YOLO-V5轻松上手
Posted 老师我作业忘带了
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLO-V5轻松上手相关的知识,希望对你有一定的参考价值。
之前介绍了YOLO-V1~V4版本各做了哪些事以及相较于之前版本的改进。有的人或许会想“直接学习最近版本的算法不好吗”,在我看来,每一个年代的版本/算法都凝聚着当年学术界的智慧,即便是它被淘汰了也依旧有值得思考的地方,或是可以使我们对后续算法的改进/提出的缺点有更深的理解,进而“凝百家之长”真正开出道花结出道果有自己的感悟。
V4出现后,紧接着V5版本就出现了,相比于之前版本,V5出现时没有论文去介绍它怎么做的。V5像是把V4做了更好的实现,即思想算法上没有太大的变化,更像是一个“实际的偏工程的项目”。直到如今YOLO-V5也十分经典。
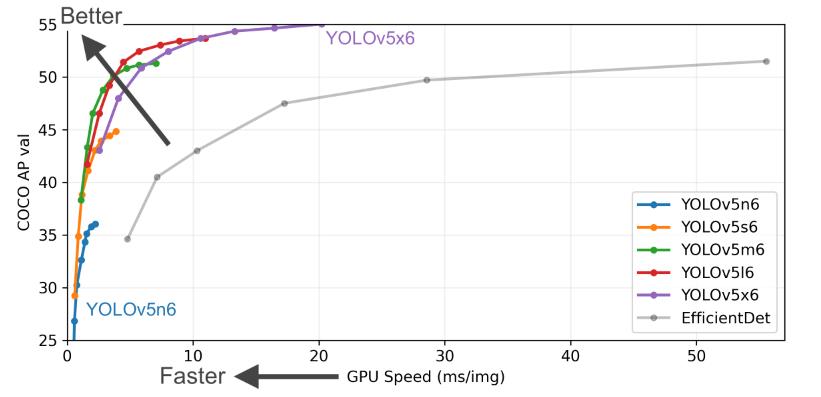
本文与前几篇主讲算法不同,本文教大家如何下载和使用YOLO-V5。
有时间的话我会从其源码的角度进行一遍梳理(或许吧不懒的话)。
前面也说过了具体算法和流程与V4无太大区别,主要是更好的实现。
一、YOLO-V5下载
ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite (github.com)
点击上方链接直接下载即可,下载完成后解压,打开Pycharm新建一个目录,
下载requirements里面的依赖
pip install -r requirements.txt值得一提的是YOLO-V5要配合python>=3.7,pytorch>=1.7的版本使用,会用到里面的优化算法,所以大家自行选择一个更高的版本吧。
比如我这里直接选择anaconda里之前下载的torch1.10。
二、下载、配置数据集和下载预训练模型
2.1 下载数据集
他这里用的是COCO数据集,这玩意比较大我们也没必要下载了,下载个小的玩一玩
可以去这里:Computer Vision Datasets (roboflow.com),下载物体检测相关的数据集,样式比较丰富,如检测汽车的、象棋的、动物的、人脸的等等。
以口罩数据集为例,大家也可以下载自己喜欢的,点击Mask Wearing Dataset,进去下载就行了。
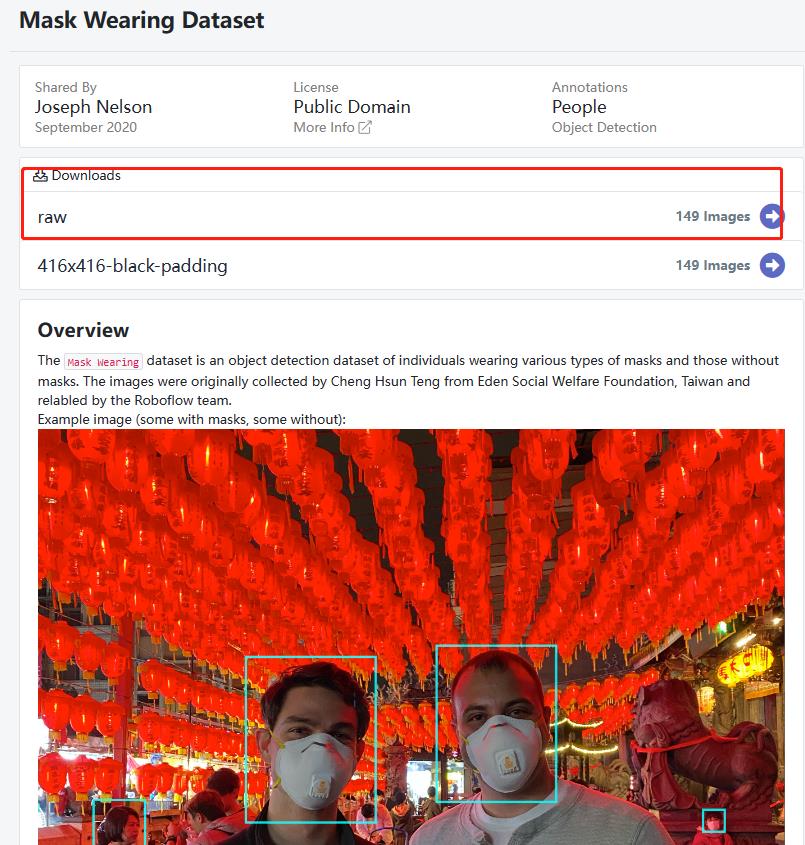
下载时会提示你选择格式:
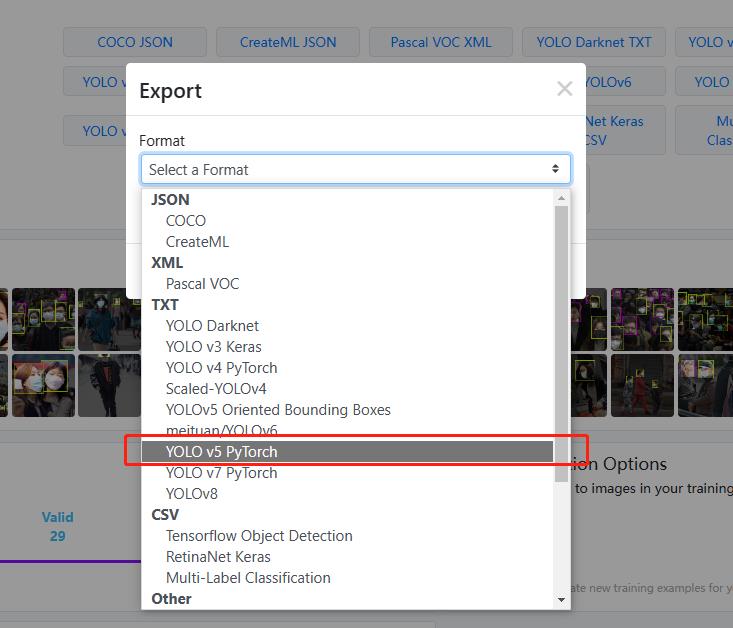
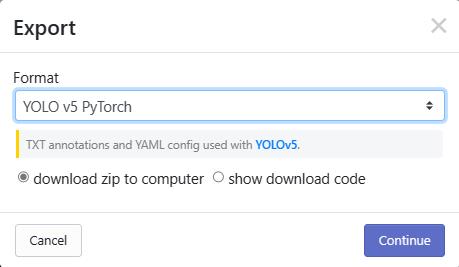
下载完成后和V5放在同一级目录就行
以train里的文件为例:
images则是训练所需的图片
labels里则是对应名字图片的标签值,如下1表示没戴口罩,戴了就是0,剩下四个则是"框的坐标"。
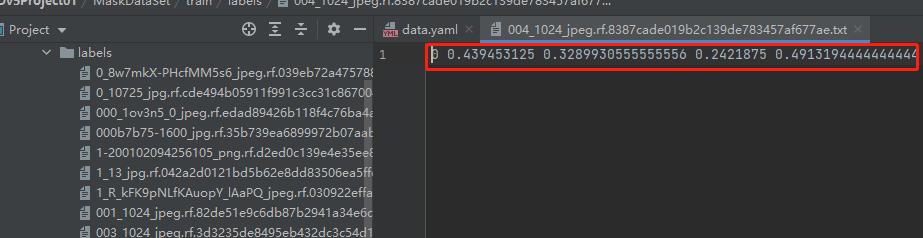
当然有的有很多行,毕竟一张图片里可能有很多人。找的越全recall越高,越精准accuracy越高,整体mAP越高。
后续第一次去读数据的时候还会自动生成labels.cache缓存文件,方便后续读取。
2.2 配置数据集
点开data.yaml,可以看到train和val的相对路径,到时候YOLO代码会直接读取,自己记得确认一下路径是否正确,路径问题比较基础这里就不讲了。
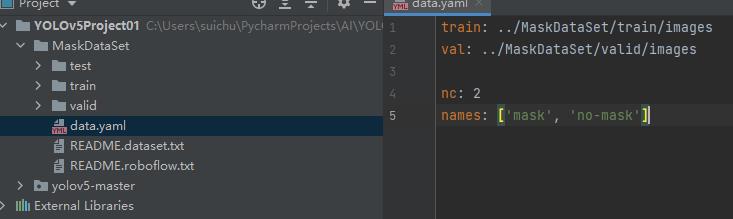
如果要做test就把test路径写进去就行。
nc指类别的个数,戴口罩和不带口罩,['mask', 'no-mask']
2.3 下载预训练模型
咱们简单下载个5s就行了,https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt
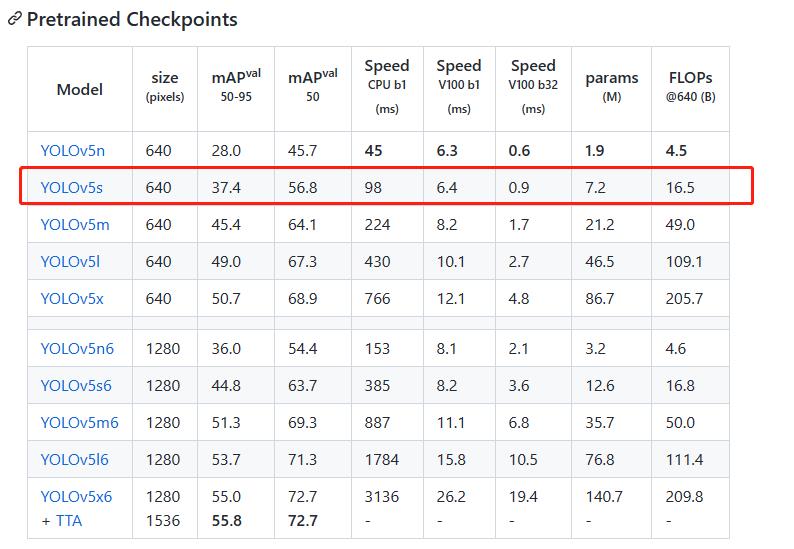
下载完成后放到yolov5-master文件夹里。
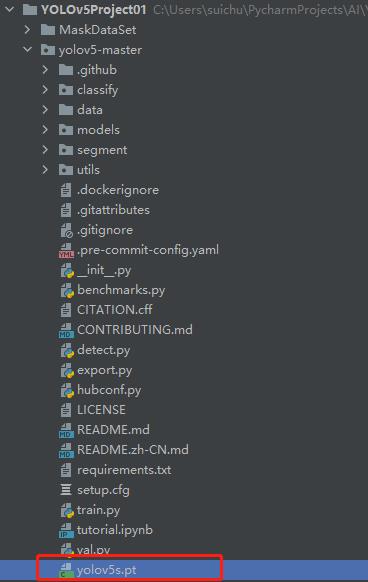
三、配置demo参数
参考这里:
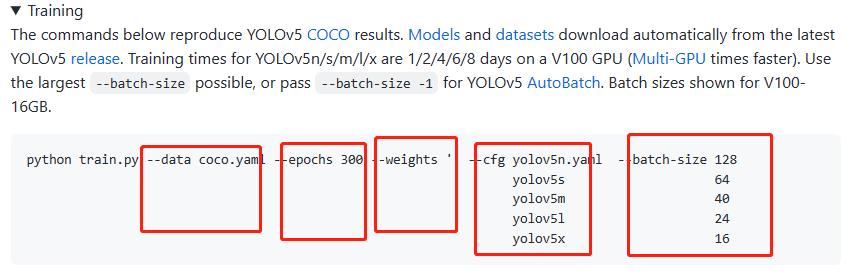
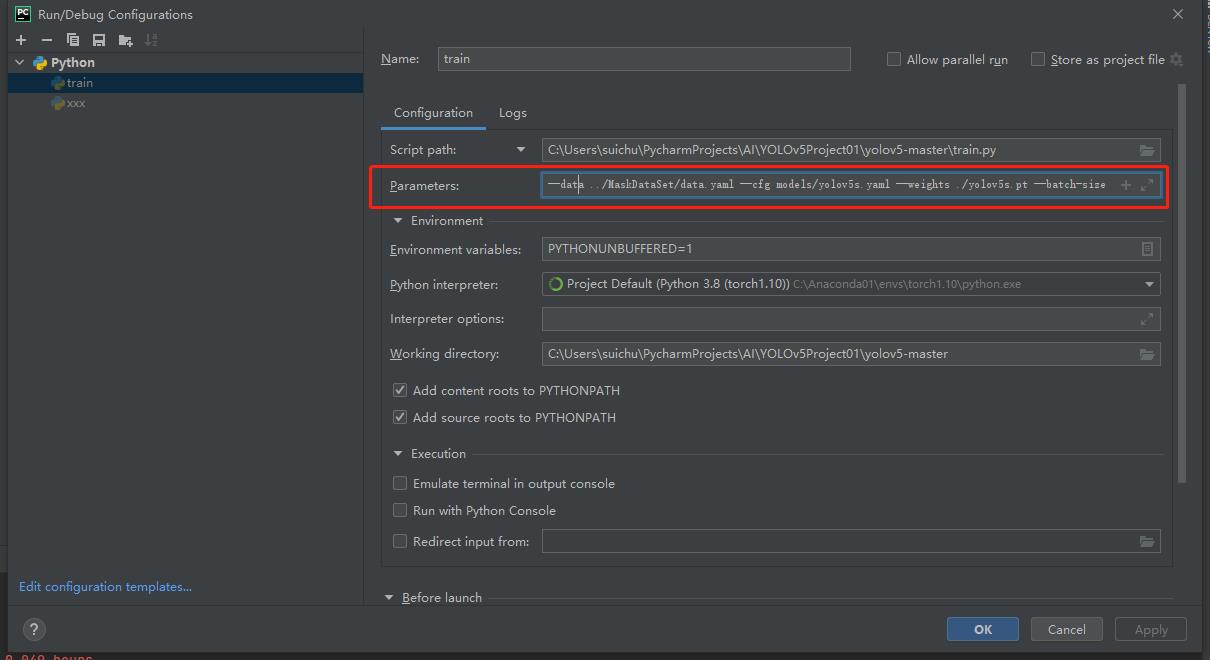
--data ../MaskDataSet/data.yaml
--cfg models/yolov5s.yaml
--weigths ./yolov5s.pt
--batch-size 24
我们之前下载了预训练模型yolov5s.pt,用的话就加上,不用就--weights ''
当然还有一些参数可选,源码里有默认值,我们先用这些。
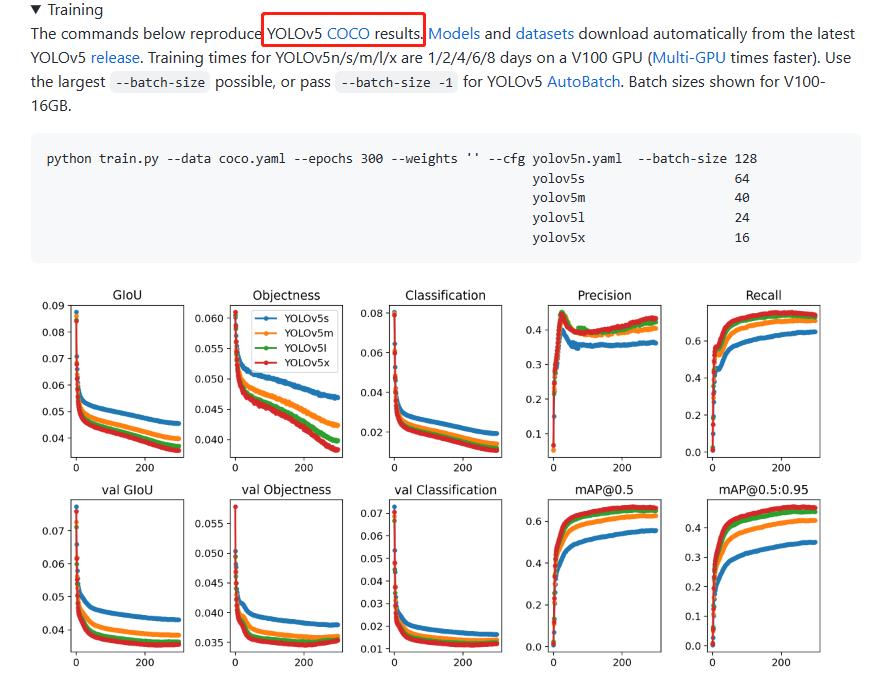
四、训练
做好上面那些后,在yolov5-master的train.py里直接run就行了。
刚开始可能报错,我看是他第一次执行,会去github上下载标记字体,然后没连接进去。
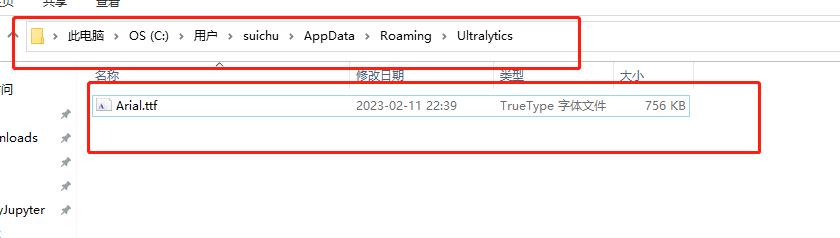
解决办法就是自己点进去那个报错下载的连接自己下载就行了,下载完放到上面那个文件夹里。
之后再进行run,它默认会跑100个epoch,也可以自己设置。
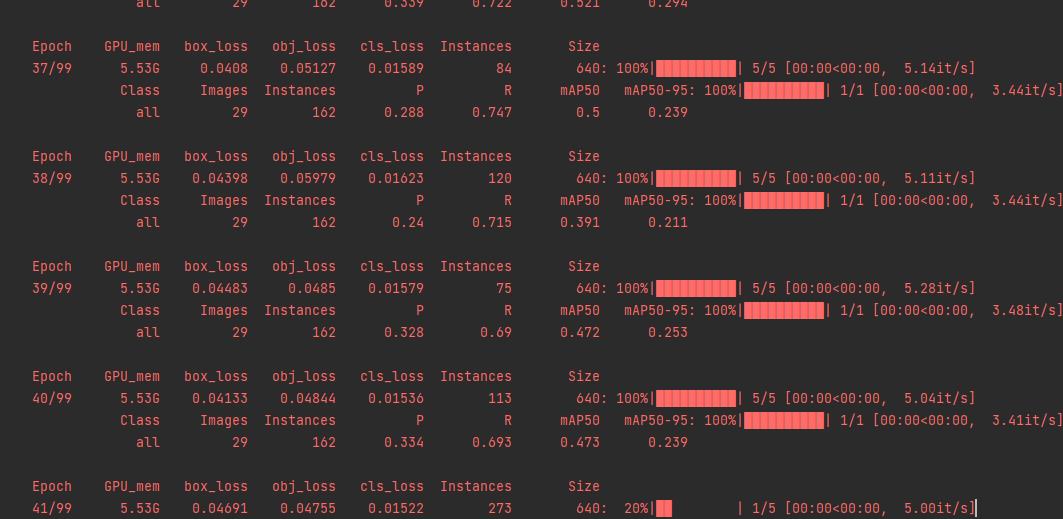
这里就训练完了
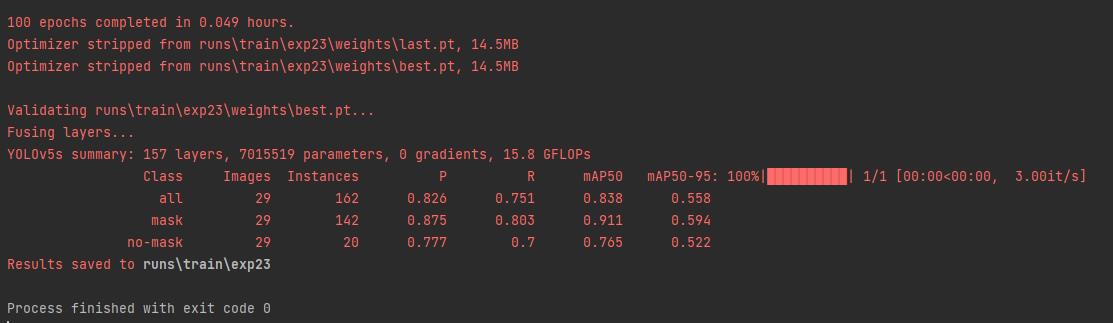
上图告诉你 结果在runs\\train\\exp23那里,即最后最新跑的一次。
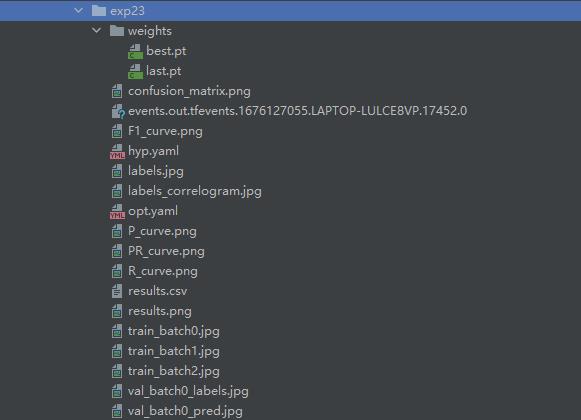
可见生成了权重文件和一些图片。
results.csv里面是一些标注和统计数据,至于生成的图片这里简单展示几个:
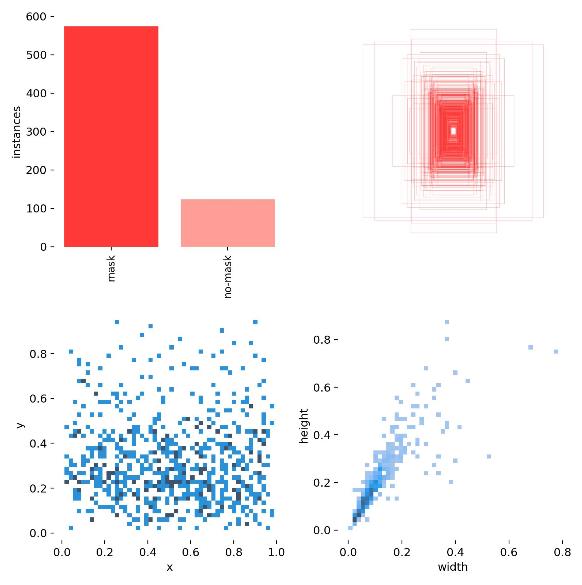
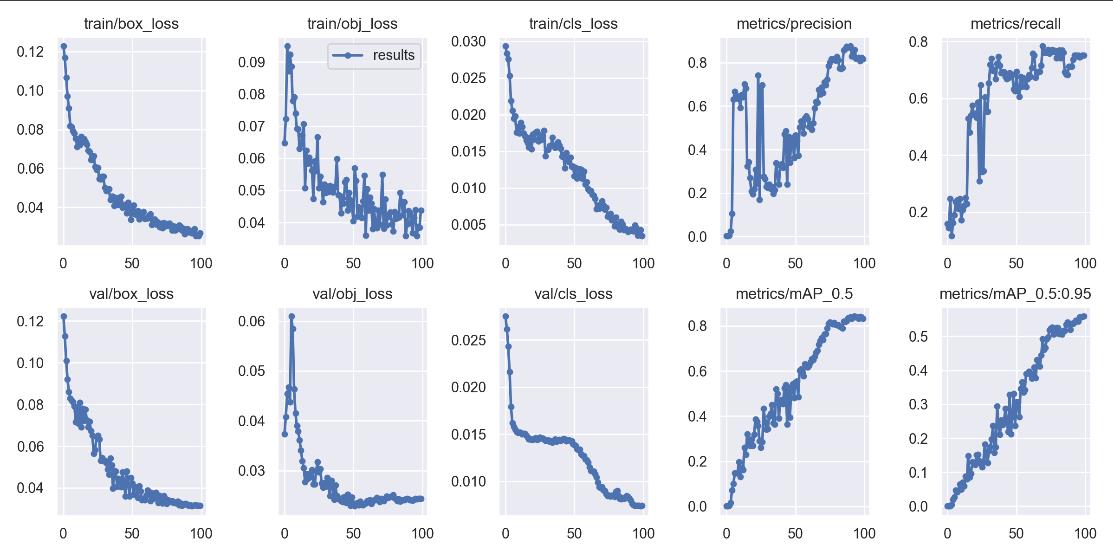
五、检测
进入detect.py 直接右键run的话,由于下载的yolov5-master的时候它自带测试图片和权重文件,也填写了默认路径,所以不会报错;
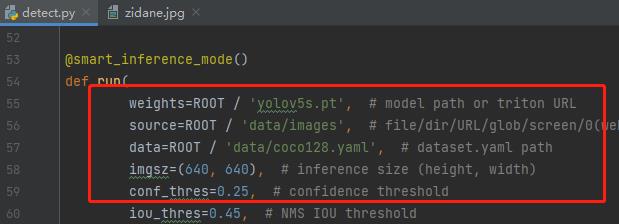
直接跑的话你会看到结果里:
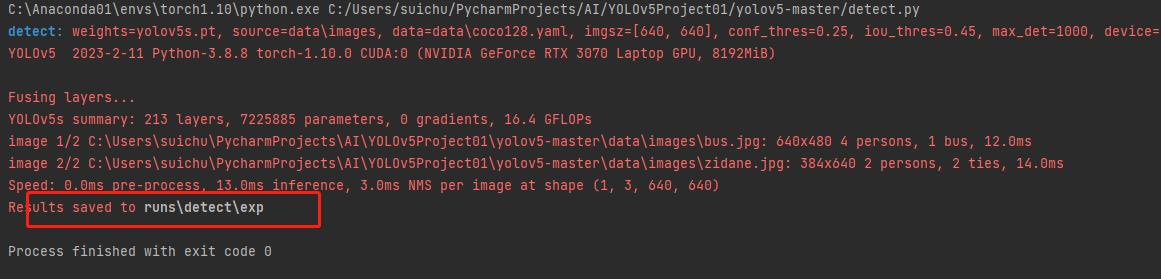
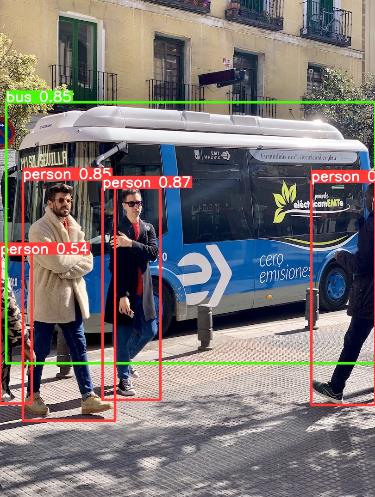

这和我们刚刚train那步没有一点关系,都是它自带的一开始不用训练就能玩的。
我们活学活用,刚刚训练的是是否戴口罩,所以我们不妨也自己改一下参数:
其中 -- source 后可以是图片 视频 文件夹 路径url等
我这里让它测试有没有戴口罩,就用上面这两张图片的路径吧即不修改source了;
不过我在里面又加了两张图片
修改参数:
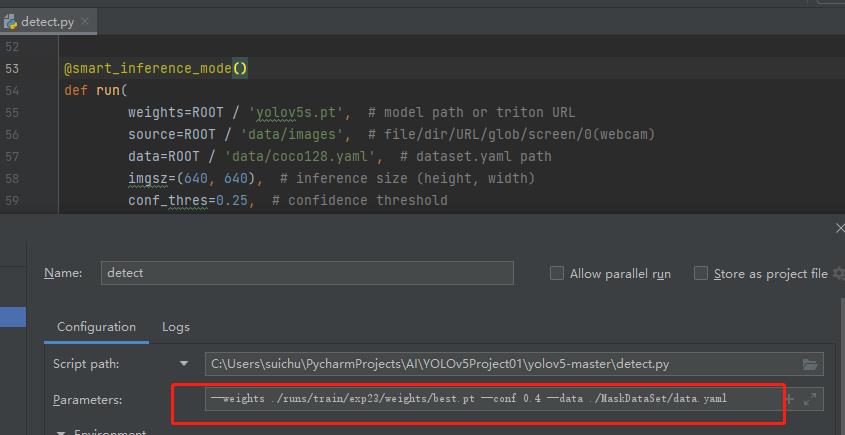
--weights ./runs/train/exp23/weights/best.pt
--conf 0.4
--data ./MaskDataSet/data.yaml
这里我修改了权重文件 毕竟之前用的是自带的yolov5s.pt,而这个best.pt是我们通过自己下载的预训练模型yolov5s.pt的基础上训练出来的用于检测是否带口罩了的权重文件。 conf是置信度,想改就改。
run完后发现实际效果还行,但黑人那里不行


不过毕竟我们训练的数据就100多张,里面我看了也没有黑人,情有可原,它可能在面部颜色差异上占比很大。
我又找了几张试了试 发现就是数据的问题


不过问题不大,我们本次的目的就是先学会简单使用他们的代码。
可以把source那里换成视频玩一玩试一试。
六、题外话
希望本篇文章能够对你有所帮助,如果你是连GPU版本的torch都还没下载过的小白建议一步步来。
大家也可以换点别的数据集、参数来自己跑一跑玩一玩,同时感兴趣的小伙伴也可以开始在了解其算法的情况下简单读读源码了,我下一期或许会写一篇V5的源码引导文章。
以上是关于YOLO-V5轻松上手的主要内容,如果未能解决你的问题,请参考以下文章