第10章神经网络基础
Posted paladinzxl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第10章神经网络基础相关的知识,希望对你有一定的参考价值。
第10章神经网络基础
在本章中,我们将深入研究神经网络(neural networks)的基础。我们将首先讨论人工神经网络,以及它们是如何从我们自己身体中的真实生物神经网络中得到启发的。之后,我们将回顾经典的感知器算法(Perceptron algorithm)以及它在神经网络历史中的作用。
构建了感知器,我们将学习BP算法(backpropagation algorithm),这是现代神经网络的基石。我们将使用python从头实现BP算法,确保我们理解了这个重要的算法。
当然,现代神经网络库如Keras已经有了(高度优化的)内置的BP算法。每次我们想训练一个神经网络时,手动实现反向传播就像每次我们处理一个通用编程问题时,从零开始编码一个链表或哈希表数据结构,不仅不现实,而且浪费时间与资源。为了简化过程,我将演示如何使用Keras库创建标准前馈神经网络。
最后,我们将通过讨论构建任何神经网络时所需要的四个要素来总结本章。
1 神经网络基础
在进入卷积神经网络之前,我们首先需要理解神经网络的基础。本章我们将回顾:
(1)人工神经网络和它们与生物学之间的关系。
(2)种子感知器算法(seminal Perceptron algorithm)。
(3)BP算法以及它如何有效的训练多层神经网络。
(4)如何使用Keras库训练神经网络?
当学习网本章,你将对神经网络有很深的理解,且能够学习更高级的卷积神经网络。
1.1 神经网络介绍
神经网络是深度学习系统的组成部分。为了在深度学习方面取得成功,我们需要首先回顾一下神经网络的基本知识,包括体系结构、节点类型和“教授”网络的算法。
本节我们回顾神经网络以及它与人类大脑的生物学关系。之后讨论最常见的架构类型:前馈神经网络。也将简要讨论神经学习的概念以及它与之后训练神经网络的算法之间的关系。
(1)什么是神经网络?
涉及到智力、模式识别和目标检测的许多人物是极难自动进行的,但是对于动物和小孩子却很容易且很自然。例如家养的狗对待家人与陌生人时的不同反应?小孩子识别校车与公共汽车?我们的大脑持续的执行如此复杂的任务而我们没有注意到?答案就在我们的身体里。我们每个人都包含一个与神经系统相连的真实的生物神经网络——这个网络是由大量相互连接的神经元(neurons)(神经细胞)组成的。“神经”是“神经元”的形容词形式,而“网络”代表一种类似图的结构,因此“人工神经网络”(Aritificial Neural Network, ANN)是一种在我们的生物神经系统中致力于模拟神经连接的计算系统。它通常简写为“ANN”或“NN”,本书中将使用这两种。
考虑一个NN系统,它必须包含一个标签的、有向图结构,结构中的每个节点都执行一些简单计算。图1为NN的示例。
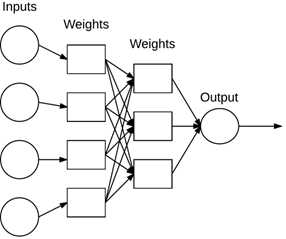
图1 一个简单的NN架构。
每个节点都执行一个简单的计算。之后的每个连接携带信号(比如计算的输出)从一个节点到另一个节点,由权重表示该信号是被放大还是缩小。一些连接是大的、正的放大信号的权重,表示这个信号在作出分类时非常重要。另一些是负的权重,减小信号强度,即表示节点的输出对最终的分类不重要。我们称这种系统为ANN,如果它由权重连接的图结构组成(类似图1),这些权重用于在一个学习算法中可以调整。
(2)与生物学的关系
我们的大脑大约由100亿神经元构成,每个神经元大约于10,000个其它神经元连接。生物神经元结构如图2所示:
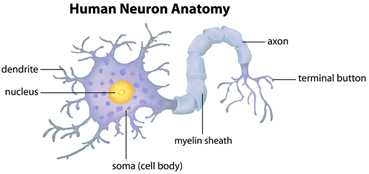
图2 生物神经元结构
神经元的细胞体成为soma,它的输入(dendrites)和输出(axons)连接到其它soma上。
每个神经元在dendrites上接收其它神经元的电信号输入。如果这些电信号足够强能够激活神经元,则这个激活的神经元将沿着axon将信号传递到其它神经元的dendrites。这些相连的神经元也可能被点燃(fire),继续传递该消息。
一个神经元被firing的关键操作是二值操作(binary operation)——要么被点燃,要么不被点燃。没有点燃的等级存在。仅仅是,如果神经元接收到的总的信号强度超过了给定门限,则就会被点燃。
然而,请记住,ANN的灵感仅仅来自于我们对大脑的了解和大脑的工作原理。深度学习的目的不是模仿我们的大脑如何运作,而是学习我们所理解的东西,让我们在自己的工作中做出类似的类比。现在,我们对神经系统科学和大脑深层功能的了解还不够,无法正确模拟大脑的工作方式——相反,我们从中汲取灵感,然后继续前行。
(3)人工模型
看一个基本的NN,它执行简单的输入加权求和,如图3所示:
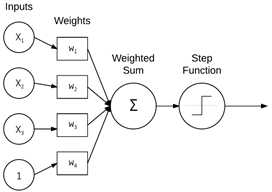
图3 简单的NN
如图3所示的简单的NN,它模拟了神经元结构,即执行输入x和权重w的加权和,加权和随后传递到激活函数来决定是否激活该神经元。其中值x1, x2, x3为NN的输入且通常对应于来自我们的设计矩阵的单个行(例如,数据点)。常量1表示偏置且假定它被嵌入到设计矩阵中。我们可以将这些输入考虑成输入到NN的输入特征向量。
在实践中,这些输入可能是向量,用于以系统的、预定义的方式量化图像的内容(例如,颜色直方图、定向梯度直方图、局部二值模式等)。在深度学习背景下,这些输入就是图像本身的原始像素强度。
每一个x都通过由w1, w2, …., wn构成的权重向量W相连,加权和后通过激活函数f(用于确定神经元是否激活),输出一个值。数学上,通常见到三种形式:
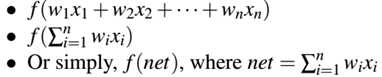
(3)激活函数(activation functions)
最简单的激活函数是用在感知器算法(perceptron algorithm)中的阶跃函数:
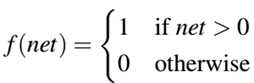
如图4所示:
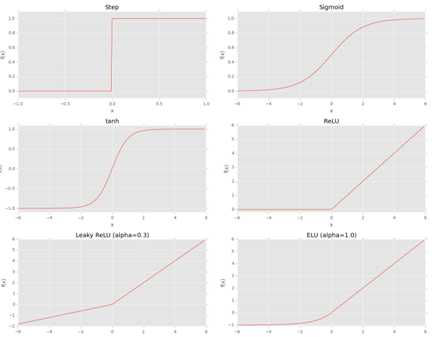
图4 不同激活函数图形示例
阶跃函数在加权和大于0时为1,小于0时为0,就像站在阶梯上下一样。然而,尽管它具有直观和易于使用的特点,但是它的阶跃函数是不可微分的,这在应用梯度下降和训练我们的网络时会导致问题。
代替它的是在NN文献历史上更常用的激活函数sigmoid函数:

Sigmoid函数比step函数更好的用于学习,是由于:(1)任意时刻是连续且微分(2)y轴对称(3)渐进的接近饱和。
Sigmoid的主要优点是它平滑,因此可更简单的推导出学习算法,但是他有两个大问题:(1)它的输出不是0中心(2)饱和神经元本质上将kill梯度,因为梯度的delta将及其小(这里的意思是随着加权和足够大,f的输出将非常平,变化接近饱和)。
在1990s后使用的激活函数为tanh函数:
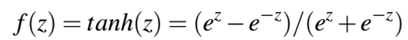
Than函数是0中心的,但是梯度仍将killed,在神经元饱和时。
我们现在知道有种比sigmoid和tanh更好的激活函数选择,即ReLU(Rectified Linear Unit,校正的线性单元):
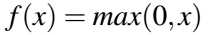
ReLU函数不会饱和且计算也及其有效。经验上,ReLU激活函数在几乎所有应用上都优于sigmoid和tanh函数。但是,当我们的值为0时,有一个问题就是梯度不能取值。
之后,一种ReLU的变种,Leaky ReLU允许在单元没有激活时有一个小的、非零梯度:
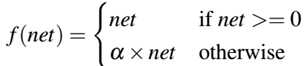
由图中可看出,该函数允许有一个负值输出,而不像传统的ReLU将函数输出强制到0值。
Parametric ReLUs或者PReLus以Leaky ReLUs为构建基础,允许参数α可以作为一个参数来学习,表示网络中的每一个节点都可以学习一个不同的参数与其它节点不同。
最后,一种ELUs(指数线性单元)被引入:
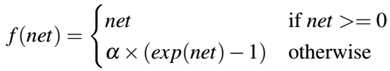
这里的参数α是常数且在网络机构初始化时被设置,它不像PReLUs中的参数可以学习。通常这个值设置为1.0。在提出ELUs的作者以及本文作者认为,ELUs常常获得比ReLUs更好的分类精确度。
(5)我该使用哪种激活函数?
由于目前存在现代的(ReLU, Leaky ReLU, ELU等等)和经典的(step, sigmoid, taan等等)的选择,作者强烈建议以ReLU开始先获得一个基准精确度,然后在切换到Leaky ReLu变种中测试。
作者个人经验是,首先以标准ReLU开始,然后调整网络和优化器参数(架构、学习率、正则化强度等等)并且观察精确度。一旦合理的满足了精确度要求,再切换到ELU上通常能够依赖于数据集在分类精确度上再提高1%—5%。
(6)前馈网络架构
尽管有许许多多不同的NN架构,但是最常见的架构是前馈网络(feedforward network),如图5所示:
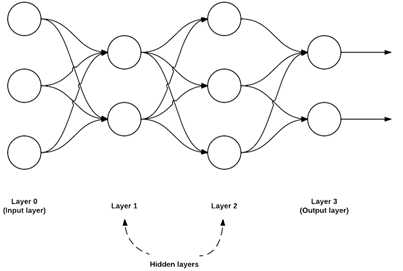
图5 前馈神经网络的例子
图5所示的前馈神经网络例子中,包含3个输入节点、具有2个节点和3个节点的隐藏层、以及具有2个节点的输出层。在这种类型的架构中,节点之间的连接仅仅允许从层i的节点到层i+1的节点(因此术语,前馈),而不允许有反馈和层内的连接。前馈网络包括反馈连接(反馈到输入的输出连接)时,称为循环神经网络(recurrent neural network,RNN)。
在本书中关注于前馈神经网络,因为他们是现代深度学习应用到计算机视觉的基石。在第11章中的CNNs就是前馈神经网络的特例。
为了描述一个前馈网络,我们通常使用整数序列来快速精确的标识每一层节点的数目,例如图5的网络可表示为一个3-2-3-2的前馈网络:
层0:包含3个输入。
层1和2:分别包含2和3个节点的隐藏层。
层3:输出层或可视层,这是我们从网络中获得的全部的输出分类。输出层通常与类别标签的数目一样多,一个节点就是一个潜在的输出。例如,如果我们构建一个NN用于分类手写数字,我们的输出层将包含10个节点,每一个表示0-9中的一个数字。
(7)神经学习
神经学习涉及到修改权重和在一个网络中节点之间连接的方法。
(8)神经网络用于做什么?
神经网络可用于监督、半监督、非监督学习任务,提供合适的架构。完整的回顾NN可参考[1]。通常,NN的应用包括分类、回归、聚类、向量量化、模式关联和函数逼近,这里仅举几个例子。在本书中,使用NN用于计算机视觉和图像分类。
(9)神经网络基础总结
本节通过回顾ANN基础,现在让我们通过实际的架构和相关实现来更详尽的学习该知识。下一节,讨论经典的Perceptron algorithm(感知器算法),这是被创建的第一个ANN。
1.2 感知器算法(perceptron algorithm)
简单说来,感知器算法是最古老的且最简单的ANN算法。从提出、到严冬、再到多层感知器与BP算法的提出,经历了一系列过程。总之,感知器对于理解更高级的多层网络仍然是非常重要的算法。我们首先回顾感知器架构,解释用训练感知器中的训练过程(又称为delta rule)。随后回顾了网络中的终止准则(例如,感知器什么时候应当停止训练)。最后,使用纯python代码实现感知器算法且解释网络为何不能学习非线性分类数据集。
(1)AND、OR、XOR数据集
在进行讨论感知器之前,我们首先看下位操作,包括AND、OR、XOR。位操作和相关的位数据集接受两个输入bit位且在应用操作后产生一个最终的输出bit。给定两个bit,每一个取值0或1,表1提供了AND、OR、XOR的4种可能结果:
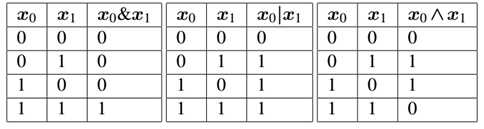
表1 位操作结果
我们常常用这些简单的位操作来特使和调试机器学习算法。如图6的可视化位操作值:
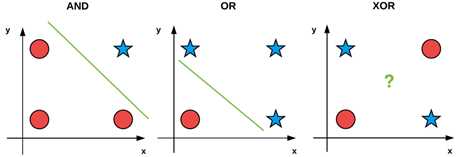
图6 位操作可视化示意图
其中AND和OR是线性可分的,我们可以清晰的画一条分开0或1类别的线,但是却不能再XOR上画出。即XOR是一个非线性可分数据集的例子。
理想上,我们想我们的机器学习算法能够划分非线性数据,因为大多数见到的现实中的都为非线性的。因此,当构建、调试、评估一个给定的机器学习算法时,我们可能使用位值x0和x1作为我们的设计矩阵并且试着去预测对应的y值。
不像标准的划分训练集合测试集的过程,使用位数据集时我们在相同的数据集上测试和评估网络。这里的目标是简单的确定是否学习算法能够学到数据的模式。就像指出的,感知器算法能够正确的分类AND和OR却不能分类出XOR数据。
(2)感知器架构
Rosenblatt定义感知器作为一个系统,利用特征向量(或原始像素强度)的标记示例(即监督学习)学习,将这些输入映射到相应的输出类标签。
最简单的形式中,一个感知器包含N个输入节点,每一个节点是设计矩阵的输入行,然后跟着网络中唯一一层,仅仅是那个层的单个节点,如图7:
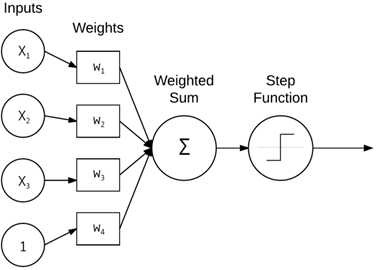
图7 感知器网络架构
这里存在着连接且他们的连接对应于来自输入xi的对应权重w1, w2, …., wi,以及网络的单个输出。节点区加权和送入step函数确定输出类别标签。感知器输出要么0要么1,即最原始的形式中,感知器仅仅是一个二值、二类别分类器。、
(3)感知器训练过程和delta rule
训练感知器是相当直观的过程。我们的目标是获得权重w,能够正确的分类训练集中的每一类。为了训练感知器,我们迭代的将训练数据feed网络多次。每一次网络都能看到整个训练数据集,即传递了一个epoch。通常需要多次epoch,直到学习到一个权重向量w能够线性的分出两类数据集。
感知器训练算法的伪代码可描述如下:
实际的“学习”发生在2b和2c步骤。首先,我们将特征向量xj传递到网络,通过与权重w点乘获得输出yj。这个值之后传递到step函数,这个函数决定如果x>0,返回1,否则返回0。
现在我们需要更新权重向量w能够更进一步接近正确的分类。这个更新权重向量的过程通过步骤2c的delta rule处理。
表达式 (dj - yj)决定了输出分类是否正确。如果分类正确,则这个差值为0,否则差值要么正要么负,指明了我们的权重要更新(直到更接近正确的分类)的方向。之后通过xj与(dj-yj)相乘,使我们移动到更正确的分类上。
1、以小的随机数初始化权重向量w
2、直到感知器聚合:
(a)在训练集D上循环每一个特征向量xj和真实类别标签di
(b)取x传递到网络,计算输出值:yj = f(w(t)·xj)
(c)更新权重向量 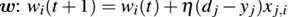 对所有特征0<=i<=n
对所有特征0<=i<=n
这里的参数η是学习速率控制我们步幅大小,既不能太大也不能太小。如果对此有困惑,不用担心,我们将在后续中使用python代码进行详细阐述。
(4)感知器训练终止
感知器训练过程执行,直到所有训练样例都分类正确或者预设的epoch到达次数限制。确保终止,需要参数η设置的有效小且训练数据线性可分。
那么,如果数据不是线性可分的或者设置了差的参数选择怎么办?会无限训练吗?我们通常通过设置一定次数的epoch或者根据分类错误的次数来终止训练。
(5)python实现感知器
既然我们研究了感知器算法,我们用python实现真正的算法。感知器算法包文件目录结构如下:

我们在pyimagesearch.nn包中创建perciptron.py的文件,该文件包含真正的感知器实现。创建文件后,键入以下代码:

这里定义了Perceptron类,接受一个默认参数和一个输入参数:N表示我们特征向量的列数目,在位操作中, N=2表示两个输入。alpha为感知器算法的学习率,常选择0.1,0.01,0.001。
权重矩阵为N+1维,表示N个输入特征向量,加上1个偏置。通过np.sqrt(N),这是用于权重矩阵缩放的常用技术,可更快的收敛。我们将在本章后续技术中使用这种权重初始化技术。
下一步我们定义step函数:

这个函数为激活函数中的step函数。
为了真正的训练感知器我们定义名为fit的函数。通常在机器学习、python和scikit-learn库中,训练过程定义为函数fit:

fit方法接收两个参数:X表示实际的训练数据,y变量表示目标输出类别标签。最后,支持epochs,表示感知器训练的轮次数。在18行将bias作为权重的训练参数。
下一步,我们看下实际的训练过程:

在21行以设计的epoch数目循环,在每一次epoch中,我们对数据集中的每一个数据点及输出标签进行循环预测(23行)。在27行通过输入特征x与权重矩阵w点乘,然后通过step函数获得感知器的预测输出。之后,当预测结果与目标结果不一致时,进行权重更新。
最后的函数需要定义predict(),它用来在给定输入数据时预测类别标签:

predict()方法要求一个需要被分类的输入数据集X,默认添加偏置列。预测输出与训练过程类似,将加权和通过step函数即可。
现在,我们实现了perceptron类,让我们尝试应用位数据集以及看看网络是如何执行的。
(6)评估感知器位数据集
首先在perceptron相同层级的文件夹内创建一个名为perceptron_or.py的文件,用于在位数据集上训练感知器模型:
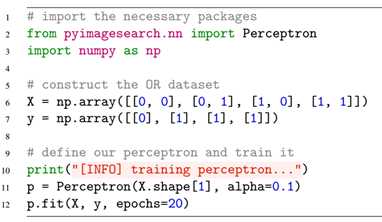
我们首先通过导入创建的Perceptron感知器类,然后构建了OR数据集,然后进行训练。之后我们评估该数据集:

在评估中,我们对数据集中的每一个数据点进行预测,然后输出数据点、真实标记和预测标记。
最后我们运行程序,将显示结果:

我们通过改变数据集中的目标标签,使得数据集变为AND、XOR数据集,通过测试,可看出无论执行多少次,对于XOR我们的单层感知器模型无法正确的预测。我们需要多层,从多层开始进入了深度学习领域。
1.3 后向传播和多层网络
BP算法是可论证的在神经网络历史上最重要的算法。BP算法可认为是现代神经网络和深度学习的基石。BP的专题有很多,作者列出的包括:

可看到,关于BP的论述与讨论有很多,作者通过这种方法来学习:通过使用python语言构建一个直观、易于跟踪的BP算法实现。在这个实现中,通过构建一个真实的神经网络并且使用BP算法训练它。当完成该小节,你将理解BP是如何工作的,可能更重要的是,你将深入理解这个算法是如何从头训练神经网络的。
(1)BP算法
BP算法包含两个阶段:
l 前向传播(forward pass):输入穿过网络且获得预测输出(也称为传播阶段(propagation phase))。
l 后向传播(backward pass):在网络的最后一层(例如,预测层)计算损失函数的梯度,且使用这个梯度迭代的应用链式法则来更新网络中的权重(也称为权重更新阶段(weight update))
我们首先从高层回顾这几个阶段,然后使用python实现BP算法。一旦实现了该算法,就可以做出预测,这个预测过程仅仅是前向传播阶段,根据代码仅需做出一些小的调整即可做出更有效的预测。
最后,我将演示使用BP和python在XOR数据集上和MNIST数据集上如何训练一个自定义的神经网络。
(2)前向传播阶段
前向传播的目的是应用一系列点乘和激活函数将我们的输入在网络中传播,直到达到网络的输出层(如预测)。为了可视化这个过程,我们考虑XOR数据集,如表2左侧:
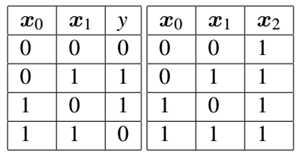
表2 左:XOR数据集(包含类标签) 右:加入bias的设计矩阵
由表2我们知道在设计矩阵中的每一个X都是2维的,即每个数据点都是两个位表示。例如第一个数据点特征向量位(0,0),第二个数据点为(0,1)。我们将对应的XOR的输出标签置于对应行,我们的目标就是正确的预测目标输出y值。
就像在下面指出的,要正确的分类这种非线性问题,我们需要具有至少单个隐层的前馈神经网络,因此我们以一个2-2-1架构开始,如图9,这里我们没有加入偏置。当插入偏置后,我们的特征向量对应于表2右侧,在实际中,可以把偏置插入任何一列,但是通常要么插入特征向量的起始列要么插入最后一列。由于我们改变了输入特征向量的大小(通常在神经网络实现本身内部执行,这样我们就不需要显式地修改我们的设计矩阵),这种修改使得网络架构从2-2-1到3-3-1架构,见图9。
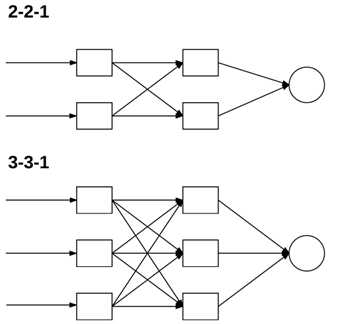
图9 网络架构示意图(根据是否修改偏置)
为了从实践中感受前向传播,我们首先初始化网络中的权重,如图10所示。权重值将在BP阶段进行更新。
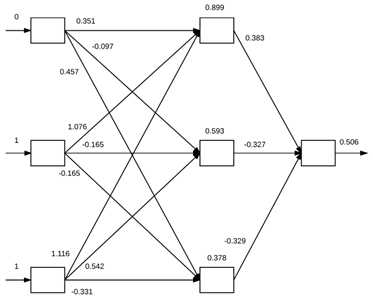
图10 前向传播示例
由图10的左侧我们输入特征向量(0,1,1)(对应的网络的目标输出为1)。可看到特征向量的每一个值0,1,1分别对应网络中的三个输入节点中的一个。为了通过网络传播值且获得最终的分类,我们需要在输入与权重之间点乘,然后将结果应用到激活函数中(这个例子中使用sigmoid函数,σ)。
首先计算三个隐藏层对应的值:
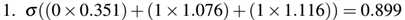
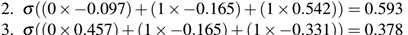
通过上述计算,我们将输入值传递到了隐藏层的三个节点。那么我们将继续这个计算过程,根据三个隐藏层的输入值以及权重获得网络的输出结果:
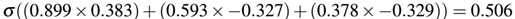
可看到,网络的输出结果为0.506,我们之后通过一个step函数来确定预测分类的输出:
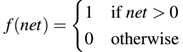
那么,我们通过net=0.506,我们的网络预测值为1,也就是预测正确了这个标签。但是,我们的网络在这个标签的预测结果不是很自信,因为预测值0.506非常接近于step的门限。理想上,这个预测应该接近0.98-0.99,暗示我们的网络确实在数据集上学习到了潜在的模式。为了我们的网络确实能够学习,我们需要应用反向传播过程。
(3)反向传播
为了应用反向传播算法,我们的激活函数必须是可微分的,以至于我们可以在给定权重、损失(E)、节点输出Oj、和网络输出netj下计算误差的偏导数:
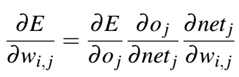
作者在这里没有推导,读者可以自行搜索,有很多。我在这里简要说明,最后的损失E对权重Wi,j的偏导数等于首先E对第j个输出oj的偏导、然后是oj对第j个输出对应的加权和netj的偏导、最后才是加权和netj对权重wi,j的偏导。作者将通过下述的python代码进行说明。
(4)用python实现BP算法
首先在perceptron.py所在的目录下新建一个名为neuralnetwork.py的文件:

我们首先导入必要的数值运算库。然后第5行定义了NeuralNetwork类,这个类需要一个必须参数,一个默认参数:
l Layers:该参数是整数列表,表示真正的前馈网络架构。例如[2,2,1]表示一个输入2节点,隐藏2节点,输出1节点的网络。
l Alpha:指定神经网络的学习率。
随后,我们初始化每一层的权重W的列表值[],然后存储层以及alpha值。由于初始权重值是空的,因此我们首先要初始化权重:

这里我们循环网络的层数目,但是在最后两层前停止(这将在后续详细说明)。网络中的每一层通过一个标准、均值分布的抽样值表示的M*N权重矩阵构建,权重M*N是因为我们构建的权重是当前层的每一个节点与下一层的每一个节点之间的连接。例如,假定layers[i] = 2且layers[i+1] = 2,那么我们的权重要连接这些节点需要是2*2的矩阵,但是需要注意,我们忘记了重要的部分——偏置项。即加上偏置项之后,当前层与下一层都需要加上偏置,因此矩阵变为3*3即当前层有2+1个节点以及下一层为2+1的节点。通过对W进行当前层的节点数目的平方根缩放,可使每个神经元的输出方差均一化。
最后的代码块是构建最后两层之间的特殊权重,因为最后两层之间的连接输入层存在偏置,而输出层不需要偏置:

之后,我们通过定义一个魔法函数__repr__用于调试,即可以显示网络的层次架构:

例如,按照下述进行执行,会显示网络架构:

注意:在这样导入类名时,要记得之前说过的要在包下的__init__.py中添加该包。
下一步,我们定义sigmoid激活函数:

以及在反向传播中用到的sigmoid的导数:

这里的sigmoid的导数的输入x为经过了sigmoid激活函数后的x值。再次注意,无论什么时候执行反向传播,都要选择一个可微分的激活函数。
后续由于代码太多,这里不作代码粘贴,具体代码可见github中相应代码。
之后按照常见训练过程,创建fit()函数,用于对X和y进行训练,其中X对应于训练数据,y对应训练数据对应的类别标签。在epoch循环的每一次epoch训练中,我们都对X中的每一个数据点进行循环预测,并根据预测结果进行权重更新。在这每一个数据点的计算中,都要进行前向传播和后向传播过程。
在前向计算中,我们将每一层对应的输出结果保存到A[layer]的对应层数组中,这样在前向计算中,当前层的输出结果就可以根据当前层的A[layer]值点乘权重值获得。并最终获得输出层的输出结果,并保存在了A[-1]中。
那么在后向传播计算中,我们可以首先由公式error = A[-1] – y获得输出损失值,然后根据链式法则,反向计算每一层的导数值并存放在D中。在反向计算完所有层的D值后,将D值翻转后,获得正向的每一层结果。之后循环每一层权重,对权重进行权重更新。上述过程就完成了对一个数据点的前向、后向计算过程。那么在所有epoch下,对所有数据集X按照上述过程计算完后,就完成了对数据集的训练过程。
之后,如果对新数据集X进行预测时,可直接根据训练过程获得的权重W通过与X点乘再通过激活函数获得预测结果即可,即预测过程仅仅是简单的前向计算过程。
通过创建的2-2-1与2-1的前向神经网络对比分析,可知2-1的网络无法训练非线性数据集。
(5)mnist示例BP算法python实现
Mnist数据集集成到了scikit-learn库,包括1797个实例数字,每个为8*8灰度图(原始图像为28*28)。
通过min/max缩放,将数字变为float数据,然后缩放到[0,1]之间:

之后通过构造网络,输入为1797,输出为10个数字:
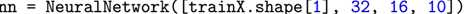
通过在chpater10/下的nn_mnist.py运行,可看出有些数字的精确度不高,因为这里内置的mnist数据集在测试中只用了450实例,在后续中,我们将用CNNs在全数据集上进行测试。
(6)BP算法总结
BP算法是梯度下降算法家族的推广,专门用于训练多层网络。在实际中,BP不仅在实现上具有挑战性(因为在计算梯度时出现了错误),而且在没有特殊的优化库的情况下也很难实现高效,这就是为什么我们经常使用库,如Keras,TensorFlow,和已经(正确)使用优化策略实现BP的mxnet等。
1.4 使用Keras的多层网络
既然我们用纯python实现了神经网络,我们现在使用专门的(经过优化的)神经网络库如Keras来实现它。下面我们将用用mnist和cirfar-10实现前馈神经网络,主要有两个目的:一是演示如何使用Keras库实现简单的神经网络,二是为后面应用CNNs等标准神经网络获得一个基准测试。
(1)mnist
在上一节中,我们使用抽样的mnist数据集,现在我们使用全mnist数据集,它每个数字有70000数据点,每个数据点784维,对应28*28的图像。我们在chapter10/下创建keras_mnist.py文件:


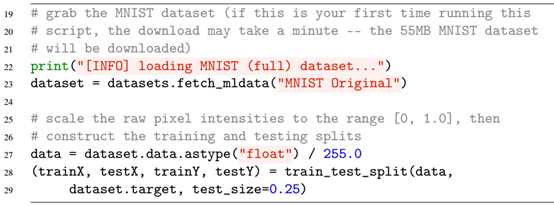
在from sklearn.preprocessing import LabelBinarizer用于将数据集中的整数标签one-hot编码成向量标签,one-hot编码将单个整数标签转换成向量,之后通过argparse包解析参数,这里的output/keras_mnist.png参数要提前创建好,否则提示错误。之后,加载数据集,并将像素强度缩放到[0,1],即第27行。之后划分训练集与测试集。

之后将数据标签从整数转换为向量,由于标签为0-9,这里的one-hot编码如下:


这种编码机制在很多机器学习库中都存在。下面构建前馈网络架构,输入为数字的28*28的784维特征向量,输出为10维标签,构建网络过程如下:

这里model.add()构建网络,在Dense()中添加每层信息,即在第一层中首先是下一层输入、输入维度、激活函数,中间层次只填写下一层输入、激活函数即可,在最后一层,由于是类别输出,激活函数使用softmax。
在模型构建完后,我们通过优化器训练网络:

即根据学习率构建SGD优化器, 然后构建模型内核信息:loss、optimizer、metrics等,然后fit训练模型,注意在训练模型中我们的验证集使用了测试集,这在实际中是不合理的,这里仅是作为测试用例来演示keras的训练过程。在实际环境中,要调整超参数或调整网络架构时,要通过验证集来验证而不是训练集。

训练完成后,我们就可以应用predict()方法来预测测试集的结果,以及评估网络性能了,其中在评估report中,我们要确定最大概率的标签,仅仅通过.argmax(axis=1)即可知道了。
最后,我们将通过matplot将损失与精确度统计出来,然后保存:
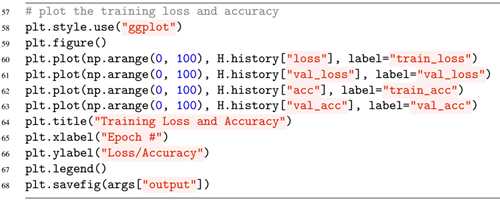
通过运行python keras_mnist.py –output /output/keras_mnisit.png将开始训练过程。在第一次运行时,由于要在线下载mnist数据集,会花费一定时间,下载完后就能很快训练了。训练完后,可显示训练曲线:
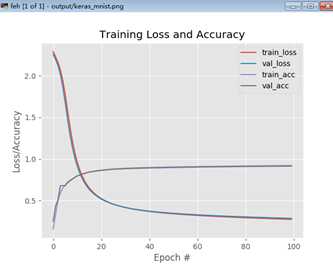
由图中可看出,训练损失和验证损失基本接近,表明没有过拟合或训练过程的问题。当数据集为现实中图像的时候,训练精度将不是很好,见下一训练。
(2)CIFAR-10
由于mnist数据集太容易获得高精确度,而且它不能反映现实中的图像。因此这里通常使用CIFAR-10数据集,该数据集由60000副32*32的RGB图像构成,即数据集中的每一个数据点都由32*32*3=3072整数构成,同时,该数据集由10类构成,即输出层节点数为10。这个数据集的训练和mnist类似,不同的是构建的网络不同,但基本流程一样,这里不再列出,具体见github的chapter10/keras_cifar-10.py文件。
简要说明,训练图像为(50000, 32,32,3)将reshape为(50000, 3072),训练集reshape为(10000, 3072)。最后执行完训练过程后,将显示训练结果:
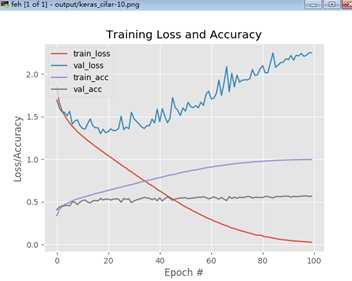
由图可看出,网络的训练的验证集正确率只有50%左右,并且训练损失急剧下降而验证损失增加的特性表明极其过拟合的现象。事实是——具有严格全连接层的基本前馈网络不适合挑战图像数据集,因此我们需要更高级的方法:CNNs。当完成Startle Bundle时,我们将能够在CIFAR-10上获得79%的正确率,如果继续学习Practitioner Bundle,我们将演示如何将正确率提高到93%以上。
1.5 神经网络配方中的四种成分
从训练神经网络的python代码中可能注意到了,我们需要将四种主要部分结合起来放入我们的神经网络和深度学习算法中:a dataset、 a model/architecture、a loss function和an optimization method。
(1)dataset
数据集是训练神经网络时的第一个部件,数据本身伴随着我们最终要解决的问题。在本书背景下,我们关注于图像分类,但是,你的数据集和你尝试解决的问题的结合将影响着你用于训练模型的损失函数、网络架构和优化方法的选择。通常,会给我们一些项目上能够期望得到某种结果的数据集,我们将在给定的数据集上训练一个对给定任务有帮助的机器学习模型。
(2)损失函数
给定数据集和目标,我们需要定义一个与我们要解决的问题一致的损失函数。在使用深度学习的几乎所有图像分类问题中,我们使用cross-entropy损失。对于>2分类我们称为categorical cross-entropy;对于二分类问题,我们称为binary cross-entropy。
(3)模型/架构
你的网络架构可能是你要考虑的作为第一个配方的真正的“选择”。你的数据集可能根据具体任务已经给你了,在执行分类时,可能选择cross-entropy作为损失函数。
但是,你的网络架构是动态的,特别是当你选择哪种优化方法作为训练你的网络的时候。应当花时间探索你的数据集并了解:有多少数据点、类别数目多少、这些类别有多相似/不相似、类内差异。
你应当对你将要使用的网络架构开始有一种“感觉”。这需要实践,因为深度学习是科学的一部分,也是艺术的一部分——事实上,本书的其余部分致力于帮助你发展这两种技能。
注意,网络架构中的层和节点数目(伴随着正则化)随着你越来越经验丰富可能会改变。你收集的结果越多,你就越有能力在知情的情况下决定下一步尝试哪种技术。
(4)优化方法
最后一个部件是定义一个优化方法。SGD经常被使用,其它一些更高级的优化方法,如RMSprop、Adagrad、Adadelta、Adam等将在Practitioner Bundle中介绍。
即使有这么多新的优化方法,SGD仍然是深度学习—大部分神经网络使用SGD训练,包括在最新的IMAGENET上。当训练深度神经网络,特别是你第一次进入学习这个领域时,SGD应当是你优化器的选择。之后,应该设置一个合适的学习率和正则化强度、网络训练的epochs数目、是否使用momentum和Nesterov acceleration。花些时间尽可能熟悉SGD且熟悉调整SGD参数。
熟悉一个给定的优化器类似于如何开车,你熟悉开自己的车而不是别人的车是应为你花费了大量的时间在开自己车上,你熟悉你的车以及它的复杂性。通常情况下,在一个数据集上选择一个给定的优化器来训练网络,不是因为这个优化器本身有多好,而是因为“车手”(如深度学习实践者)更熟悉这个优化器并且理解了调整它相关参数背后的“艺术”。
记住,即使是在一个小/中型数据集上获得一个性能合理的神经网络,即使对于高级的深度学习用户来说,也需要10到100个实验,因此即使你的网络执行的极其不好也不要沮丧。精通深度学习需要投入你的时间和做很多实验,但一旦你掌握了这些要素是如何结合在一起的,这是值得的。
1.6 权重初始化
在结束本章之前,这里简单的讨论权重初始化(weight initialization)的概念,即如何初始化权重矩阵和偏置向量。本节无意成为全面的初始化技术,但是它确实是很流行的方法,来自深度学习文献以及一些经验法则,这里会使用一些python代码演示。
(1)常量初始化
当应用常量归一化(constant normalization)时,神经网络中的所有权值使用常量C初始化,通常C为0或1。
这里为了可视化,假定输入64,输出32(不包含偏置项)那么,0初始化可表示为W = np.zeros((64, 32)),1初始化可表示为W = np.ones((64, 32)),那么任意C的常量初始化为W=np.ones((64, 32))*C。尽管这种方法很简单,但是它对于破坏激活函数的对称性[2]几乎不可能,因此它很少用于深度学习权重初始化。
(2)均匀和正太分布
均匀分布(uniform distribution)是在范围[lower, upper]之间的随机值,这个范围内的每个值都等概论的出现。再次假定我们的神经网络的给顶层有64输入和32输出,我们希望在lower=-0.05和upper=0.05之间初始化权重,则可根据下式进行初始化,将获得64*32个等概论的随机值W=np.random.uniform(low=-0.5, high=0.5, size=(64, 32))。
正太分布(normal distribution)即定义的高斯分布的概率密度:
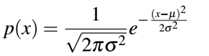
这里最重要的参数是均值μ和标准差δ,标准差的平方 称为方差。当使用keras的random.normal库生成μ=0.0,δ=0.5的正太分布值时,可写为W=np.random.normal(0.0, 0.5, size=(64, 32))。
均匀分布和正太分布都可以用于初始化神经网络权重,但是我们通常采用各种启发式方法来创造更好地初始化机制。
(3)LeCun均匀和正太
如果使用Torch7或PyTorch框架,可能注意到默认的权重初始化方法称为“Efficient Backprop”,由LeCun推导得到。作者定义了参数Fin(层的输入数目)和Fout(层的输出数目),则均匀初始化定义为:

Keras库使用截断的正太分布:

(4)Glorot/Xavier Uniform and Normal
Keras库中默认的权重初始化方法是由Xavier Glorot命名的称为“Glorot initialization”或“Xavier initialization”。
均值为0的正太分布可以如下形式初始化:

而Glorot/Xavier initialization分布则可有均值分布实现:

使用这种初始化方法的学习相当有效,我建议大多数神经网络都使用这种方法。
(5)He et al./Kaiming/MSRA Uniform and Normal
还有一种称为“He et al. initialization”, “Kaiming initialization”, 或仅仅是 “MSRA initialization”的初始化方法,该方法通常用于训练非常深的使用类似ReLU激活函数(特别是PReLU)的神经网络中。
均匀分布初始化如下:

正太分布初始化如下:

我们将在大图像数据集上训练非常深的神经网络时的Practitioner Bundle和ImageNet Bundle中讨论这种初始化方法。
(6)初始化应用的差异
在不同文献中,可能这个实际的limit会不同,这需要在不同文献中具体对待。
2 总结
不幸的是,正如我们的一些研究结果(如CIFAR-10)所表明的那样,当我们使用在翻译、旋转、视点等方面存在显示差异的具有挑战性的图像数据集时,标准神经网络无法获得较高的分类精度。我了在这些数据集上获得合理的精确度,我们需要工作在称为CNNs(Convolutional Neural Networks,卷积神经网络)的特殊前馈神经网络类型上。
3 附录
[1] Jürgen Schmidhuber. “Deep Learning in Neural Networks: An Overview”. In: CoRR
abs/1404.7828 (2014). URL: http://arxiv.org/abs/1404.7828
(cited on pages 29,
128).
[2] Greg Heinrich. NVIDIA DIGITS: Weight Initialization.
https://github.com/NVIDIA/
DIGITS/blob/master/examples/weight-init/README.md. 2015 (cited on pages 165,
167).
以上是关于第10章神经网络基础的主要内容,如果未能解决你的问题,请参考以下文章