第36篇 多进程的数据共享,进程池的回调函数,线程 什么是GIL锁,Threading模块记
Posted cavalier-chen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第36篇 多进程的数据共享,进程池的回调函数,线程 什么是GIL锁,Threading模块记相关的知识,希望对你有一定的参考价值。
内容概览:
进程
数据共享
进程池--回调函数
线程
线程的基础理论
什么是线程?
线程与进程的关系
GIL锁
线程的开启:
Threading模块
1,用多进程开启socket创建聊天
server端写了input函数会报错?因为服务器是高速运行的,自动化的为来访问的客户端提供服务,
不可能停下来等待管理员的输入,然后发送给客户。这就失去了自动化的意义。
2,进程池Pool()方法创建的进程,map()方法是否有返回值?
p.map()得到的是迭代对象
import time
from multiprocessing import Pool,Queue,Pipe
def func(q):
print(q)
time.sleep(1)
return q
if __name__ == ‘__main__‘:
p = Pool()
ret = p.map(func,range(10))
for i in ret:
print(‘-->‘,i)
0 1 2 3 4 5 6 7 8 9 --> 0 --> 1 --> 2 --> 3 --> 4 --> 5 --> 6 --> 7 --> 8 --> 9
import time,os
from multiprocessing import Pool,Queue,Pipe
def func(q):
print(q)
time.sleep(1)
print(os.getpid())#打印进程的pid
return q
if __name__ == ‘__main__‘:
p = Pool()
ret = p.map(func,range(10))
for i in ret:
print(‘-->‘,i)
#CPU是4核的,进程池默认最多开4个进程 0 1 2 3#这4个几多几乎同时得到 8156#进程PID1 4 7768#进程PID2 5 1780#进程PID3 6 7180#进程PID4 7 8156 8 7768 9 1780 7180 8156 7768 --> 0#进程的返回值 --> 1 --> 2 --> 3 --> 4 --> 5 --> 6 --> 7 --> 8 --> 9
内容回顾:
# p = Pool()默认是CPU的个数
#使用进程池提交任务
#p.apply()
同步提交,
函数直接可返回结果
ret = p.apply(函数名,参数)
#p.apply_async 异步提交
#不会直接返回函数的结果,返回的是一个对象,可以通过get()方法取值
#ret = p.apply_async(函数名,参数)
#ret_list.append(ret)
#for i in ret_list:
print(i.get())
#p.close()关闭进程池
#p.join()
#map方法
#得到的是返回值的可迭代对象
#通过for循环就可以取值
多进程与进程池的区别:
多进程:
由操作系统统一来调度
常见的进程越多,占用的资源就越多
操作系统的效率就会下降
进程池:
进程池中运行的进程数量是非常有限的
用户量比较大的时候就会导致,服务器的响应变慢
数据共享:
from multiprocessing import Manager,Process,Lock
def work(dic,lock):
dic[‘count‘] -= 1
if __name__ == ‘__main__‘:
lock = Lock()
m = Manager()
dic = m.dict({‘count‘:100})#Manager类中的dic()方法,传入参数将字典设置成共享数据
p_list = []
for i in range(20):
p = Process(target=work,args=(dic,lock))
p_list.append(p)
p.start()
for p in p_list:
p.join()
print(dic)
{‘count‘: 80}
说明:
开启20个进程,异步的哦,对共享的字典进行修改,本来,进程去取数据,修改之后再放回去,
但是由于进程额执行是需要一段时间的,有可能两个进程同时取到的都是99,然后修改再放进去,
这样就会出现偏差。
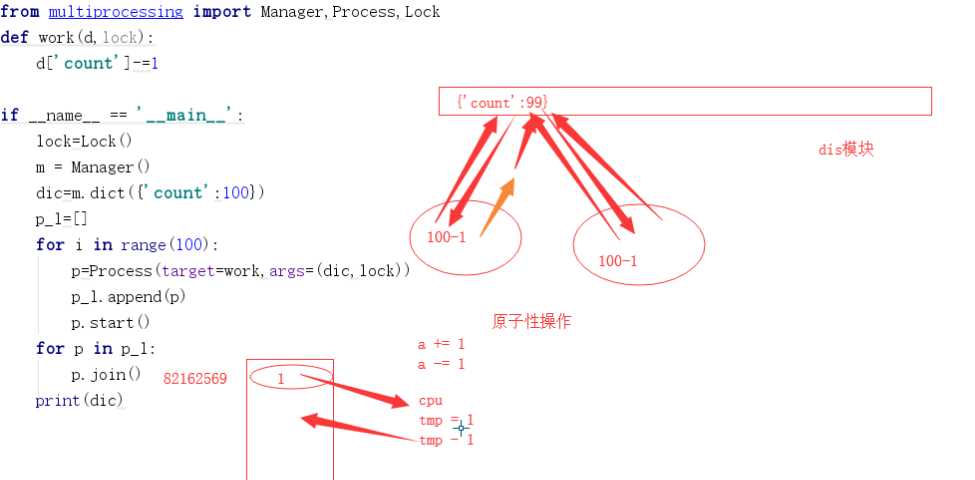
解决问题的办法就是加锁,只能允许一个进程进来取数据,
from multiprocessing import Manager,Process,Lock
def work(dic,lock):
lock.acquire()
dic[‘count‘] -= 1
lock.release()
if __name__ == ‘__main__‘:
lock = Lock()
m = Manager()
dic = m.dict({‘count‘:100})#Manager类中的dic()方法,传入参数将字典设置成共享数据
p_list = []
for i in range(20):
p = Process(target=work,args=(dic,lock))
p_list.append(p)
p.start()
for p in p_list:
p.join()
print(dic)
{‘count‘: 80}
有时间的话研究一下:
with 的用法
dis模块
面向对象的魔术方法:__enter__ __exit__
cpu的时间观念
回调函数:
回调函数的作用,以及应用场景:
子进程有大量的计算,或者访问网页,需要一定的时间才能完成,
回调函数等待子进程的结果,然后做简单的处理,得到结果
例如:例如子进程访问网页,主进程将网页写入文档
url_list = [
‘http://www.baidu.com‘,
‘http://www.sohu.com‘,
‘http://www.sogou.com‘,
‘http://www.cnblogs.com‘,
]
import re
from urllib.request import urlopen
from multiprocessing import Pool
def get_url(url):
respons = urlopen(url)
pattern = ‘www.(.*?).com‘
ret = re.search(pattern,url)
print(‘%s finished‘%ret.group(1))
return ret.group(1),respons.read()
def write(content):
url,con = content
with open(url+‘.html‘,‘wb‘) as f:
f.write(con)
if __name__ == ‘__main__‘:
p = Pool()
for url in url_list:
p.apply_async(get_url,args=(url,),callback=write)
#采用异步提交的方法p.apply_async,不能忘记写上close、join
p.close()
p.join()
baidu finished sohu finished sogou finished cnblogs finished
正式进入线程
先回顾一下进程
程序是不能单独的自己运行,只有将程序加载到内存,有操作系统分配资源,在能运行,这种执行中额程序就叫做进程
进程与程序的区别:
程序是指令的集合,是程序运行的静态描述文本,
进程是程序的一次执行活动,
多道编程中,允许多个程序同时加载到内存中,在操作系统的调度下,,可以实现并发的执行,这样大大的提高了CPU的效率,
进程的出现,让用户感觉自己是独享CPU
线程的出现
60年代,操作系统中,能够拥有资源和独立运行的基本单位是进程,进程出现一些弊端:
进程是资源的拥有者,创建,撤销和切换会消耗大量的时间,多个进程并行开销过大
于是出现了能够独立运行的基本单位---线程thread
注意两点:
进程是资源分配的基本单位
线程是调度的最小单位
每个进程至少有一个线程
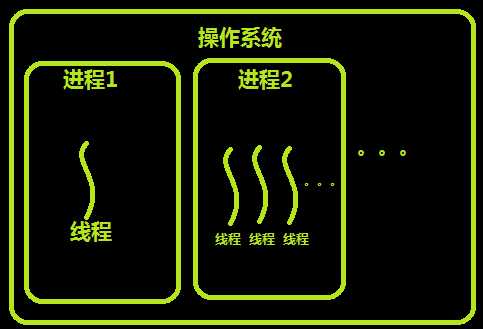
进程与线程的区别:
#资源共享:
进程之间是相互独立的,同一个进程的各个线程之间资源共享,
#通讯:
线程间是可以直接读取所在的进程中的数据段(比如:全局变量)来进行通讯,
进程之间的通讯:队列,管道。。
#切换速度:
线程的上下文切换,比进程快得多
线程的特点:
通常情况下,一个进程包含多个线程,么个线程作为利用CPU的基本单位,是花费自小开销的实体,
1)轻型实体
线程中的实体基本不拥有系统资源,只拥有:
程序,数据,TCB包,线程是动态概念,动态特性有线程控制模块TCB(thread control block)描述:
TCB包含以下信息:
线程状态
线程不运行时,线程数据
一组执行堆栈
线程的局部变量
访问同一个进程的主存 和 其他资源
2)独立调度和分派的基本单位
在多线程操作系统中,线程是能够独立运行的基本单位,因而也是能够独立调度和分派的基本单位,
由于线程的很轻,因此线程的切换非常迅速,开销很小
3)共享进程的资源
在同一进程中的各个线程,可以共享该进程所拥有的资源,具有相同的pid,因此可以访问进程的每一个内存资源,
此外还可以访问进程所拥有的已打开文件,定时器,信号量机构等。
4)可并发性
在一个进程的多个线程之间,可以并发执行,
全局解释器锁GIL
虽然python解释器中可以运行多个线程,但是在任意时刻只有一个线程在解释器在解释器中运行,
对python虚拟机的访问,由全局解释器锁GIL控制,正是这个锁保证同一时刻只能一个线程在运行,
线程之间的切换,python虚拟机按一下方式执行:
设置GIL
切换到一个线程去运行
运行指定数量的字节码指令,或者线程主动让出控制
把线程设置成睡眠状态
解锁GIL
重复以上的步骤
Thread模块:
子线程的开启
import time,os
from threading import Thread
def func(i):
time.sleep(0.5)
print(‘子线程:‘,i,os.getpid())
for i in range(10):
print(‘进程:‘,i ,os.getpid())
t = Thread(target=func,args=(i,))
t.start()
进程: 0 8740 进程: 1 8740 进程: 2 8740 进程: 3 8740 进程: 4 8740 进程: 5 8740 进程: 6 8740 进程: 7 8740 进程: 8 8740 进程: 9 8740 子线程: 0 8740 子线程: 1 8740 子线程: 2 8740 子线程: 3 8740 子线程: 4 8740 子线程: 5 8740 子线程: 6 8740 子线程: 9 8740 子线程: 8 8740 子线程: 7 8740
进程与线程,线程与线程之间数据共享
变量可以相互的调用
from threading import Thread
num = 100
def func():
global num
num -= 1
print(‘线程‘,num)
t_list = []
for i in range(100):
t = Thread(target=func)
t.start()
t_list.append(t)
for i in t_list:
t.join()
print(‘进程‘,num)
线程的几个方法:
t.setName()
t.getName()
t.is_alive()
currentThread()
currentThread().ident
from threading import Thread
import time
def func():
time.sleep(3)
t = Thread(target=func)
t.start()
print(t.is_alive())
print(t.getName())
t.setName(‘alex‘)
print(t.getName())
True Thread-1 alex
from threading import Thread,currentThread
import time
def func():
print(‘子线程:‘,currentThread().ident)
time.sleep(3)
print(‘主线程‘,currentThread().ident)
t = Thread(target=func)
t.start()
主线程 6752 子线程: 9324
#from threading import Thread,currentThread,enumerate,activeCount
查看当前的进程,
查看进程数,
import time
from threading import Thread,currentThread,enumerate,activeCount
def func():
print(‘子线程:‘,currentThread().ident)
time.sleep(3)
print(‘主线程‘,currentThread().ident)
for i in range(10):
t = Thread(target=func)
t.start()
print(len(enumerate()))
print(activeCount())
守护线程:
t1.setDaemon(True)
import time
from threading import Thread
def func1():
while True:
time.sleep(0.5)
print(‘子线程1‘)
def func2():
print(‘func2 start‘)
time.sleep(2)
print(‘func2 end‘)
t1 = Thread(target=func1)
t2 = Thread(target=func2)
t1.setDaemon(True)#设置成守护线程
t1.start()
t2.start()
print(‘主线程结束‘)
func2 start
主线程结束
子线程1
子线程1
子线程1
func2 end
守护线程:
主代码结束之后,会等待子线程执行结束之后 才会结束
使用threading模块 写一个TCP通讯
sever端:
import socket
from threading import Thread
def communicate(conn):
while True:
conn.send(b‘hello‘)
print(conn.recv(1024))
if __name__ == ‘__main__‘:
sk = socket.socket()
sk.bind((‘127.0.0.1‘,8989))
sk.listen()
while True:
conn,addr = sk.accept()
t = Thread(target=communicate,args=(conn,))#采用线程开启
t.start()
client端:
import socket
sk = socket.socket()
sk.connect((‘127.0.0.1‘,8989))
while True:
print(sk.recv(1024))
sk.send(b‘bye‘)
以上是关于第36篇 多进程的数据共享,进程池的回调函数,线程 什么是GIL锁,Threading模块记的主要内容,如果未能解决你的问题,请参考以下文章