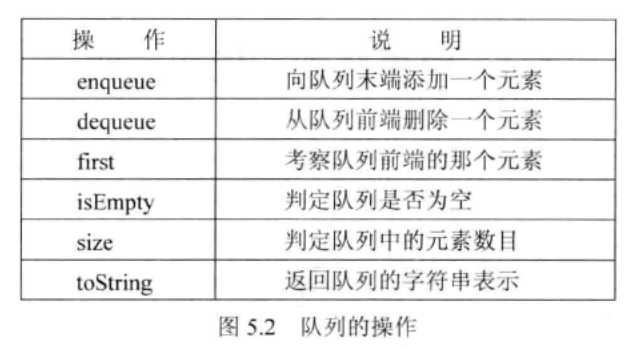
用数组实现队列
- 基于数组的队列实现策略就是将队列的某一端(比如前端)固定在数组的索引0处。所有元素会不间断地存放在数组中。
- 与ArrayStack实现中的top变量类似,整型变量rear用于表明数组中的下一个空闲单元。
- 注意:rear还表示了队列中的元素数目。
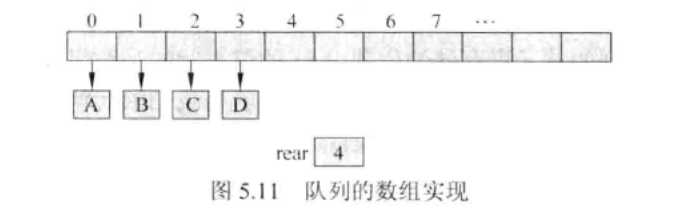
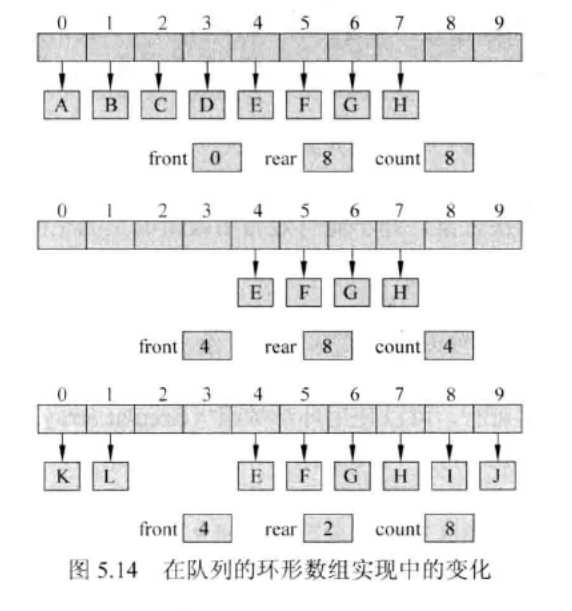
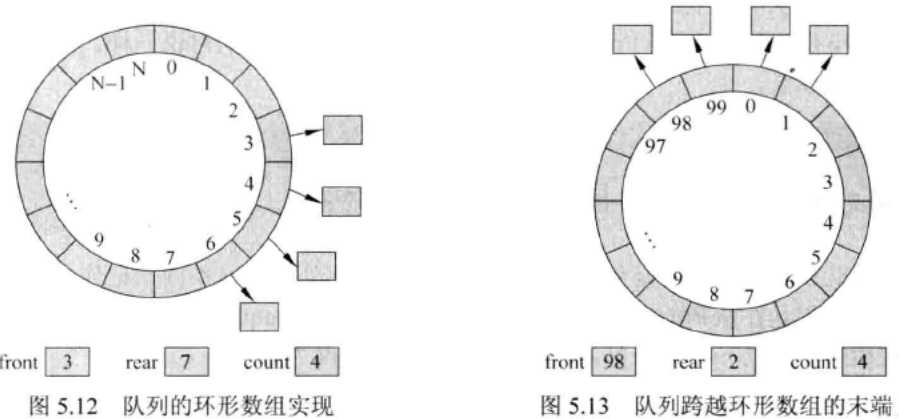
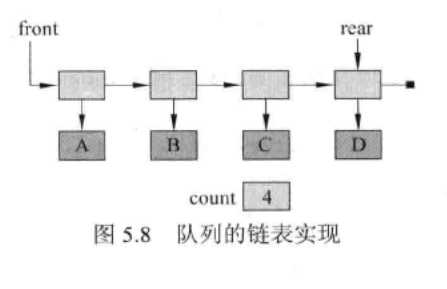
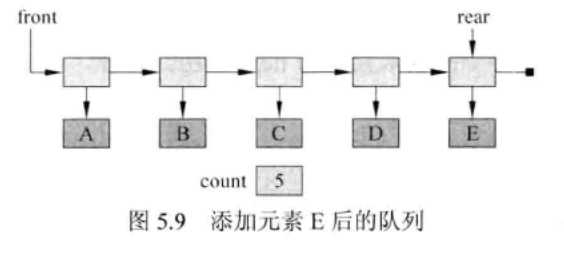
用链表实现队列
- 除了一个指向链表首元素的引用(head)之外,还需要跟踪另一个指向链表末元素的引用(tail),还要用一个整型变量count来跟踪队列中的元素数目。
- 往链表前端添加新结点,应该将该新结点的next指针设置为指向链表的head变量,把head变量设置为指向新结点。
- 往链表的末端添加新结点,应该将把链表末端结点的next指针设置为指向新结点,然后把链表的tail设置为指向新结点。
教材学习中的问题和解决过程
- 问题1:dequeue的操作复杂度为何为O(1).
-
问题1解决方案:当调用 .dequeue() 时,会从序列中删除下一个函数,然后执行它。该函数反过来会(直接或间接地)引发对 .dequeue() 的调用,这样序列才能继续下去。——摘自百度百科
- (https://www.cnblogs.com/wust221/p/5396263.html)1.每次 新元素进栈的时候,栈里面的元素需要排序2.让最小的或者最大的元素位于栈顶,这样就可以在O(1)时间内获得最小或者最大的值了,3.上面的想法 不能保证,进栈(进了队列)之后 ,出去的元素的顺序,因此只有一个栈是不行的4.要有个保存最小或者最大的元素,每次进栈的时候,跟这个数比较,存起来,5.但是有个问题,就是你最大的元素(或者最小的元素出去)了之后,你该怎么去更新这个值呢,6.就是只 维持一个变量是不够的7.最小元素或者最大元素出栈之后,要能够保证次小元素立马填补现在这个位置,也就是说,我们需要把次小元素和最小元素都保存起来,放到另外的一个辅助栈里面。
代码调试中的问题和解决过程
具体没有什么特别的问题,只有一些代码的不规范问题。(大小写已经成为习惯,希望我不会被枪杀。)
码云链接