整理Java 8新特性总结
Posted jackpothan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了整理Java 8新特性总结相关的知识,希望对你有一定的参考价值。
闲语:
介绍
毫无疑问,Java 8发行版是自Java 5(发行于2004,已经过了相当一段时间了)以来最具革命性的版本。Java 8 为Java语言、编译器、类库、开发工具与JVM(Java虚拟机)带来了大量新特性。在这篇文章中,我们将一一探索这些变化,并用真实的例子说明它们适用的场景。主要由以下几部分组成,它们分别涉及到Java平台某一特定方面的内容:
- Java语言
- 编译器
- 类库
- 工具
- Java运行时(JVM)
Java语言的新特性
Lambda表达式与Functional接口
Lambda表达式(也称为闭包)是整个Java 8发行版中最受期待的在Java语言层面上的改变,Lambda允许把函数作为一个方法的参数(函数作为参数传递进方法中),或者把代码看成数据:函数式程序员对这一概念非常熟悉。在JVM平台上的很多语言(Groovy,Scala,……)从一开始就有Lambda,但是Java程序员不得不使用毫无新意的匿名类来代替lambda。
关于Lambda设计的讨论占用了大量的时间与社区的努力。可喜的是,最终找到了一个平衡点,使得可以使用一种即简洁又紧凑的新方式来构造Lambdas。
在最简单的形式中,一个lambda可以由用逗号分隔的参数列表、–>符号与函数体三部分表示。例如:
Arrays.asList( "a", "b", "d" ).forEach( e -> System.out.println( e ) );
请注意参数e的类型是由编译器推测出来的。同时,你也可以通过把参数类型与参数包括在括号中的形式直接给出参数的类型:
Arrays.asList( "a", "b", "d" ).forEach( ( String e ) -> System.out.println( e ) );
在某些情况下lambda的函数体会更加复杂,这时可以把函数体放到在一对花括号中,就像在Java中定义普通函数一样。例如:
Arrays.asList( "a", "b", "d" ).forEach( e -> {
System.out.print( e );
} );
Lambda可以引用类的成员变量与局部变量(如果这些变量不是final的话,它们会被隐含的转为final,这样效率更高)。例如,下面两个代码片段是等价的:
String separator = ","; Arrays.asList( "a", "b", "d" ).forEach( ( String e ) -> System.out.print( e + separator ) );
和:
final String separator = ","; Arrays.asList( "a", "b", "d" ).forEach( ( String e ) -> System.out.print( e + separator ) );
Lambda可能会返回一个值。返回值的类型也是由编译器推测出来的。如果lambda的函数体只有一行的话,那么没有必要显式使用return语句。下面两个代码片段是等价的:
Arrays.asList( "a", "b", "d" ).sort( ( e1, e2 ) -> e1.compareTo( e2 ) );
和:
Arrays.asList( "a", "b", "d" ).sort( ( e1, e2 ) -> { int result = e1.compareTo( e2 ); return result; } );
语言设计者投入了大量精力来思考如何使现有的函数友好地支持lambda。最终采取的方法是:增加函数式接口的概念。函数式接口就是一个具有一个方法的普通接口。像这样的接口,可以被隐式转换为lambda表达式。java.lang.Runnable与java.util.concurrent.Callable是函数式接口最典型的两个例子。在实际使用过程中,函数式接口是容易出错的:如有某个人在接口定义中增加了另一个方法,这时,这个接口就不再是函数式的了,并且编译过程也会失败。为了克服函数式接口的这种脆弱性并且能够明确声明接口作为函数式接口的意图,Java 8增加了一种特殊的注解@FunctionalInterface(Java 8中所有类库的已有接口都添加了@FunctionalInterface注解)。让我们看一下这种函数式接口的定义:
@FunctionalInterface public interface Functional { void method(); }
需要记住的一件事是:默认方法与静态方法并不影响函数式接口的契约,可以任意使用:
@FunctionalInterface public interface FunctionalDefaultMethods { void method(); default void defaultMethod() { } }
Lambda是Java 8最大的卖点。它具有吸引越来越多程序员到Java平台上的潜力,并且能够在纯Java语言环境中提供一种优雅的方式来支持函数式编程。更多详情可以参考官方文档。
接口的默认方法和静态方法
Java 8使用两个新概念扩展了接口的含义:默认方法和静态方法。默认方法使得接口有点类似traits,不过要实现的目标不一样。默认方法使得开发者可以在 不破坏二进制兼容性的前提下,往现存接口中添加新的方法,即不强制那些实现了该接口的类也同时实现这个新加的方法。
默认方法和抽象方法之间的区别在于抽象方法需要实现,而默认方法不需要。接口提供的默认方法会被接口的实现类继承或者覆写,例子代码如下:
private interface Defaulable { // Interfaces now allow default methods, the implementer may or // may not implement (override) them. default String notRequired() { return "Default implementation"; } } private static class DefaultableImpl implements Defaulable { } private static class OverridableImpl implements Defaulable { @Override public String notRequired() { return "Overridden implementation"; } }
Defaulable接口使用关键字default定义了一个默认方法notRequired()。DefaultableImpl类实现了这个接口,同时默认继承了这个接口中的默认方法;OverridableImpl类也实现了这个接口,但覆写了该接口的默认方法,并提供了一个不同的实现。
Java 8带来的另一个有趣的特性是在接口中可以定义静态方法,例子代码如下:
private interface DefaulableFactory { // Interfaces now allow static methods static Defaulable create( Supplier< Defaulable > supplier ) { return supplier.get(); } }
下面的代码片段整合了默认方法和静态方法的使用场景:
public static void main( String[] args ) { Defaulable defaulable = DefaulableFactory.create( DefaultableImpl::new ); System.out.println( defaulable.notRequired() ); defaulable = DefaulableFactory.create( OverridableImpl::new ); System.out.println( defaulable.notRequired() ); } ------------ 输出结果: Default implementation Overridden implementation
由于JVM上的默认方法的实现在字节码层面提供了支持,因此效率非常高。默认方法允许在不打破现有继承体系的基础上改进接口。该特性在官方库中的应用是:给java.util.Collection接口添加新方法,如stream()、parallelStream()、forEach()和removeIf()等等。
尽管默认方法有这么多好处,但在实际开发中应该谨慎使用:在复杂的继承体系中,默认方法可能引起歧义和编译错误。如果你想了解更多细节,可以参考官方文档。
方法引用
方法引用使得开发者可以直接引用现存的方法、Java类的构造方法或者实例对象。方法引用和Lambda表达式配合使用,使得java类的构造方法看起来紧凑而简洁,没有很多复杂的模板代码。
看下面Car类是不同方法引用的例子,可以帮助读者区分四种类型的方法引用。
public static class Car { public static Car create( final Supplier< Car > supplier ) { return supplier.get(); } public static void collide( final Car car ) { System.out.println( "Collided " + car.toString() ); } public void follow( final Car another ) { System.out.println( "Following the " + another.toString() ); } public void repair() { System.out.println( "Repaired " + this.toString() ); } }
第一种方法引用的类型是构造器引用,语法是Class::new,或者更一般的形式:Class<T>::new。注意:这个构造器没有参数。
final Car car = Car.create( Car::new ); final List< Car > cars = Arrays.asList( car );
第二种方法引用的类型是静态方法引用,语法是Class::static_method。注意:这个方法接受一个Car类型的参数。
cars.forEach( Car::collide );
第三种方法引用的类型是某个类的成员方法的引用,语法是Class::method,注意,这个方法没有定义入参:
cars.forEach( Car::repair );
第四种方法引用的类型是某个实例对象的成员方法的引用,语法是instance::method。注意:这个方法接受一个Car类型的参数:
final Car police = Car.create( Car::new ); cars.forEach( police::follow );
运行上述例子,可以在控制台看到如下输出(Car实例可能不同):
Collided [email protected]a81197d
Repaired [email protected]a81197d
Following the [email protected]a81197d
关于方法引用的更多详情请参考官方文档。
重复注解
自从Java 5引入了注解机制,这一特性就变得非常流行并且广为使用。然而,使用注解的一个限制是相同的注解在同一位置只能声明一次,不能声明多次。Java 8打破了这条规则,引入了重复注解机制,这样相同的注解可以在同一地方声明多次。
重复注解机制本身必须用@Repeatable注解。事实上,这并不是语言层面上的改变,更多的是编译器的技巧,底层的原理保持不变。让我们看一个快速入门的例子:
package com.javacodegeeks.java8.repeatable.annotations; import java.lang.annotation.ElementType; import java.lang.annotation.Repeatable; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; public class RepeatingAnnotations { @Target( ElementType.TYPE ) @Retention( RetentionPolicy.RUNTIME ) public @interface Filters { Filter[] value(); } @Target( ElementType.TYPE ) @Retention( RetentionPolicy.RUNTIME ) @Repeatable( Filters.class ) public @interface Filter { String value(); }; @Filter( "filter1" ) @Filter( "filter2" ) public interface Filterable { } public static void main(String[] args) { for( Filter filter: Filterable.class.getAnnotationsByType( Filter.class ) ) { System.out.println( filter.value() ); } } }
--------------
输出结果:
filter1
filter2
正如我们看到的,这里有个使用@Repeatable( Filters.class )注解的注解类Filter,Filters仅仅是Filter注解的数组,但Java编译器并不想让程序员意识到Filters的存在。这样,接口Filterable就拥有了两次Filter(并没有提到Filter)注解。
同时,反射相关的API提供了新的函数getAnnotationsByType()来返回重复注解的类型(请注意Filterable.class.getAnnotation( Filters.class )经编译器处理后将会返回Filters的实例)。更多详情请参考官方文档
更好的类型推测机制
Java 8在类型推测方面有了很大的提高。在很多情况下,编译器可以推测出确定的参数类型,这样就能使代码更整洁。让我们看一个例子:
package com.javacodegeeks.java8.type.inference; public class Value< T > { public static< T > T defaultValue() { return null; } public T getOrDefault( T value, T defaultValue ) { return ( value != null ) ? value : defaultValue; } }
这里是Value< String >类型的用法。
package com.javacodegeeks.java8.type.inference; public class TypeInference { public static void main(String[] args) { final Value< String > value = new Value<>(); value.getOrDefault( "22", Value.defaultValue() ); } }
Value.defaultValue()的参数类型可以被推测出,所以就不必明确给出。在Java 7中,相同的例子将不会通过编译,正确的书写方式是 Value.< String >defaultValue()。
扩展注解的支持
Java 8扩展了注解的上下文。现在几乎可以为任何东西添加注解:局部变量、泛型类、父类与接口的实现,就连方法的异常也能添加注解。下面演示几个例子:
package com.javacodegeeks.java8.annotations; import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; import java.util.ArrayList; import java.util.Collection; public class Annotations { @Retention( RetentionPolicy.RUNTIME ) @Target( { ElementType.TYPE_USE, ElementType.TYPE_PARAMETER } ) public @interface NonEmpty { } public static class Holder< @NonEmpty T > extends @NonEmpty Object { public void method() throws @NonEmpty Exception { } } @SuppressWarnings( "unused" ) public static void main(String[] args) { final Holder< String > holder = new @NonEmpty Holder< String >(); @NonEmpty Collection< @NonEmpty String > strings = new ArrayList<>(); } }
ElementType.TYPE_USE和ElementType.TYPE_PARAMETER是两个新添加的用于描述适当的注解上下文的元素类型。在Java语言中,注解处理API也有小的改动来识别新增的类型注解。
Java编译器的新特性
参数名称
为了在运行时获得Java程序中方法的参数名称,老一辈的Java程序员必须使用不同方法,例如Paranamer liberary。Java 8终于将这个特性规范化,在语言层面(使用反射API和Parameter.getName()方法)和字节码层面(使用新的javac编译器以及-parameters参数)提供支持。
package com.javacodegeeks.java8.parameter.names; import java.lang.reflect.Method; import java.lang.reflect.Parameter; public class ParameterNames { public static void main(String[] args) throws Exception { Method method = ParameterNames.class.getMethod( "main", String[].class ); for( final Parameter parameter: method.getParameters() ) { System.out.println( "Parameter: " + parameter.getName() ); } } }
在Java 8中这个特性是默认关闭的,因此如果不带-parameters参数编译上述代码并运行,则会输出如下结果:
Parameter: arg0
如果带-parameters参数,则会输出如下结果(正确的结果):
Parameter: args
如果你使用Maven进行项目管理,则可以在maven-compiler-plugin编译器的配置项中配置-parameters参数:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<compilerArgument>-parameters</compilerArgument>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
Java 类库的新特性
Java 8 通过增加大量新类,扩展已有类的功能的方式来改善对并发编程、函数式编程、日期/时间相关操作以及其他更多方面的支持。
Optional类
到目前为止,臭名昭著的空指针异常是导致Java应用程序失败的最常见原因。以前,为了解决空指针异常,Google公司著名的Guava项目引入了Optional类,Guava通过使用检查空值的方式来防止代码污染,它鼓励程序员写更干净的代码。受到Google Guava的启发,Optional类已经成为Java 8类库的一部分。
- Optional 类的引入很好的解决空指针异常。
- Optional 类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
- Optional 是个容器:它可以保存类型T的值,或者仅仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测。
更多详情请参考官方文档。
我们下面用两个小例子来演示如何使用Optional类:一个允许为空值,一个不允许为空值。
Optional< String > fullName = Optional.ofNullable( null ); System.out.println( "Full Name is set? " + fullName.isPresent() ); System.out.println( "Full Name: " + fullName.orElseGet( () -> "[none]" ) ); System.out.println( fullName.map( s -> "Hey " + s + "!" ).orElse( "Hey Stranger!" ) );
-----
输出结果:
Full Name is set? false
Full Name: [none]
Hey Stranger!
如果Optional类的实例为非空值的话,isPresent()返回true,否从返回false。为了防止Optional为空值,orElseGet()方法通过回调函数来产生一个默认值。map()函数对当前Optional的值进行转化,然后返回一个新的Optional实例。orElse()方法和orElseGet()方法类似,但是orElse接受一个默认值而不是一个回调函数。
让我们来看看另一个例子:Optional< String > firstName = Optional.of( "Tom" );
System.out.println( "First Name is set? " + firstName.isPresent() ); System.out.println( "First Name: " + firstName.orElseGet( () -> "[none]" ) ); System.out.println( firstName.map( s -> "Hey " + s + "!" ).orElse( "Hey Stranger!" ) ); System.out.println(); ------ 输出结果: First Name is set? true First Name: Tom Hey Tom!
更多详情请参考官方文档
Stream类
最新添加的Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中。这是目前为止对Java类库最好的补充,因为Stream API可以极大提供Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
Stream API极大简化了集合框架的处理(但它的处理的范围不仅仅限于集合框架的处理,这点后面我们会看到)。让我们以一个简单的Task类为例进行介绍:
public class Streams { private enum Status { OPEN, CLOSED }; private static final class Task { private final Status status; private final Integer points; Task( final Status status, final Integer points ) { this.status = status; this.points = points; } public Integer getPoints() { return points; } public Status getStatus() { return status; } @Override public String toString() { return String.format( "[%s, %d]", status, points ); } } }
Task类有一个分数的概念(或者说是伪复杂度),其次是还有一个值可以为OPEN或CLOSED的状态.让我们引入一个Task的小集合作为演示例子:
final Collection< Task > tasks = Arrays.asList( new Task( Status.OPEN, 5 ), new Task( Status.OPEN, 13 ), new Task( Status.CLOSED, 8 ) );
我们下面要讨论的第一个问题是所有状态为OPEN的任务一共有多少分数?在Java 8以前,一般的解决方式用foreach循环,但是在Java 8里面我们可以使用stream:一串支持连续、并行聚集操作的元素。
// Calculate total points of all active tasks using sum() final long totalPointsOfOpenTasks = tasks .stream() .filter( task -> task.getStatus() == Status.OPEN ) .mapToInt( Task::getPoints ) .sum(); System.out.println( "Total points: " + totalPointsOfOpenTasks );
-------
输出结果:
Total points: 18
这里有几个注意事项。第一,task集合被转换化为其相应的stream表示。然后,filter操作过滤掉状态为CLOSED的task。下一步,mapToInt操作通过Task::getPoints这种方式调用每个task实例的getPoints方法把Task的stream转化为Integer的stream。最后,用sum函数把所有的分数加起来,得到最终的结果。
在继续讲解下面的例子之前,关于stream有一些需要注意的地方(详情在这里).stream操作被分成了中间操作与最终操作这两种。
中间操作返回一个新的stream对象。中间操作总是采用惰性求值方式,运行一个像filter这样的中间操作实际上没有进行任何过滤,相反它在遍历元素时会产生了一个新的stream对象,这个新的stream对象包含原始stream
中符合给定谓词的所有元素。
像forEach、sum这样的最终操作可能直接遍历stream,产生一个结果或副作用。当最终操作执行结束之后,stream管道被认为已经被消耗了,没有可能再被使用了。在大多数情况下,最终操作都是采用及早求值方式,及早完成底层数据源的遍历。
stream另一个有价值的地方是能够原生支持并行处理。让我们来看看这个算task分数和的例子。
// Calculate total points of all tasks final double totalPoints = tasks .stream() .parallel() .map( task -> task.getPoints() ) // or map( Task::getPoints ) .reduce( 0, Integer::sum ); System.out.println( "Total points (all tasks): " + totalPoints );
---------
输出结果:
Total points (all tasks): 26.0
这个例子和第一个例子很相似,但这个例子的不同之处在于这个程序是并行运行的,其次使用reduce方法来算最终的结果。
经常会有这个一个需求:我们需要按照某种准则来对集合中的元素进行分组。Stream也可以处理这样的需求,下面是一个例子:
// Group tasks by their status final Map< Status, List< Task > > map = tasks .stream() .collect( Collectors.groupingBy( Task::getStatus ) ); System.out.println( map );
--------
输出结果:
{CLOSED=[[CLOSED, 8]], OPEN=[[OPEN, 5], [OPEN, 13]]}
让我们来计算整个集合中每个task分数(或权重)的平均值来结束task的例子。
// Calculate the weight of each tasks (as percent of total points) final Collection< String > result = tasks .stream() // Stream< String > .mapToInt( Task::getPoints ) // IntStream .asLongStream() // LongStream .mapToDouble( points -> points / totalPoints ) // DoubleStream .boxed() // Stream< Double > .mapToLong( weigth -> ( long )( weigth * 100 ) ) // LongStream .mapToObj( percentage -> percentage + "%" ) // Stream< String> .collect( Collectors.toList() ); // List< String > System.out.println( result );
--------
输出结果;
[19%, 50%, 30%]
最后,就像前面提到的,Stream API不仅仅处理Java集合框架。像从文本文件中逐行读取数据这样典型的I/O操作也很适合用Stream API来处理。下面用一个例子来应证这一点。
final Path path = new File( filename ).toPath(); try( Stream< String > lines = Files.lines( path, StandardCharsets.UTF_8 ) ) { lines.onClose( () -> System.out.println("Done!") ).forEach( System.out::println ); }
对一个stream对象调用onClose方法会返回一个在原有功能基础上新增了关闭功能的stream对象,当对stream对象调用close()方法时,与关闭相关的处理器就会执行。
Stream API、Lambda表达式与方法引用在接口默认方法与静态方法的配合下是Java 8对现代软件开发范式的回应。更多详情请参考官方文档。
Date/Time API (JSR 310)
Java 8通过发布新的Date-Time API (JSR 310)来进一步加强对日期与时间的处理。对日期与时间的操作一直是Java程序员最痛苦的地方之一,标准的 java.util.Date以及后来的java.util.Calendar一点没有改善这种情况(可以这么说,它们一定程度上更加复杂),
这种情况直接导致了Joda-Time——一个可替换标准日期/时间处理且功能非常强大的Java API的诞生。Java 8新的Date-Time API (JSR 310)在很大程度上受到Joda-Time的影响,并且吸取了其精髓。新的java.time包涵盖了所有处理日期,时间,日期/时间,时区,时刻(instants),过程(during)与时钟(clock)的操作。在设计新版API时,十分注重与旧版API的兼容性:不允许有任何的改变(从java.util.Calendar中得到的深刻教训)。如果需要修改,会返回这个类的一个新实例。
让我们用例子来看一下新版API主要类的使用方法。第一个是Clock类,它通过指定一个时区,然后就可以获取到当前的时刻,日期与时间。Clock可以替换System.currentTimeMillis()与TimeZone.getDefault()。
// Get the system clock as UTC offset final Clock clock = Clock.systemUTC(); System.out.println( clock.instant() ); System.out.println( clock.millis() ); ------- 输出结果: 2018-09-25T10:06:53.963Z 1537870014196
我们需要关注的其他类是LocaleDate与LocalTime。LocaleDate只持有ISO-8601格式且无时区信息的日期部分。相应的,LocaleTime只持有ISO-8601格式且无时区信息的时间部分。LocaleDate与LocalTime都可以从Clock中得到。
// Get the local date and local time final Clock clock = Clock.systemUTC(); final LocalDate date = LocalDate.now();final LocalDate dateFromClock = LocalDate.now( clock ); System.out.println( date ); System.out.println( dateFromClock ); // Get the local date and local time final LocalTime time = LocalTime.now(); final LocalTime timeFromClock = LocalTime.now( clock ); System.out.println( time ); System.out.println( timeFromClock ); --------- 输出结果: 2018-09-25 2018-09-25 18:08:32.543 10:08:32.543
LocaleDateTime把LocaleDate与LocaleTime的功能合并起来,它持有的是ISO-8601格式无时区信息的日期与时间。下面是一个快速入门的例子。
// Get the local date/time final LocalDateTime datetime = LocalDateTime.now(); final LocalDateTime datetimeFromClock = LocalDateTime.now( clock ); System.out.println( datetime ); System.out.println( datetimeFromClock ); -------- 输出结果: 2018-09-25T18:12:09.071 2018-09-25T10:12:09.071
如果你需要特定时区的日期/时间,那么ZonedDateTime是你的选择。它持有ISO-8601格式具具有时区信息的日期与时间。下面是一些不同时区的例子:
// Get the zoned date/time final ZonedDateTime zonedDatetime = ZonedDateTime.now(); final ZonedDateTime zonedDatetimeFromClock = ZonedDateTime.now( clock ); final ZonedDateTime zonedDatetimeFromZone = ZonedDateTime.now( ZoneId.of( "America/Los_Angeles" ) ); System.out.println( zonedDatetime ); System.out.println( zonedDatetimeFromClock ); System.out.println( zonedDatetimeFromZone ); -------- 输出结果: 2018-09-25T18:14:15.541+08:00[Asia/Shanghai] 2018-09-25T10:14:15.541Z 2018-09-25T03:14:15.545-07:00[America/Los_Angeles]
最后,让我们看一下Duration类:在秒与纳秒级别上的一段时间。Duration使计算两个日期间的不同变的十分简单。下面让我们看一个这方面的例子。
final LocalDateTime from = LocalDateTime.of( 2017, Month.September, 25, 0, 0, 0 ); final LocalDateTime to = LocalDateTime.of( 2018, Month.September, 25, 23, 59, 59 ); final Duration duration = Duration.between( from, to ); System.out.println( "Duration in days: " + duration.toDays() ); System.out.println( "Duration in hours: " + duration.toHours() ); ----------- 输出结果: Duration in days: 365 Duration in hours: 8783
上面的例子计算了两个日期2017年9月25号与2018年9月25号之间的过程。
对Java 8在日期/时间API的改进整体印象是非常非常好的。一部分原因是因为它建立在“久战杀场”的Joda-Time基础上,另一方面是因为用来大量的时间来设计它,并且这次程序员的声音得到了认可。更多详情请参考官方文档。
javascript引擎Nashorn
Nashorn,一个新的JavaScript引擎随着Java 8一起公诸于世,它允许在JVM上开发运行某些JavaScript应用。Nashorn就是javax.script.ScriptEngine的另一种实现,并且它们俩遵循相同的规则,允许Java与JavaScript相互调用。下面看一个例子:
ScriptEngineManager manager = new ScriptEngineManager(); ScriptEngine engine = manager.getEngineByName( "JavaScript" ); System.out.println( engine.getClass().getName() ); System.out.println( "Result:" + engine.eval( "function f() { return 1; }; f() + 1;" ) );
-------
输出结果:
jdk.nashorn.api.scripting.NashornScriptEngine Result: 2Base64
在Java 8中,Base64编码已经成为Java类库的标准。它的使用十分简单,下面让我们看一个例子:
public class Base64s { public static void main(String[] args) { final String text = "Base64 finally in Java 8!"; final String encoded = Base64 .getEncoder() .encodeToString(text.getBytes(StandardCharsets.UTF_8)); System.out.println(encoded); final String decoded = new String( Base64.getDecoder().decode(encoded), StandardCharsets.UTF_8); System.out.println(decoded); } } ------------- 输出结果: QmFzZTY0IGZpbmFsbHkgaW4gSmF2YSA4IQ== Base64 finally in Java 8!
Base64类同时还提供了对URL、MIME友好的编码器与解码器(Base64.getUrlEncoder() / Base64.getUrlDecoder(), Base64.getMimeEncoder() / Base64.getMimeDecoder())。
并行(parallel)数组
Java 8增加了大量的新方法来对数组进行并行处理。可以说,最重要的是parallelSort()方法,因为它可以在多核机器上极大提高数组排序的速度。下面的例子展示了新方法(parallelXxx)的使用。
package com.javacodegeeks.java8.parallel.arrays; import java.util.Arrays; import java.util.concurrent.ThreadLocalRandom; public class ParallelArrays { public static void main( String[] args ) { long[] arrayOfLong = new long [ 5000 ]; Arrays.parallelSetAll( arrayOfLong, index -> ThreadLocalRandom.current().nextInt( 500000 ) ); Arrays.stream( arrayOfLong ).limit( 10 ).forEach( i -> System.out.print( i + " " ) ); System.out.println(); Arrays.parallelSort( arrayOfLong ); Arrays.stream( arrayOfLong ).limit( 10 ).forEach( i -> System.out.print( i + " " ) ); System.out.println(); } } ----------------- 输出结果: 43246 429105 479150 498970 478123 404198 273038 114468 488657 438767 111 347 552 581 731 852 1118 1252 1545 1735
上面的代码片段使用了parallelSetAll()方法来对一个有5000个元素的数组进行随机赋值。然后,调用parallelSort方法。这个程序首先打印出前10个元素的值,之后对整个数组排序。这个程序在控制台上的输出如下(请注意数组元素是随机生产的):
并发(Concurrency)
在新增Stream机制与lambda的基础之上,在java.util.concurrent.ConcurrentHashMap中加入了一些新方法来支持聚集操作。同时也在java.util.concurrent.ForkJoinPool类中加入了一些新方法来支持共有资源池(common pool)。
新增的java.util.concurrent.locks.StampedLock类提供一直基于容量的锁,这种锁有三个模型来控制读写操作(它被认为是不太有名的java.util.concurrent.locks.ReadWriteLock类的替代者)。
在java.util.concurrent.atomic包中还增加了下面这些类:
- DoubleAccumulator
- DoubleAdder
- LongAccumulator
- LongAdder
更多详情请参考官方文档。
新的Java工具
Java 8也带来了一些新的命令行工具。在这节里我们将会介绍它们中最有趣的部分。
Nashorn引擎: jjs
jjs是个基于Nashorn引擎的命令行工具。它接受一些JavaScript源代码为参数,并且执行这些源代码。例如,我们创建一个具有如下内容的func.js文件:
function f() { return 0 ; }; print( f() + 1 );
------
命令行中执行:jjs func.js
------
输出结果:1
jjs补充
Java 中调用 JavaScript
使用 ScriptEngineManager, JavaScript 代码可以在 Java 中执行,实例如下:
import javax.script.ScriptEngineManager; import javax.script.ScriptEngine; import javax.script.ScriptException; public class Java8Tester { public static void main(String args[]){ ScriptEngineManager scriptEngineManager = new ScriptEngineManager(); ScriptEngine nashorn = scriptEngineManager.getEngineByName("nashorn"); String name = "JackpotHan"; Integer result = null; try { nashorn.eval("print(‘" + name + "‘)"); result = (Integer) nashorn.eval("10 + 2"); }catch(ScriptException e){ System.out.println("执行脚本错误: "+ e.getMessage()); } System.out.println(result.toString()); } } ----------- 输出结果: $ javac Java8Tester.java $ java Java8Tester JackpotHan 12
JavaScript 中调用 Java
以下实例演示了如何在 JavaScript 中引用 Java 类,创建test.js文件:
var BigDecimal = Java.type(‘java.math.BigDecimal‘); function calculate(amount, percentage) { var result = new BigDecimal(amount).multiply( new BigDecimal(percentage)).divide(new BigDecimal("100"), 2, BigDecimal.ROUND_HALF_EVEN); return result.toPlainString(); } var result = calculate(1537933632887,13.14); print(result);
---------
控制台执行:$ jjs test.js
输出结果:202084479361.35
更多详情请参考官方文档
类依赖分析器jdeps
jdeps是一个很有用的命令行工具。它可以显示Java类的包级别或类级别的依赖。它接受一个.class文件,一个目录,或者一个jar文件作为输入。jdeps默认把结果输出到系统输出(控制台)上。
下面我们查看现阶段较流行的Spring框架类库的依赖报告,为了简化这个例子,我们只分析一个jar文件:org.springframework.core-3.0.5.RELEASE.jar
jdeps org.springframework.core-3.0.5.RELEASE.jar
这个命令输出的内容很多,所以这里我们只选取一小部分。依赖信息按照包名进行分组。如果依赖不在classpath中,那么就会显示not found。
org.springframework.core-3.0.5.RELEASE.jar -> C:Program FilesJavajdk1.8.0jrelib t.jar org.springframework.core (org.springframework.core-3.0.5.RELEASE.jar) -> java.io -> java.lang -> java.lang.annotation -> java.lang.ref -> java.lang.reflect -> java.util -> java.util.concurrent -> org.apache.commons.logging not found -> org.springframework.asm not found -> org.springframework.asm.commons not found org.springframework.core.annotation (org.springframework.core-3.0.5.RELEASE.jar) -> java.lang -> java.lang.annotation -> java.lang.reflect -> java.util
更多详情请参考官方文档
Java虚拟机(JVM)的新特性
元空间(MetaSpace)
PermGen空间被移除了,取而代之的是Metaspace(JEP 122)。JVM选项-XX:PermSize与-XX:MaxPermSize分别被-XX:MetaSpaceSize与-XX:MaxMetaspaceSize所代替。
JDK8 HotSpot JVM 将移除永久区,使用本地内存来存储类元数据信息并称之为:元空间(Metaspace),这与Oracle JRockit 和IBM JVM’s很相似,如下图所示
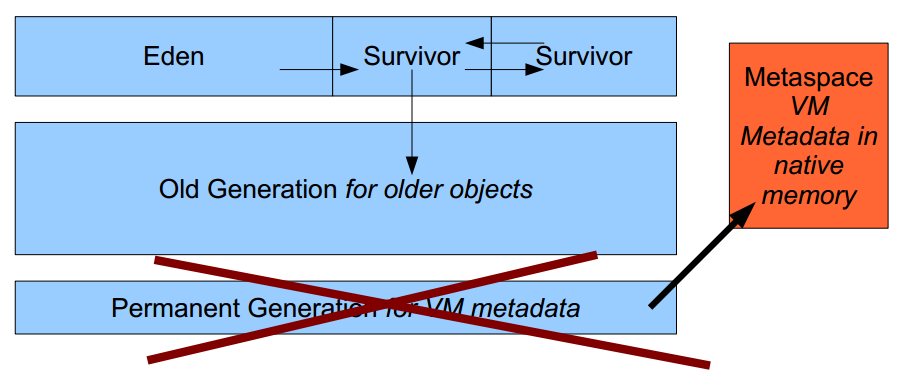
这意味着不会再有java.lang.OutOfMemoryError: PermGen问题,也不再需要你进行调优及监控内存空间的使用……但请等等,这么说还为时过早。在默认情况下,这些改变是透明的,接下来我们的展示将使你知道仍然要关注类元数据内存的占用。请一定要牢记,这个新特性也不能神奇地消除类和类加载器导致的内存泄漏。
java8中metaspace总结如下:
PermGen 空间的状况
这部分内存空间将全部移除。
JVM的参数:PermSize 和 MaxPermSize 会被忽略并给出警告(如果在启用时设置了这两个参数)。
Metaspace 内存分配模型
大部分类元数据都在本地内存中分配。
用于描述类元数据的“klasses”已经被移除。
Metaspace 容量
默认情况下,类元数据只受可用的本地内存限制(容量取决于是32位或是64位操作系统的可用虚拟内存大小)。
新参数(MaxMetaspaceSize)用于限制本地内存分配给类元数据的大小。如果没有指定这个参数,元空间会在运行时根据需要动态调整。
Metaspace 垃圾回收
对于僵死的类及类加载器的垃圾回收将在元数据使用达到“MaxMetaspaceSize”参数的设定值时进行。
适时地监控和调整元空间对于减小垃圾回收频率和减少延时是很有必要的。持续的元空间垃圾回收说明,可能存在类、类加载器导致的内存泄漏或是大小设置不合适。
Java 堆内存的影响
一些杂项数据已经移到Java堆空间中。升级到JDK8之后,会发现Java堆 空间有所增长。
Metaspace 监控
元空间的使用情况可以从HotSpot1.8的详细GC日志输出中得到。
Jstat 和 JVisualVM两个工具,在使用b75版本进行测试时,已经更新了,但是还是能看到老的PermGen空间的出现。
前面已经从理论上充分说明,下面让我们通过“泄漏”程序进行新内存空间的观察……
PermGen vs. Metaspace 运行时比较
为了更好地理解Metaspace内存空间的运行时行为,
将进行以下几种场景的测试:
- 使用JDK1.7运行Java程序,监控并耗尽默认设定的85MB大小的PermGen内存空间。
- 使用JDK1.8运行Java程序,监控新Metaspace内存空间的动态增长和垃圾回收过程。
- 使用JDK1.8运行Java程序,模拟耗尽通过“MaxMetaspaceSize”参数设定的128MB大小的Metaspace内存空间。
首先建立了一个模拟PermGen OOM的代码
public class ClassA { public void method(String name) { // do nothing } }
上面是一个简单的ClassA,把他编译成class字节码放到D:/classes下面,测试代码中用URLClassLoader来加载此类型上面类编译成class
/** * 模拟PermGen OOM * @author benhail */ public class OOMTest { public static void main(String[] args) { try { //准备url URL url = new File("D:/classes").toURI().toURL(); URL[] urls = {url}; //获取有关类型加载的JMX接口 ClassLoadingMXBean loadingBean = ManagementFactory.getClassLoadingMXBean(); //用于缓存类加载器 List<ClassLoader> classLoaders = new ArrayList<ClassLoader>(); while (true) { //加载类型并缓存类加载器实例 ClassLoader classLoader = new URLClassLoader(urls); classLoaders.add(classLoader); classLoader.loadClass("ClassA"); //显示数量信息(共加载过的类型数目,当前还有效的类型数目,已经被卸载的类型数目) System.out.println("total: " + loadingBean.getTotalLoadedClassCount()); System.out.println("active: " + loadingBean.getLoadedClassCount()); System.out.println("unloaded: " + loadingBean.getUnloadedClassCount()); } } catch (Exception e) { e.printStackTrace(); } } }
虚拟机器参数设置如下:-verbose -verbose:gc
设置-verbose参数是为了获取类型加载和卸载的信息
设置-verbose:gc是为了获取垃圾收集的相关信息
JDK 1.7 @64-bit – PermGen 耗尽测试
Java1.7的PermGen默认空间为85 MB(或者可以通过-XX:MaxPermSize=XXXm指定)
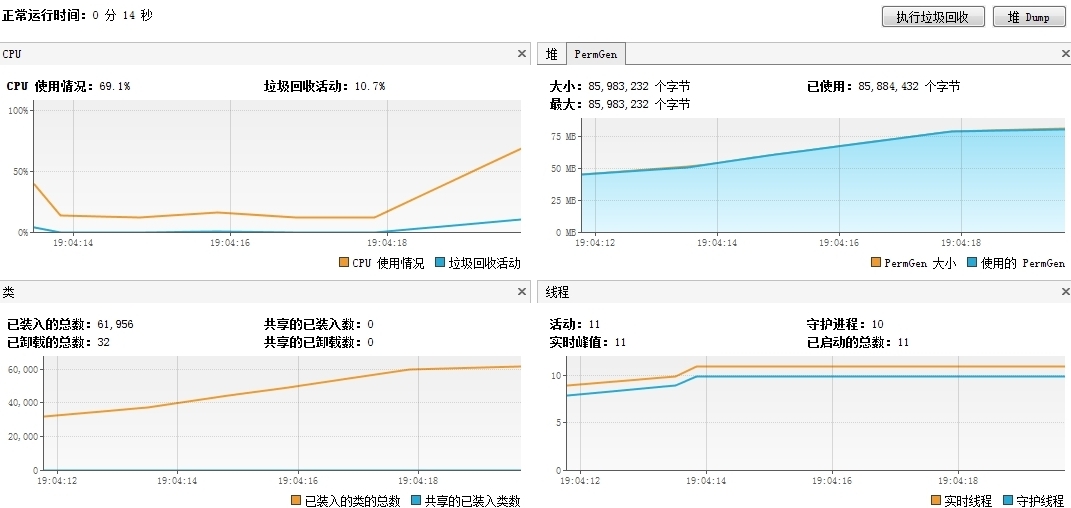
可以从上面的JVisualVM的截图看出:当加载超过6万个类之后,PermGen被耗尽。我们也能通过程序和GC的输出观察耗尽的过程。
程序输出(摘取了部分)
...... [Loaded ClassA from file:/D:/classes/] total: 64887 active: 64887 unloaded: 0 [GC 245041K->213978K(536768K), 0.0597188 secs] [Full GC 213978K->211425K(644992K), 0.6456638 secs] [GC 211425K->211425K(656448K), 0.0086696 secs] [Full GC 211425K->211411K(731008K), 0.6924754 secs] [GC 211411K->211411K(726528K), 0.0088992 secs] ............... java.lang.OutOfMemoryError: PermGen space
JDK 1.8 @64-bit – Metaspace大小动态调整测试
Java的Metaspace空间:不受限制 (默认)
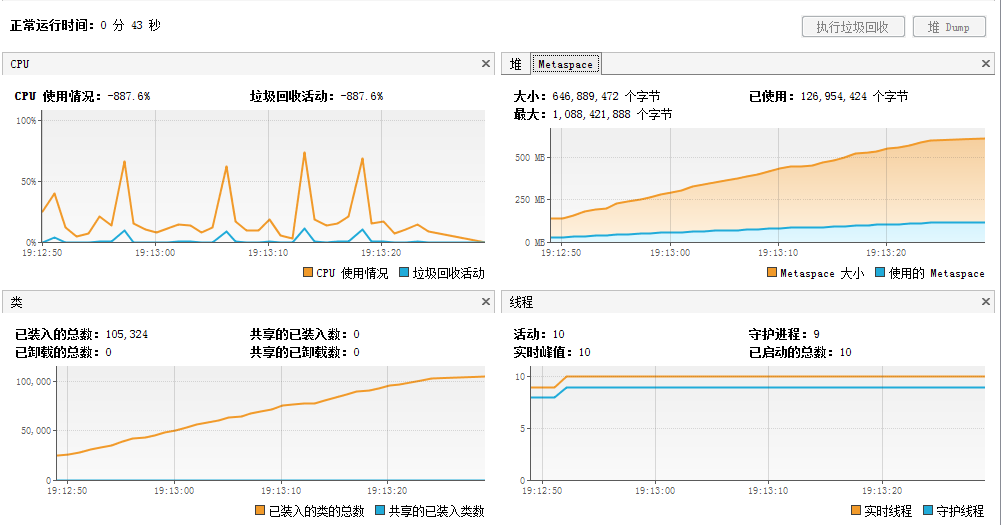
从上面的截图可以看到,JVM Metaspace进行了动态扩展,本地内存的使用由20MB增长到646MB,以满足程序中不断增长的类数据内存占用需求。我们也能观察到JVM的垃圾回收事件—试图销毁僵死的类或类加载器对象。但是,由于我们程序的泄漏,JVM别无选择只能动态扩展Metaspace内存空间。程序加载超过10万个类,而没有出现OOM事件。
JDK 1.8 @64-bit – Metaspace 受限测试
Java的Metaspace空间:128MB(-XX:MaxMetaspaceSize=128m)
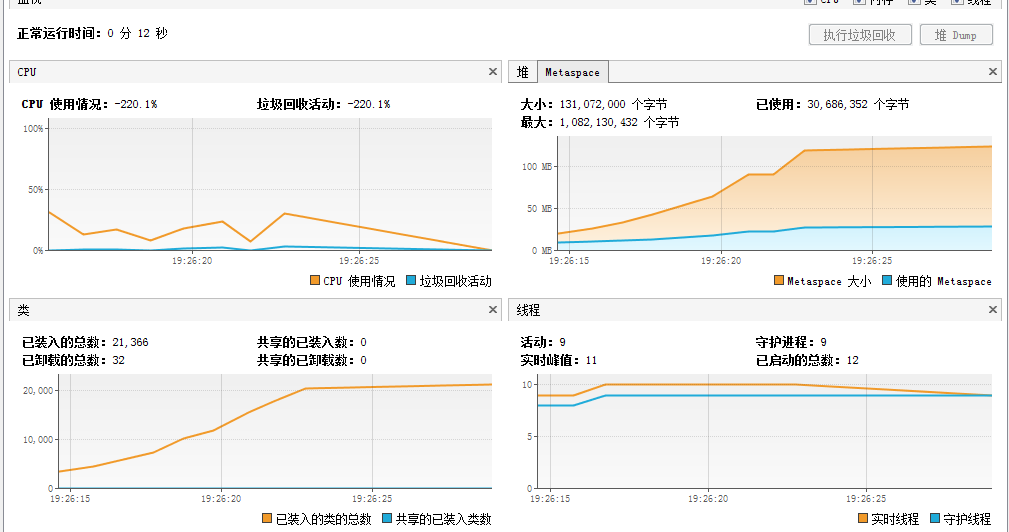
可以从上面的JVisualVM的截图看出:当加载超过2万个类之后,Metaspace被耗尽;与JDK1.7运行时非常相似。我们也能通过程序和GC的输出观察耗尽的过程。另一个有趣的现象是,保留的原生内存占用量是设定的最大大小两倍之多。这可能表明,如果可能的话,可微调元空间容量大小策略,来避免本地内存的浪费。
从Java程序的输出中看到如下异常。
[Loaded ClassA from file:/D:/classes/] total: 21393 active: 21393 unloaded: 0 [GC (Metadata GC Threshold) 64306K->57010K(111616K), 0.0145502 secs] [Full GC (Metadata GC Threshold) 57010K->56810K(122368K), 0.1068084 secs] java.lang.OutOfMemoryError: Metaspace
在设置了MaxMetaspaceSize的情况下,该空间的内存仍然会耗尽,进而引发“java.lang.OutOfMemoryError: Metadata space”错误。因为类加载器的泄漏仍然存在,而通常Java又不希望无限制地消耗本机内存,因此设置一个类似于MaxPermSize的限制看起来也是合理的。
小结:
- 之前不管是不是需要,JVM都会吃掉那块空间……如果设置得太小,JVM会死掉;如果设置得太大,这块内存就被JVM浪费了。理论上说,现在你完全可以不关注这个,因为JVM会在运行时自动调校为“合适的大小”;
- 提高Full GC的性能,在Full GC期间,Metadata到Metadata pointers之间不需要扫描了,别小看这几纳秒时间;
- 隐患就是如果程序存在内存泄露,像OOMTest那样,不停的扩展metaspace的空间,会导致机器的内存不足,所以还是要有必要的调试和监控。
参考资料
https://www.oracle.com/technetwork/java/javase/8-whats-new-2157071.html
http://www.importnew.com/11908.html
https://www.baeldung.com/java8
以上是关于整理Java 8新特性总结的主要内容,如果未能解决你的问题,请参考以下文章