互联网架构介绍 --from 光荣之路
Posted xiaxiaoxu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了互联网架构介绍 --from 光荣之路相关的知识,希望对你有一定的参考价值。
互联网架构介绍:
1 最初是前端一个web 加一个DB的结构
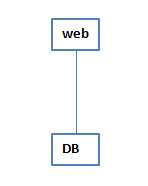
这种结构,web容易挂掉,业务就会终止,由于高可用的需求,出现了下面这样的架构、
2 加了一个web,两个web之间是主备的关系,一个挂了,另一个来代替,用来解决高可用问题
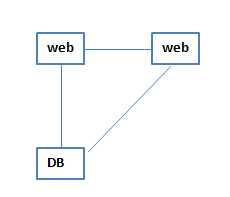
3 之后发现这样的架构访问量不够了,前端撑不住那么大的访问量,因为前端的访问量和DB的落库有大概是10比1的比例,前端访问10个,会有1个能够落库,所以随着访问量的增加,前端先扛不住了,这个时候主、备结构已经不能解决高可用的问题,所以在web前面加了一个ngx,作为负载均衡进行访问的转发,这个时候,web和web之间的主备关系就不存在了,在ngx进行转发的时候会有一个session保持的操作,再后来就出现无状态的概念,在两个web之间进行轮询,给谁都行
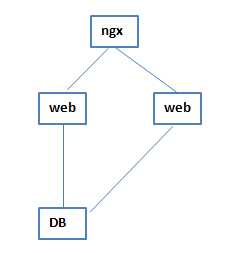
4当无状态的概念出来以后,web这一层就可以进行多次横向扩展,这是第一次质的飞越
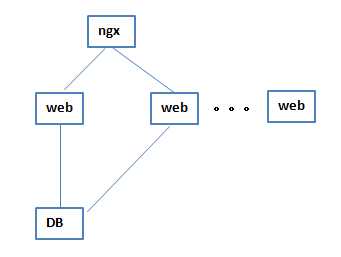
后来人们觉得一个ngx也会出问题,就设计了主、备结构的ngx,
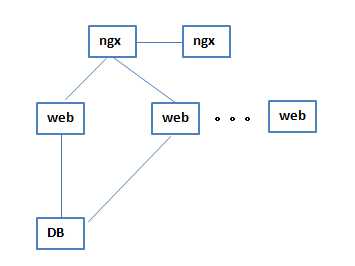
5 后来主、备ngx结构也不满足需求了,就再ngx前面加了一个lvs,lvs是一个负载均衡的结构,lvs先对ngx做分发
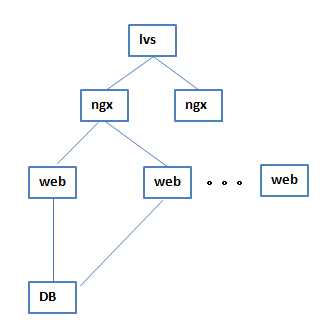
这时nginx就解放出来了,不是主、备结构了,而是作为一个层级的结构,可以进行无限横向扩展,lvs被设计成主、备的结构,至此,lvs作为第一层就不再变化了,第一层始终是主、备的结构,lvs的负载特别小,所有的负载到lvs直接就传给ngx,ngx再往下分发
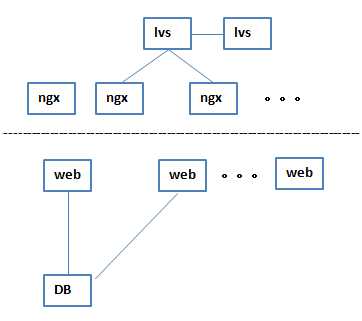
这个时候,转发层活了,web层活了,压力就全到DB了,DB就开始演变
6 最初DB演变出来master和slave这样的架构
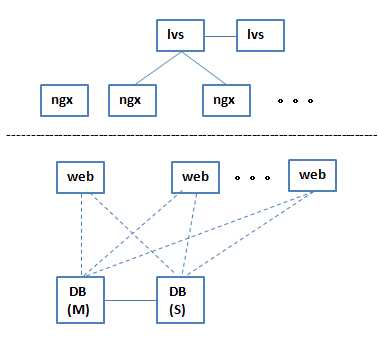
所有的web既连master也连slave,连slave只进行读操作,连master只进行写操作,这样把读和写进行分离,这时速度就有一个质的提升
然后如果一个slave不够的时候,再加一个slave,就解决了这个架构对数据库读的压力,这个时候的网站的并发访问量,理论上可以到万级了
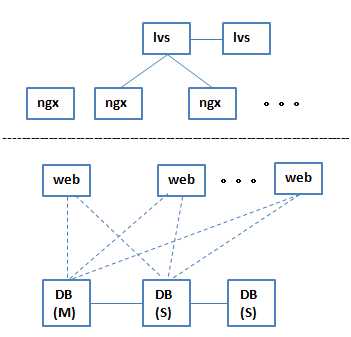
但是有一个问题,master是一个单点,如果它挂了,整个系统就都挂了,
这个时候要考虑的不只是吞吐量,也要看性能、可靠性,前端已经没有问题了,但是数据库这里有一个单点的问题,后来人们就开始想办法,怎么能保证DB不会出问题呢,后来人们把DB这块给重构了
7 在web下面加了一层proxy结构,可以说是转发,也可以说是中间件,这一层结构可以做成集群,这个集群是给数据库做切片的,做成类似于分布式的功能,这一层下来给DB做切片转发,这样DB这一层的库之间就不再有主、从的关系了,都认为是主,挂掉一个,其他的还能正常工作,既做高可用,又做高性能,保证某一台挂掉的时候,另外两台可以做到高可用,如果负载不勾的时候,还可以添加
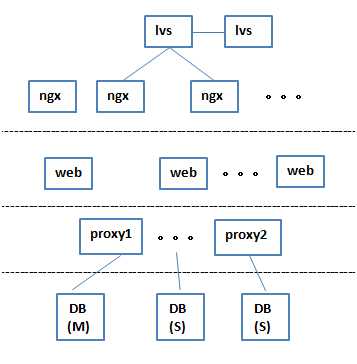
这个4层结构,可以在很高的性能下,很高的可靠性下做到万级深圳十万级的并发
这时5年前开始流行的架构,现在的使用率也很高,在对可靠性和性能方面要求不是很高的系统中可以很稳定的应用,但它存在一个问题,就是访问量再大的时候,落库的时候有一个瓶颈,因为DB不只是做插入和查询,还要做分析和关联,速度会很慢,那怎么办呢?
8 人们开始在DB层的上边加两个个缓存层(读和写),读缓存层是用redis,它也是集群,在业务层下边,DB层的上边,redis从数据库里抽数据,到自己的缓存中,然后提供给业务,只要被缓存命中的数据,读的是特别快的,redis把DB中的热数据提取到缓存层,直接给业务层来用。
写的话用的是MQ,来实现写的业务,一读一写合起来就大大的提升了并发的处理。
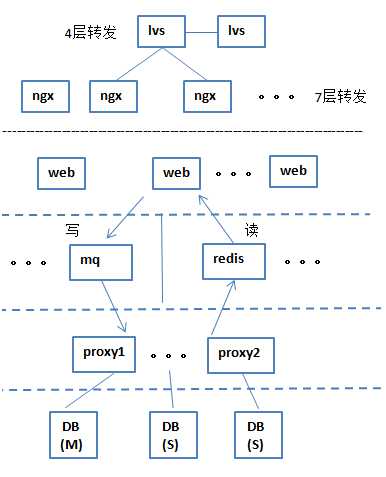
这个架构中的lvs负责四层转发,ngx做7层转发,转发下来后,web做接受,
读的时候,热数据从DB里抽到redis里读,就不会因为DB的计算卡着web了,在像双十一这种秒杀的业务,可以把数据提前放到redis里,供web来读,写数据时可以快速的写给mq,之后web就不用管了,用户就可以接着做下一步了,然后mq往DB里一点一点的落库,就是说通过缓存层把高速的web和低速的DB给隔离开,这样给前边的用户体验就会特别好,
比如双十一之前加购物车,都是提前被写好了放到redis里边,然后下订单都是通过mq来落库,你这边一点刷一下就过去了,你觉得过去了,实际上都在mq里往DB里处理,不可能一下子就落到DB里,目前还没有一家公司能过做到,就算是分布式数据库也不行,分布式数据库只能解决中型的业务场景,解决不了巨型的业务场景,这时很这两年很典型的比较火的架构,但是它比不上分布式数据库,这种结构即使很快,如果技术实力不够也只能达到十万级,如果要扩的话,只能是横向的扩,一套一套网上累加
9 出现了新型分布式数据库以后,这个架构变得很简单,很明晰,速度也很快
lvs,nginx,web这三层不变,下边的缓存层,代理层都没有了,只剩数据库本身了,
这个DB目前可以撑住10万甚至20万(瞬间的并发写),没有理论上限,各种的复杂的计算在一秒内都可以完成,这就是分布式架构的架构之美,越来越简洁
这个DB实际上是很复杂的
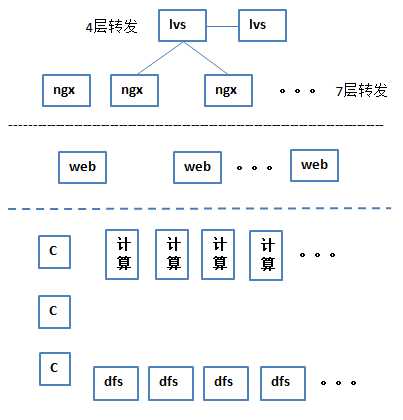
它的底层有自己的分布式存储dfs结构,另外有控制节点,还有提供实际计算,运行sql的计算节点,这三部分是没有中心(去中心),可扩展,对称的(坏掉一台、加一台都没问题),可以做到平行的扩展,做到无限制的可行性,也是分布式的目的所在。
他是怎么做到高速的呢?实际上就是分布式存储和计算的理念,如果有中心的话,需求下来一定是发给一个中心节点上,这个中心就会成为瓶颈,无中心的话,需求下来抛给控制节点,控制节点也没有中心,控制节点街道请求以后告诉它你取哪个计算节点上去,然后计算节点去计算的时候,如果这时所有的数据放到一个dfs上边(存储DB),读写势必会很慢,但是分布式存储它是完全散开的(多个dfs),一个请求过来后是放到所有的计算节点上去算的,然后拿的时候是到所有的dfs上去拿的,这个速度会特别快,这个过程完全都是分布的,所以,这种新型的数据库架构,就可以做到每秒10万个查询、写入、update,也可以做分析,最快可以到每秒10万
目前能做到千万级别的并发的,有BAT,12360,其他就没有了,这种j架构覆盖了当前互联网基本上%95 甚至是99%的需求
数据在下发的时候,是多副本,挂掉一个机器数据是不会丢失的,它的数据是打散的,这样读的才会快,这个结构出来之后直接干掉缓存层,而且可以支持列式数据库,目前的数据库基本是行式的,列式数据库对那种特别大的数据量支持的特别好
以上是关于互联网架构介绍 --from 光荣之路的主要内容,如果未能解决你的问题,请参考以下文章
物联网架构成长之路(33)-EMQ数据存储到influxDB