论文阅读 | Restormer: Efficient Transformer for High-Resolution Image Restoration
Posted btee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读 | Restormer: Efficient Transformer for High-Resolution Image Restoration相关的知识,希望对你有一定的参考价值。
前言:CVPR2022oral 用transformer应用到low-level任务
Restormer: Efficient Transformer for High-Resolution Image Restoration
引言
low-level task 如deblurring\\denoising\\dehazing等任务多是基于CNN做的,这样的局限性有二:
第一是卷积操作的感受野受限,很难建立起全局依赖,
第二就是卷积操作的卷积核初始化是固定的,而attention的设计可以通过像素之间的关系自适应的调整权重
现有的transformer用于low-level任务最大的瓶颈在于分辨率太大了,自注意力机制的复杂度随着空间分辨率的增加二次增长,现有的一些解决方案有:
1.划成很多个8 * 8的像素小窗口,在这个小窗口内进行应用自注意力
2.化成不重叠的48 * 48的块,块与块之间进行自注意力机制
然而,这样的设计和transformer建立全局依赖的初衷是矛盾的
因此,本文解决了用transformer处理这类问题的计算复杂性,将其计算复杂度降低成和空间分辨率线性相关
改进了SA self-attention部分和feed-forward部分,并提出了一种渐进式patch训练方式来处理基于transformer的图像复原问题
相关工作
(这里不得不感叹看到这位作者介绍相关工作,都有一种被俯视的感觉,之前的一篇论文直接点某某,某某,are good examples, 这次直接建议阅读 NTIRE 挑战报告了)
方法
文章pipeline,类似Unet结构
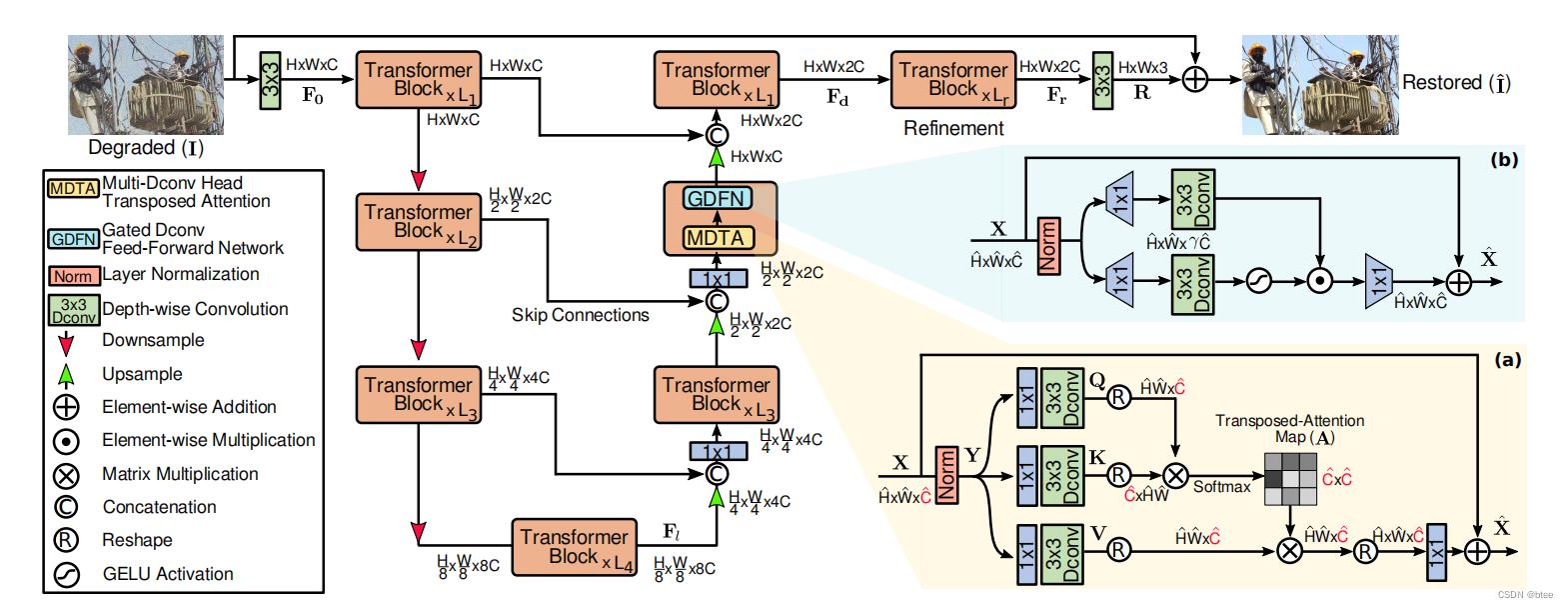
SA设计

这里最大的改动就是把HW * HW的attention变成了通道 * 通道的attention,计算量是降下来了,但是不过是把全局特征通道重组,没有办法建立空间像素关系的依赖,建立像素依赖的部分实际上还是3 * 3的按通道分组卷积Dconv(绿色方框)部分,(看到这样的设计都能有效果也是惊了)
其中,消融实验,可以看到 (a)(b)差别不大,但是MTA加上一个3 * 3的Dconv的提升很大,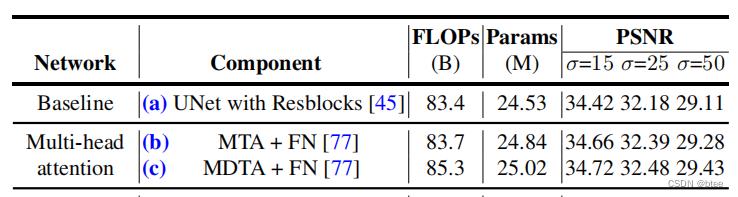 SA代码
SA代码
class Attention(nn.Module):
def __init__(self, dim, num_heads, bias):
super(Attention, self).__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
self.qkv = nn.Conv2d(dim, dim*3, kernel_size=1, bias=bias)
self.qkv_dwconv = nn.Conv2d(dim*3, dim*3, kernel_size=3, stride=1, padding=1, groups=dim*3, bias=bias)
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
def forward(self, x):
b,c,h,w = x.shape
qkv = self.qkv_dwconv(self.qkv(x))
q,k,v = qkv.chunk(3, dim=1)
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
attn = (q @ k.transpose(-2, -1)) * self.temperature
attn = attn.softmax(dim=-1)
out = (attn @ v)
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)
out = self.project_out(out)
return out
FN设计
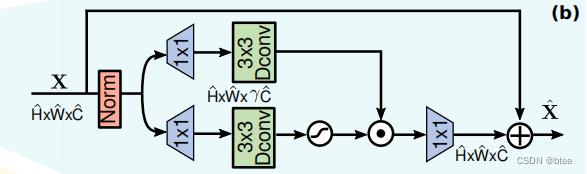
和传统的Feed-forward部分不同,这里分了两支进行MLP,并且HW依旧保持排列好的状态所以还是可以用3 * 3 分组卷积,下面的分支过了一个GeLU激活函数与上面的分支相乘
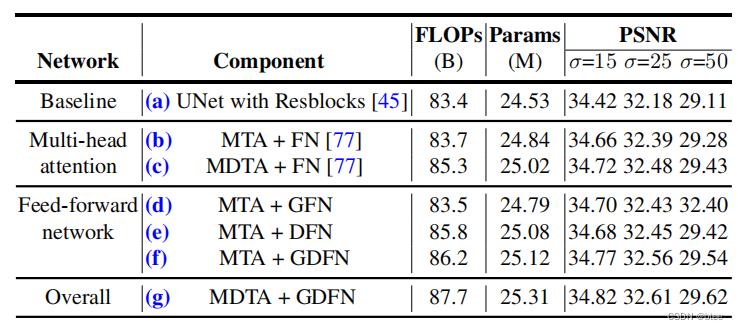
消融实验
可以看到 (b)(d)比较,单加上一个gated分支反倒效果不好,但(b)(e)直接上3 * 3的按通道分组卷积效果提升很明显,起作用的还是3 * 3的卷积核来学习空间信息
FN的设计代码
class FeedForward(nn.Module):
def __init__(self, dim, ffn_expansion_factor, bias):
super(FeedForward, self).__init__()
hidden_features = int(dim*ffn_expansion_factor)
self.project_in = nn.Conv2d(dim, hidden_features*2, kernel_size=1, bias=bias)
self.dwconv = nn.Conv2d(hidden_features*2, hidden_features*2, kernel_size=3, stride=1, padding=1, groups=hidden_features*2, bias=bias)
self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)
def forward(self, x):
x = self.project_in(x)
x1, x2 = self.dwconv(x).chunk(2, dim=1)
x = F.gelu(x1) * x2
x = self.project_out(x)
return x
实验
作者做了去雨、去糊、去噪等实验,在各个数据集上效果都挺好的
去糊实验结果
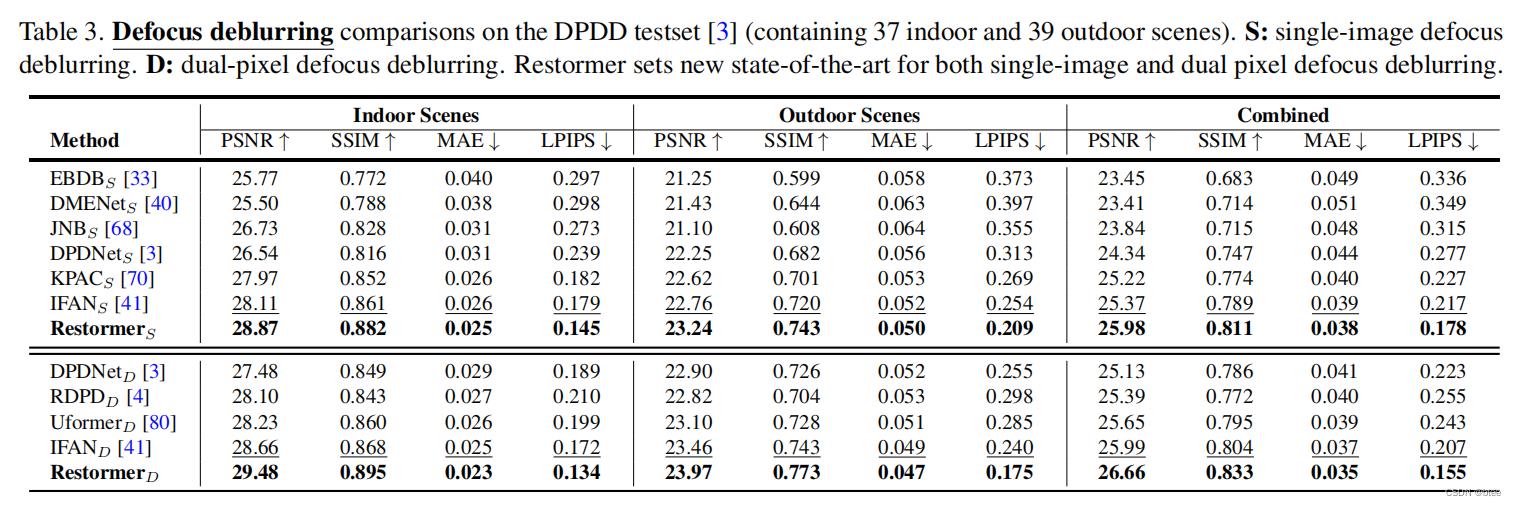

总结
虽然这是一篇transformer的文章,但是通道与通道之间的注意力和传统的Transformer也没什么联系了,并且前文花了很多篇幅讲transformer可以建立起 long-range pixel interactions,但是网络设计却仍然还是没有利用到transformer的全局像素依赖的这个属性
(个人疑惑的一个点是在于,既然简单的几层堆叠 [4,6,6,8] 的3*3的空间像素层上的卷积依赖已经能有这么好的效果,long-range pixel interactions对于low-level的任务真的有必要吗…)
以上是关于论文阅读 | Restormer: Efficient Transformer for High-Resolution Image Restoration的主要内容,如果未能解决你的问题,请参考以下文章