flink基本概念
Posted 请不要卷我
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink基本概念相关的知识,希望对你有一定的参考价值。
流处理
自然环境中数据的产生都是流式的,分析数据时,可以围绕有界流(bounded)和无解流(unbounded)两种模型来处理数据
在flink中,应用程序由用户自定义算子转换而来的流式dataflows组成。这些流式dataflows形成了有向图,以一个或多个源(source)开始,并以一个或多个汇(sink)结束
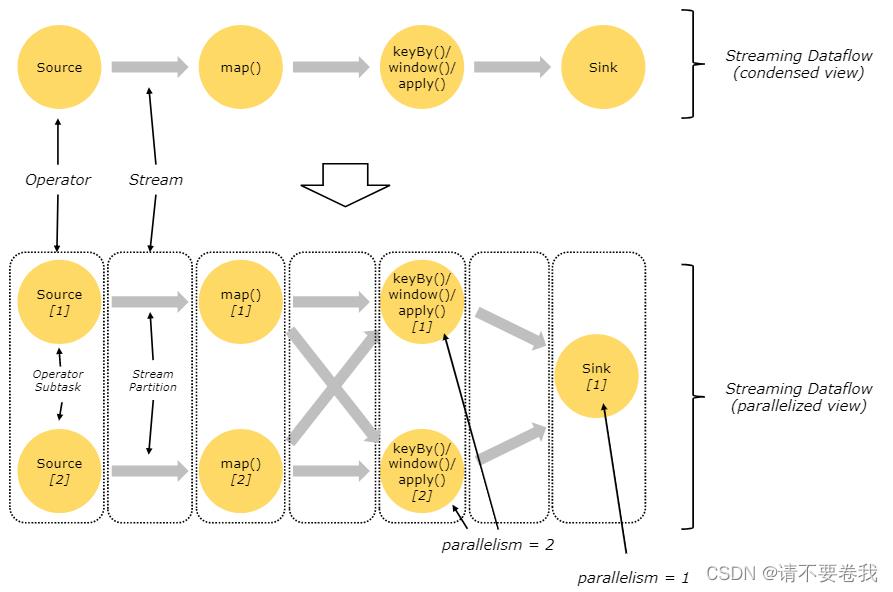
并行Dataflows
flink程序本质上是分布式并行程序,在程序执行期间,一个流有一个或多个分区,每个算子有一个或多个子任务(operator subtask)。每个子任务彼此独立,并且在不同的线程中运行,或在不同的计算机或容器中运行
算子的子任务数就是对应算子的并行度。在同一程序中,不同算子也可能具有不同并行度
数据传输
一对一(直传)模式:同一分区的数据传输到下游的同一分区(输入的数据及其顺序完全相同)
重新分发模式:根据不同的算子进行不同的数据分发模式,如keyBy()通过散列键重新分区、broadcast()广播、rebalance()随机重新分发
自定义时间流处理
使用事件时间而不是处理数据的机器时间
有状态流处理
flink中的算子可以是有状态的。这意味着如何处理一个事件可能取决于该事件之前所有事件数据的累积结果
flink程序的状态访问都在本地,这有助于提高吞吐量和降低延迟。通常情况下,flink状态存储在jvm堆上,但如果状态太大,我们也可以选择将其以结构化数据格式存储在高速磁盘中
以上是关于flink基本概念的主要内容,如果未能解决你的问题,请参考以下文章