Spark 3.1.1 shuffle fetch 导致shuffle错位的问题
Posted 鸿乃江边鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark 3.1.1 shuffle fetch 导致shuffle错位的问题相关的知识,希望对你有一定的参考价值。
背景
最近从数据仓库小组那边反馈了一个问题,一个SQL任务出来的结果不正确,重新运行一次之后就没问题了,具体的SQL如下:
select
col1,
count(1) as cnt
from table1
where dt = '20230202'
group by col1
having count(1) > 1
这个问题是偶发的,在其运行的日志中会发现如下三类日志:
FetchFailed
TaskKilled (another attempt succeeded)
ERROR (org.apache.spark.network.shuffle.RetryingBlockFetcher:231) - Failed to fetch block shuffle_4865_2481
283_286, and will not retry (3 retries)
最终在各种同事的努力下,找到了一个Jira:SPARK-34534
分析
直接切入主题,找到对应的类OneForOneBlockFetcher,该类会被NettyBlockTransferService(没开启ESS)和ExternalBlockStoreClient(开启ESS)调用,其中start方法:
public void start()
client.sendRpc(message.toByteBuffer(), new RpcResponseCallback()
@Override
public void onSuccess(ByteBuffer response)
try
streamHandle = (StreamHandle) BlockTransferMessage.Decoder.fromByteBuffer(response);
logger.trace("Successfully opened blocks , preparing to fetch chunks.", streamHandle);
// Immediately request all chunks -- we expect that the total size of the request is
// reasonable due to higher level chunking in [[ShuffleBlockFetcherIterator]].
for (int i = 0; i < streamHandle.numChunks; i++)
if (downloadFileManager != null)
client.stream(OneForOneStreamManager.genStreamChunkId(streamHandle.streamId, i),
new DownloadCallback(i));
else
client.fetchChunk(streamHandle.streamId, i, chunkCallback);
catch (Exception e)
logger.error("Failed while starting block fetches after success", e);
failRemainingBlocks(blockIds, e);
@Override
public void onFailure(Throwable e)
logger.error("Failed while starting block fetches", e);
failRemainingBlocks(blockIds, e);
);
其中的message的初始化在构造方法中:
if (!transportConf.useOldFetchProtocol() && isShuffleBlocks(blockIds))
this.message = createFetchShuffleBlocksMsg(appId, execId, blockIds);
else
this.message = new OpenBlocks(appId, execId, blockIds);
其中transportConf.useOldFetchProtocol 也就是 spark.shuffle.useOldFetchProtocol配置(默认是false),如果是shuffle block的话,就会运行到:createFetchShuffleBlocksMsg方法,对于为什么存在这么一个判断,具体参考SPARK-27665
关键的就是 createFetchShuffleBlocksMsg 方法:
这个方法的作用就是: 构建一个FetchShuffleBlocks(appId, execId, shuffleId, mapIds, reduceIdArr, batchFetchEnabled) 对象,其中里面的值
如图:
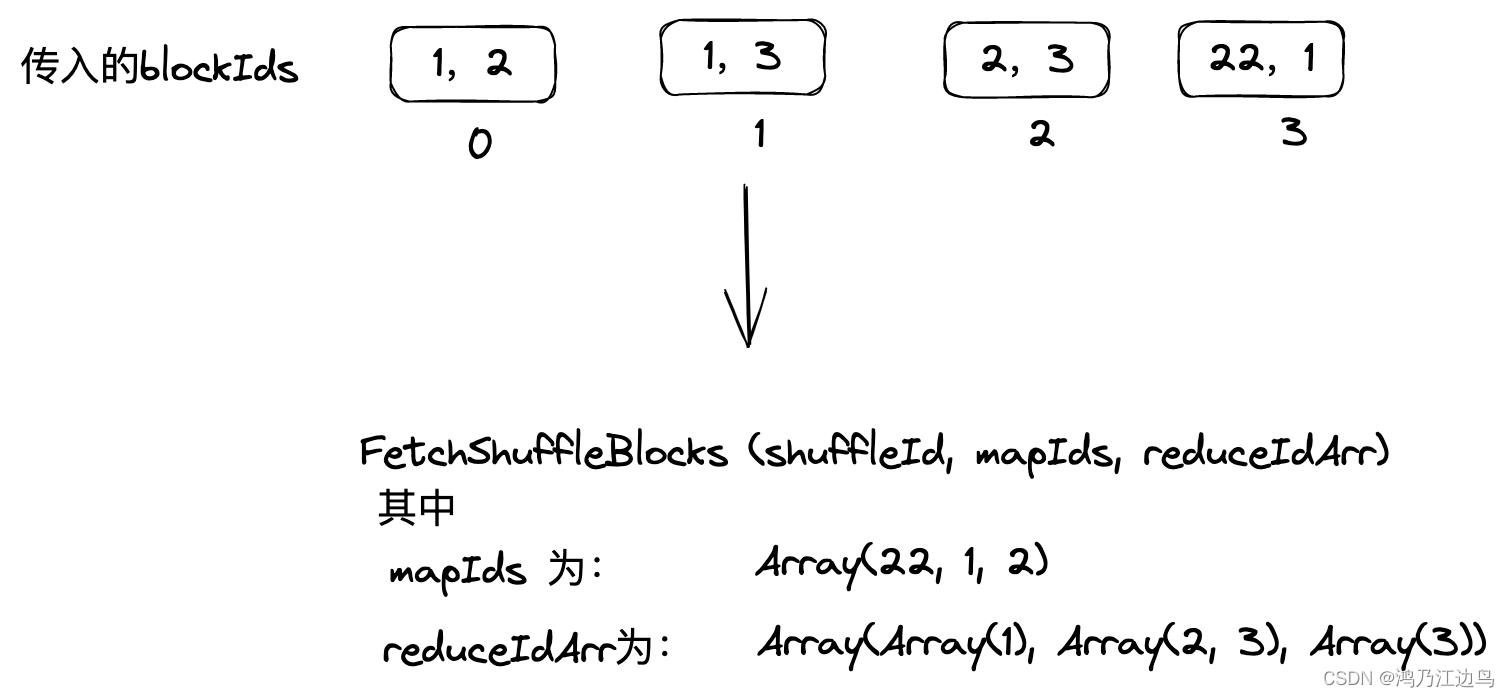
其中这里有一点需要注意:
long[] mapIds = Longs.toArray(mapIdToReduceIds.keySet());
reduceIdArr[i] = Ints.toArray(mapIdToReduceIds.get(mapIds[i]));
这里面对MapId和ReduceId 进行了重组(在获得streamHandle的时候内部会根据reduceIdArr构建blocks索引,下文中会说到)会导致和成员变量blockIds的顺序不一致,为什么两者不一致会导致问题呢?
原因在于任务的fetch失败会导致重新进行fetch,如下:
client.fetchChunk(streamHandle.streamId, i, chunkCallback);
chunkCallback的代码如下:
private class ChunkCallback implements ChunkReceivedCallback
@Override
public void onSuccess(int chunkIndex, ManagedBuffer buffer)
// On receipt of a chunk, pass it upwards as a block.
listener.onBlockFetchSuccess(blockIds[chunkIndex], buffer);
@Override
public void onFailure(int chunkIndex, Throwable e)
// On receipt of a failure, fail every block from chunkIndex onwards.
String[] remainingBlockIds = Arrays.copyOfRange(blockIds, chunkIndex, blockIds.length);
failRemainingBlocks(remainingBlockIds, e);
String[] remainingBlockIds = Arrays.copyOfRange(blockIds, chunkIndex, blockIds.length),此处的chunckIndex就是shuffle blocks的索引下标,也就是下文中numBlockIds组成的数组下标,
但是这个和createFetchShuffleBlocksMsg输出的顺序是不一致的,所以如果发生问题重新fetch的时候,数据有错位,具体可以看:
ShuffleBlockFetcherIterator中的
if (req.size > maxReqSizeShuffleToMem)
shuffleClient.fetchBlocks(address.host, address.port, address.executorId, blockIds.toArray,
blockFetchingListener, this)
else
shuffleClient.fetchBlocks(address.host, address.port, address.executorId, blockIds.toArray,
blockFetchingListener, null)
其中blockFetchingListener回调方法onBlockFetchSuccess会把fetch的block数据和shuffleBlockId一一对应上
ESS端构建blocks的信息
在start方法中,client.sendRpc向对应的ESS发送对应的请求shuffle数据信息,ESS会重新构建blocks的信息,组成StreamHandle(streamId, numBlockIds)返回给请求端:
具体为ExternalBlockHandler的handleMessage方法:
if (msgObj instanceof FetchShuffleBlocks)
FetchShuffleBlocks msg = (FetchShuffleBlocks) msgObj;
checkAuth(client, msg.appId);
numBlockIds = 0;
if (msg.batchFetchEnabled)
numBlockIds = msg.mapIds.length;
else
for (int[] ids: msg.reduceIds)
numBlockIds += ids.length;
streamId = streamManager.registerStream(client.getClientId(),
new ShuffleManagedBufferIterator(msg), client.getChannel());
。。。
callback.onSuccess(new StreamHandle(streamId, numBlockIds).toByteBuffer());
这里的numBlockIds就是OneForOneBlockFetcher中的streamHandle.numChunks
如图: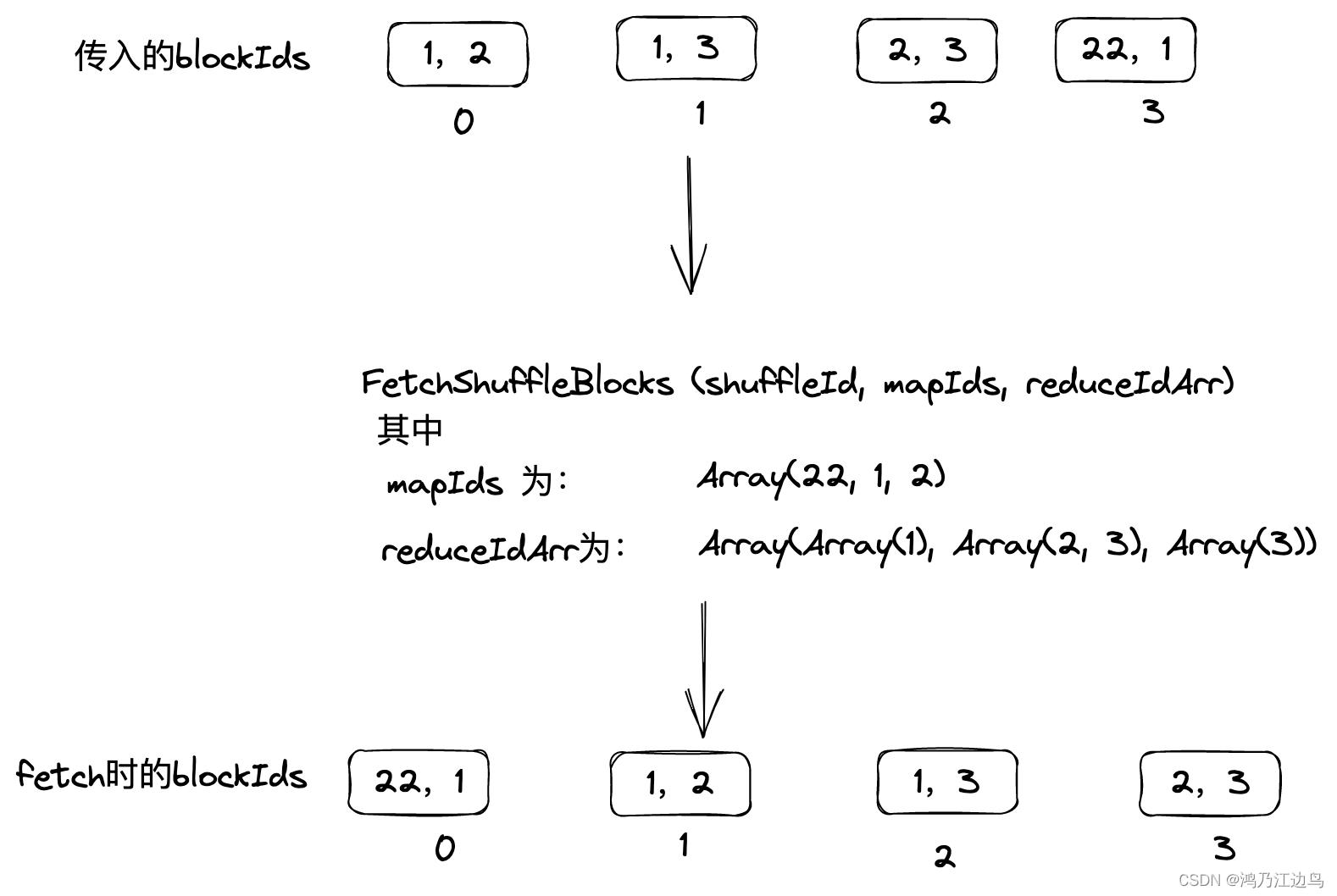
没有开启ESS端的构建blocks的信息
这里和上面的一样,只不过对应的方法为NettyBlockRpcServer的receive:
case fetchShuffleBlocks: FetchShuffleBlocks =>
val blocks = fetchShuffleBlocks.mapIds.zipWithIndex.flatMap case (mapId, index) =>
if (!fetchShuffleBlocks.batchFetchEnabled)
fetchShuffleBlocks.reduceIds(index).map reduceId =>
blockManager.getLocalBlockData(
ShuffleBlockId(fetchShuffleBlocks.shuffleId, mapId, reduceId))
else
val startAndEndId = fetchShuffleBlocks.reduceIds(index)
if (startAndEndId.length != 2)
throw new IllegalStateException(s"Invalid shuffle fetch request when batch mode " +
s"is enabled: $fetchShuffleBlocks")
Array(blockManager.getLocalBlockData(
ShuffleBlockBatchId(
fetchShuffleBlocks.shuffleId, mapId, startAndEndId(0), startAndEndId(1))))
val numBlockIds = if (fetchShuffleBlocks.batchFetchEnabled)
fetchShuffleBlocks.mapIds.length
else
fetchShuffleBlocks.reduceIds.map(_.length).sum
val streamId = streamManager.registerStream(appId, blocks.iterator.asJava,
client.getChannel)
logTrace(s"Registered streamId $streamId with $numBlockIds buffers")
responseContext.onSuccess(
new StreamHandle(streamId, numBlockIds).toByteBuffer)
这里的numBlockIds就是OneForOneBlockFetcher中的streamHandle.numChunks
如图:
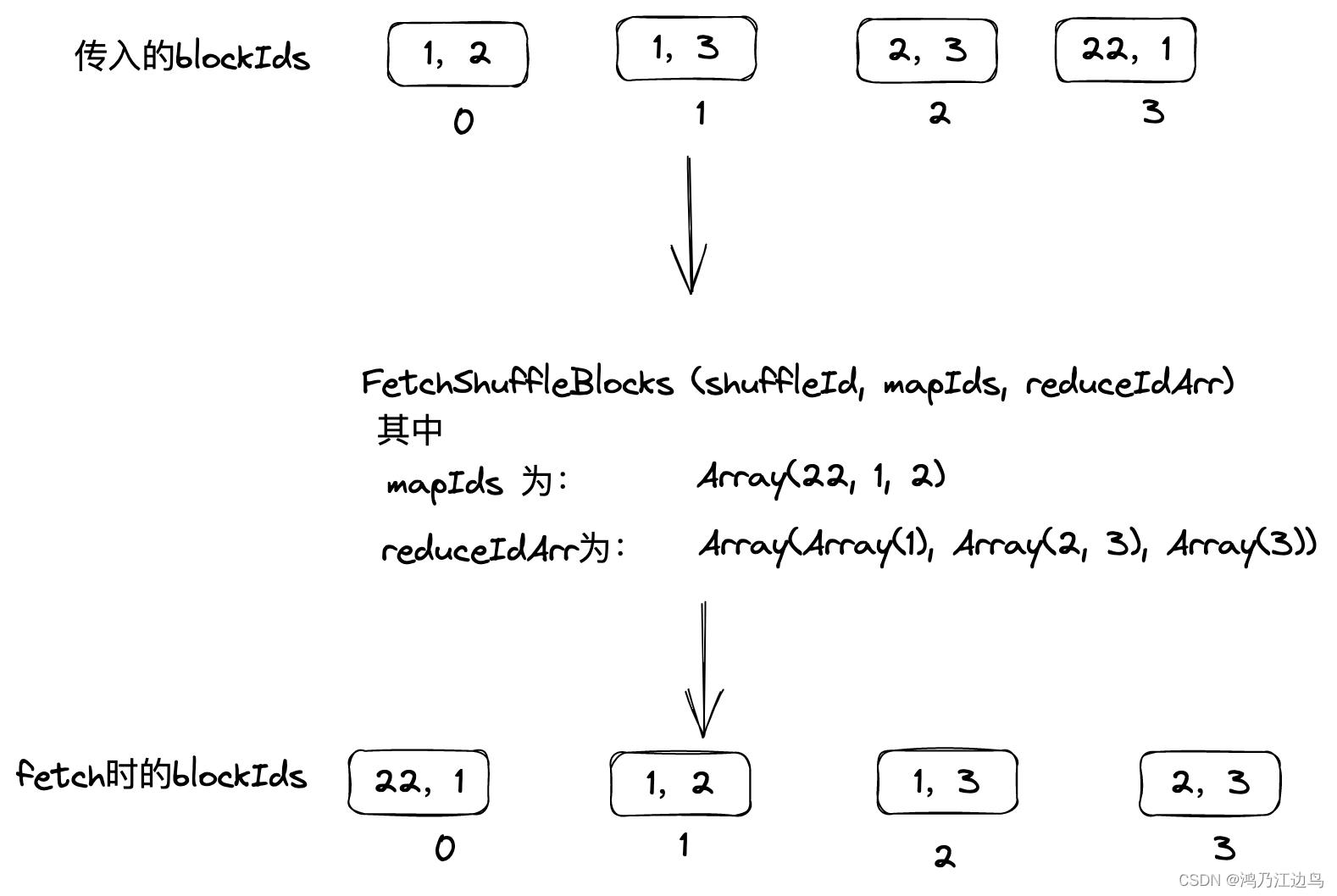
所以在以上两种情况下,只要有重新fetch数据的操作,就会存在数据的错位,导致数据的不准确
解决
直接git cherry-pick对应的commit就行:
git cherry-pick 4e438196114eff2e1fc4dd726fdc1bda1af267da
以上是关于Spark 3.1.1 shuffle fetch 导致shuffle错位的问题的主要内容,如果未能解决你的问题,请参考以下文章