Hbase 表设计和高级属性
Posted mlxx9527
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase 表设计和高级属性相关的知识,希望对你有一定的参考价值。
1、compression
默认值是 NONE 即不使用压缩, 这个参数意思是该列族是否采用压缩,采用什么压缩算 法
方法: create ‘table‘,{NAME=>‘info‘,COMPRESSION=>‘SNAPPY‘}
建议采用 SNAPPY 压缩算法 , HBase 中,在 Snappy 发布之前( Google 2011 年对外发布 Snappy),采用的 LZO 算法,目标是达到尽可能快的压缩和解压速度,同时减少对 CPU 的消耗;
HBase修改压缩格式,需要一个列族一个列族的修改 alter ‘test‘, NAME => ‘f‘, COMPRESSION => ‘snappy‘。
而且这个地方要小心,别将列族名字写错,或者大小写错误。因为这个地方任何错误,都会创建一个新的列族,且压缩格式为snappy(修改之前需要先disable,修改完之后需要enable,然后 major_compact ‘test‘)
2、TTL (time to live)
设置方法和versions类似
3、disable_all enable_all drop_all:支持正则表达式,并列出当前匹配的表,之后给出确认提示。
4、Hbase 预分区
HBase表在刚刚被创建时,只有1个分区(region),当一个region过大(达到hbase.hregion.max.filesize属性中定义的阈值,默认10GB)时,表将会进行split,分裂为2个分区。表在进行split的时候,会耗费大量的资源,频繁的分区对HBase的性能有巨大的影响。HBase提供了预分区功能,即用户可以在创建表的时候对表按照一定的规则分区。分区是针对表级,不是列族级,因为region是根据rowkey来划分的。
目的:减少由于region split带来的资源消耗。从而提高HBase的性能。
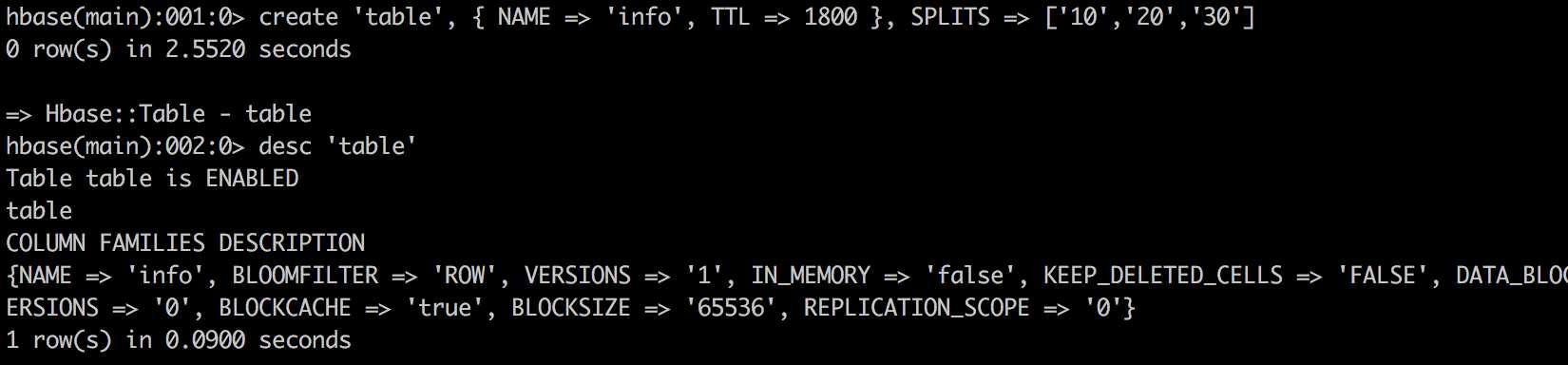
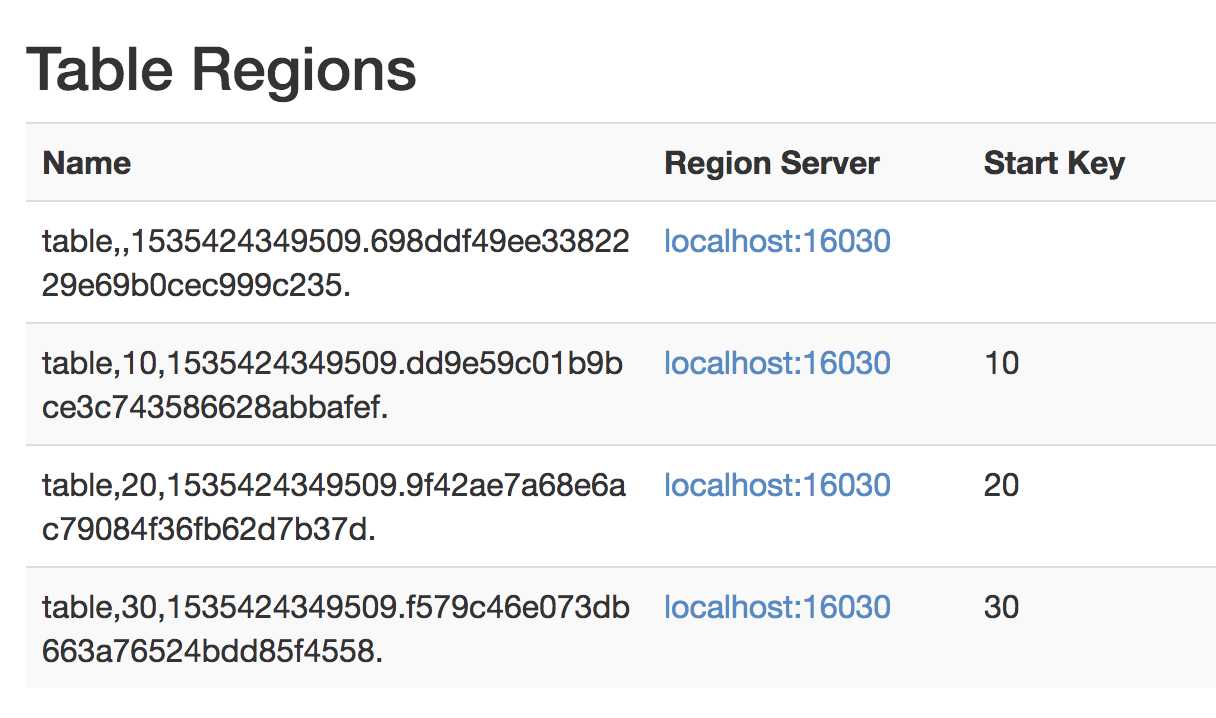
方案1:Hbase shell 创建,16010端口可以查看具体region
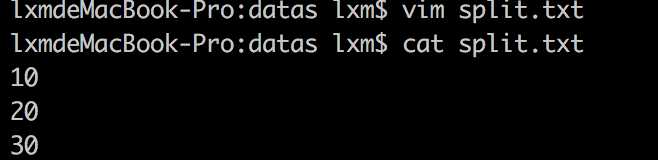
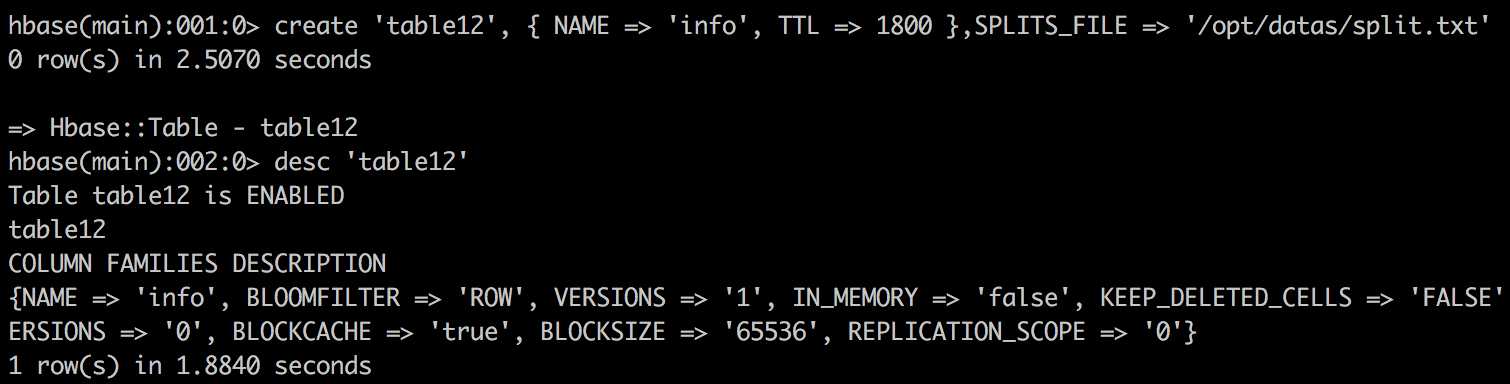
方案2:Hbase shell ,通过文件来创建
5、表的设计
列簇设计:
原则:在合理范围内能尽量少的减少列簇就尽量减少列簇,因为列簇是共享region的,每个列簇数据相差太大导致查询效率低下
最优:将所有相关性很强的 key-value 都放在同一个列簇下,这样既能做到查询效率 最高,也能保持尽可能少的访问不同的磁盘文件。以用户信息为例,可以将必须的基本信息存放在一个列族,而一些附加的额外信息可以放在 另一列族
rowkey设计:
长度原则:100字节以内,8的倍数最好,可能的情况下越短越好。因为HFile是按照keyvalue存储的,过长的rowkey会影响存储效率;其次,过长的rowkey在memstore中较大,影响缓冲效果,降低检索效率。最后,操作系统大多为64位,8的倍数,充分利用操作系统的最佳性能。
散列原则:高位散列,低位时间字段。避免热点问题
唯一原则:分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问 的数据放到一块。
6、数据热点问题
措施一:加盐
随机前缀,高位散列,讲数据随机分散到region上
措施二:哈希
哈希前缀,负债均衡,并且可以利用哈希重构rowkey,使用get获取准确数据
措施三:反转
反转固定长度或者数字格式的rowkey,牺牲了有序性,避免类似手机号固定开头的热点问题
措施四:时间戳反转
以上是关于Hbase 表设计和高级属性的主要内容,如果未能解决你的问题,请参考以下文章