系统运维 SysOM profiling 在云上环境的应用观测实践
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统运维 SysOM profiling 在云上环境的应用观测实践相关的知识,希望对你有一定的参考价值。

背景
云上环境,ECS客户一般都会布置一些常规监控观察系统指标或者业务指标,虽然通过这些指标能监控到系统或者应用的异常,但是却不能完全了解系统/应用正在做什么导致的指标异常。常见的如:看到系统CPU偶尔飙高却不知道是哪个应用引起、抓包发现报文已经到达了本机却不知道应用为何迟迟不收包等等,束手无策之余只能认为“系统有问题” ,而在排查系统问题之后发现往往是应用对系统资源在做一些野蛮消耗,这些应用有些是业务自身,有些则悄悄躲在"ps -ef"的千百个任务中,很难发现。于是我们想通过profiling的方式去观测系统/应用的运行行为,帮助客户解决难题。
实现方案
所谓的"profiling"可以认为是以一种动态的方式去观测程序的执行逻辑,这个程序可以大到一个操作系统,甚至是一个基础设施,有兴趣的同学可以看下文[1],也可以小到一个pod,甚至一个简单的应用程序。如果在这种方式上再增加一个时间维度,持续性得以“profiling”的方式去做观测,对上面说的常见系统资源偶现指标异常等问题就可以做一个很好的追踪,不需要苦苦守着问题出现。
那么如何去做 profiling 呢?
不同的编程语言有不同的profiling工具,像go的pprof,java的jstack等,这里我们希望观测应用但又想抛开语言的差异化,于是我们借助eBPF来实现程序栈信息的获取,这里的栈信息包括一个应用在用户态执行和内核态的执行的全部信息。借助eBPF的好处在于我们可以做到profiling过程的可控 :频率快慢、运行时安全、系统资源占用小等。
如下图所示,通过 eBPF 加 PMU(Performance Monitoring Unit)事件我们就可以定期获取应用的执行栈信息,同时利用 bpf map 对每个应用的栈信息做统计。借助我们前期开源的 Coolbpf(eBPF 开发编译框架,具备 CORE、高低版本适配能力),我们对不同的内核版本做了相关适配,具体可执行版本见下文。
profiling应用的哪些行为逻辑
一个程序的运行时最简单得可以概括为执行和不执行两种状态 ,即on cpu和off cpu。on cpu我们希望看到程序占用cpu时的执行逻辑,哪个任务甚至任务的哪一段代码在cpu上消耗资源,而off cpu我们希望看到应用是否是自愿放弃的cpu,出于何种原因不占用cpu,如等锁、等io等,以此希望发现一些应用等锁耗时造成的收发包延迟等问题。
针对网络抖动的常见问题我们在收包的两个阶段:
- 硬中断和软中断收包,
- 用户态应用进程系统调用取包,也做了相关的profiling观测:
如何持续的profiling
整体我们采用 c/s 的架构方式,日常问题定位中我们只需要部署 agent 去负责 profiling,在 server 端去查看数据。同时将 profiling 数据做切片处理,定时从 map 中拿数据并清空 map 上一周期的采样数据,这样的话确保我们在做数据回放的时候看到的是对应时间段的 profiling 结果 。考虑用户对云上环境数据安全的要求,我们也可以借助 SLS 通道完成数据上传。
使用说明
在 SysOM 上可以有两种使用方式。
如果想持续性的观测系统那么可以监控模式下 profiling 功能,对应路径在:监控中心->机器 ip->General dashboard->sysom-profiling。
如果是想获取 profiling 的一些结论性信息可以通过诊断模式,对应路径在:诊断中心->调度诊断中心->应用 profile 分析。
当前会统计 top 10 应用 CPU 占用百分比,同时会将热点栈信息展示出,热点栈在应用自身所有栈信息的百分比也会做一个统计,最后会对热点栈做个分析,明确热点栈是在应用自身还是在 OS。
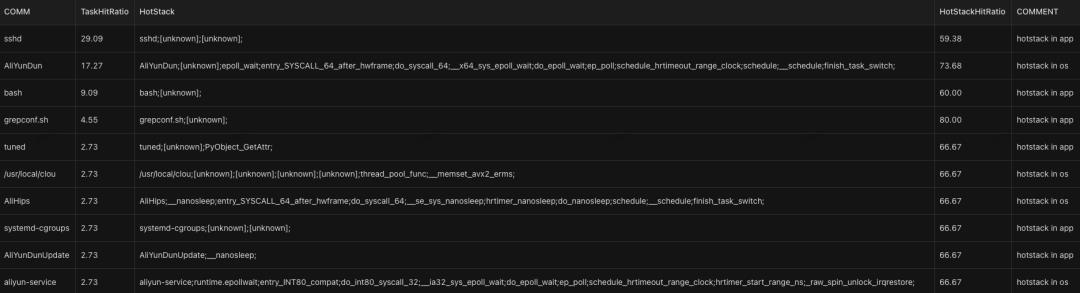
以上展示的是 oncpu 的面板信息,profiling 的其他功能的面板信息持续适配中。
具体 profiling 功能可以执行 sysAK 统一监控目录下的 raptor 获取,除了功能项也可以设置运行模式等。
运行模式
| 常规模式 | trigger模式 | filter模式 |
| 定时触发去profiling,默认5分钟一次 | 设定指标阈值异常时触发 | 限定应用或者cpu,针对明确了异常应用或者应用绑核只在特定cpu上有问题场景 |
profilng功能支持的内核版本
CentOS 7.6 及以上,alinux2/3、anolis,同时也支持了倚天 Arm 架构。
相关案例
1.某用户 CPU 指标偶有飙高,而相同业务的其他机器并无异常,怀疑 ECS 资源有问题
ecs 监控如下:
由于是间歇性抖动,常规手段较难抓到现场,对系统持续 profiling 一天后发现抖动时刻对应系统上 nginx 应用占用的 CPU 最多,并且 nginx 主要在做收发包处理,用户优化业务流量请求分布后该问题得到解决。

2.某用户系统业务压力没有增加的情况下 sys 指标莫名升高
用户监控如下:
对系统做 profiling 观测后发现有个 cachestat 脚本开启了 ftrace 功能,该脚本是之前同学定位问题部署后没有及时停止,停掉脚本后系统恢复正常。由于 ftrace 不是通过 sysfs 目录打开,查看 sysfs 的 ftrace 其实并无改动。
3.某用户机器 CPU 指标异常,ssh 无法登陆,整机夯住
用户监控图如下:
ssh 无法登陆、CPU 指标异常、内存有压力,根据“经验”一般怀疑系统在做内存回收,但是通常情况下无法拿到第一现场佐证,没有说服力。通过 profiling,部署一天,我们抓到了第一现场,13:57 分 CPU 占用异常高,大阳线拔地而起,再看系统行为就是内核占着 CPU 在做内存回收,随后建议用户优化应用的内存使用。该问题可以算是云上环境的“经典问题”。

4.某用户机器 ping 报文偶现秒级时延抖动
ping 主机偶现秒级的时延抖动,同时伴随个别 CPU sys 偶现占用达到 100%。
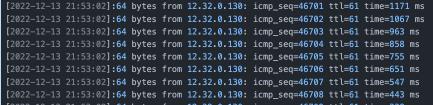
由于是个别 CPU 的短暂抖动,因此我们对某一 CPU 上的执行情况做 profiling。我们看到网络抖动时间点,runc 在读 /proc/cpuinfo 信息,“smp_call_function_single”核间call 存在热点,跟我们看到的 sys 偶尔高现象也能吻合。
最终容器同学通过对 cpuinfo 信息缓存备份以减少对 /proc/cpuinfo 的访问,缓解系统压力,当然高版本内核对 /proc/cpuinfo 的访问也做了部分优化,相关 patch 见[4]。
总结
SysOM 致力打造一个集主机管理、配置部署、监控报警、异常诊断、安全审计等一些列功能的自动化运维平台。以上是对 SysOM profiling 功能的相关介绍,由于篇幅有限只介绍了部分案例,相关功能模块已完成功能验证,正在开源中,敬请期待。
更多的运维技术,可关注我们的gitee开源运维仓库:
SysOM:https://gitee.com/anolis/sysom
SysAK:https://gitee.com/anolis/sysak
Coolbpf:https://gitee.com/anolis/coolbpf
参考
[1]《Google-Wide Profiling: A Continuous Profiling Infrastructure for Data Centers》
[2]《Observability Engineering》
[3] http://www.brendangregg.com/perf.html
[4] https://www.mail-archive.com/linux-kernel@vger.kernel.org/msg2414427.html
本文为阿里云原创内容,未经允许不得转载。
以上是关于系统运维 SysOM profiling 在云上环境的应用观测实践的主要内容,如果未能解决你的问题,请参考以下文章