数据库的索引
Posted xiaocao123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库的索引相关的知识,希望对你有一定的参考价值。
数据库的索引
本文参考如下博客:https://www.cnblogs.com/tgycoder/p/5410057.html
https://www.cnblogs.com/aspwebchh/p/6652855.html
索引的本质
mysql官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是一种数据结构。
数据库查询是数据库的主要功能之一,最基本的查询算法是顺序查找(linear search)时间复杂度为O(n),显然在数据量很大时效率很低。优化的查找算法如二分查找(binary search)、二叉树查找(binary tree search)等,虽然查找效率提高了。但是各自对检索的数据都有要求:二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织)。所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构。这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构就是索引。
看一个例子:
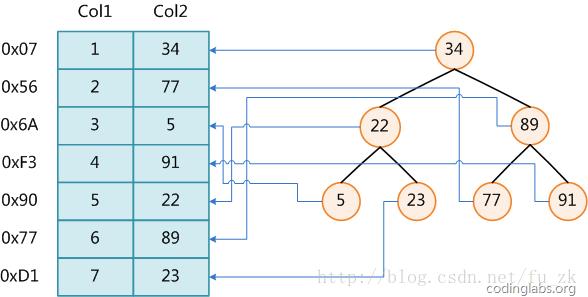
图1
图1展示了一种可能的索引方式。左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在O(log2n)的复杂度内获取到相应数据。
虽然这是一个货真价实的索引,但是实际的数据库系统几乎没有使用二叉查找树或其进化品种红黑树(red-black tree)实现的,原因会在下文介绍。
B+Tree
B-Tree有许多变种,其中最常见的是B+Tree,例如MySQL就普遍使用B+Tree实现其索引结构。
与B-Tree相比,B+Tree有以下不同点:
- 每个结点的指针上限为2d而不是2d+1。
- 内结点不存储data,只存储key;叶子结点不存储指针。
图3是一个简单的B+Tree示意。
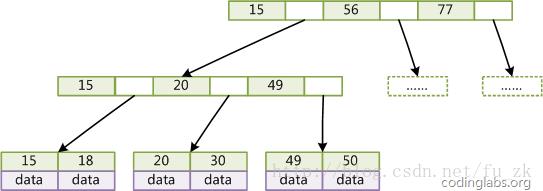
图3
由于并不是所有节点都具有相同的域,因此B+Tree中叶结点和内结点一般大小不同。这点与B-Tree不同,虽然B-Tree中不同节点存放的key和指针可能数量不一致,但是每个结点的域和上限是一致的,所以在实现中B-Tree往往对每个结点申请同等大小的空间。
一般来说,B+Tree比B-Tree更适合实现外存储索引结构,具体原因与外存储器原理及计算机存取原理有关,将在下面讨论。
带有顺序访问指针的B+Tree
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针。
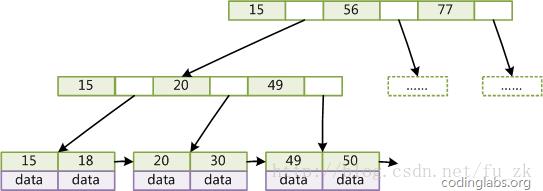
图4
如图4所示,在B+Tree的每个叶子结点增加一个指向相邻叶子结点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能,例如图4中如果要查询key为从18到49的所有数据记录,当找到18后,只需顺着结点和指针顺序遍历就可以一次性访问到所有数据结点,极大提到了区间查询效率。
MySQL索引实现
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎(MySQL数据库MyISAM和InnoDB存储引擎的比较)的索引实现方式。
MyISAM索引实现
MyISAM引擎使用B+Tree作为索引结构,叶结点的data域存放的是数据记录的地址。下面是MyISAM索引的原理图:
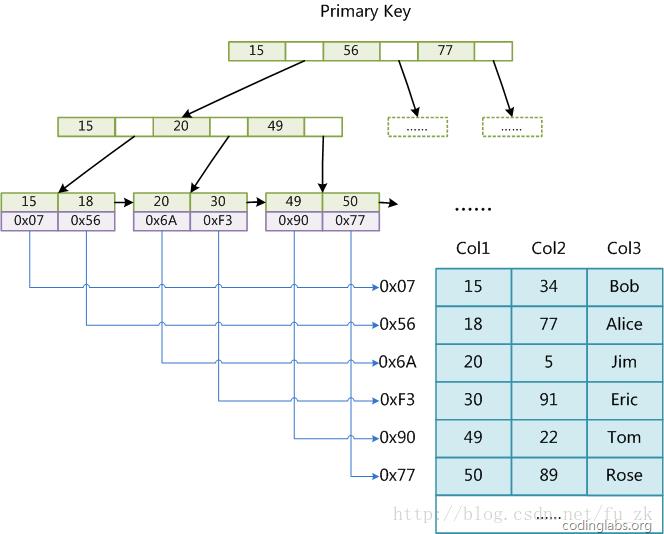
图8
这里设表一共有三列,假设我们以Col1为主键,则图8是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
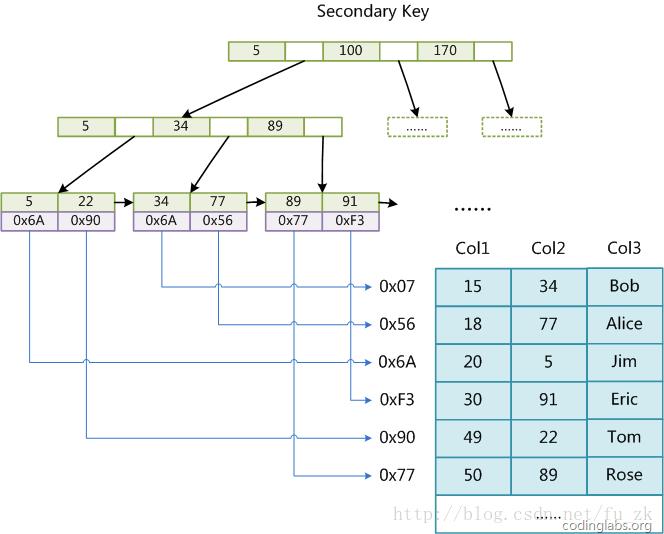
图9
同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
InnoDB索引实现
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶结点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
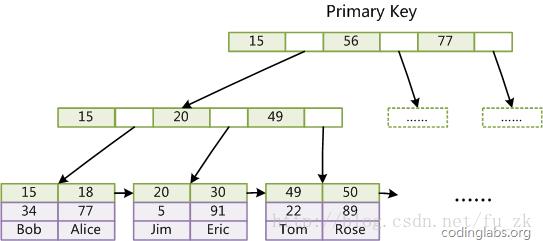
图10
图10是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶结点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,图11为定义在Col3上的一个辅助索引:
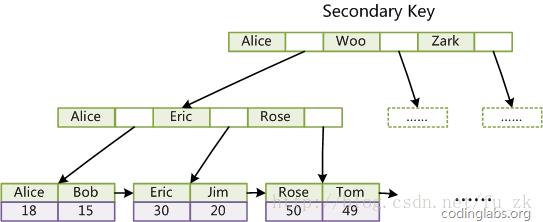
图11
这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
了解不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
以上是关于数据库的索引的主要内容,如果未能解决你的问题,请参考以下文章