HDFS设计思想
Posted qwangxiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS设计思想相关的知识,希望对你有一定的参考价值。
HDFS设计思想
DataNode:用来在磁盘上存储数据
HDFS 数据存储单元( block )
1 文件被切分成固定大小的数据block块
?默认数据块大小为 64MB(hadoop1.x版本64M,2.x为128M) ,可配置
?若文件大小不到 64MB ,则单独存成一个block
比如:一个120M的文件会分成64M+56M两个block块,虽然第二个分割不到64M,依然作为单独的block。
2 一个文件存储方式
?上传时按文件大小被切分成若干个 block ,存储到不同节点上。每一个block都有唯一的编号。
?默认情况下每个 block 都有三个副本,存储到三个不同的节点上,这三个副本是同级的,比如第一次访问和第二次访问可能因为副本所在节点的资源空闲而被访问,因此副本和备份作用不同。比如某个文件被分成了三个block,block1+block2+block3,而对于每个block都有三个副本,如三个block1副本分别存储server1、server2、server3三个节点上。如果集群中DataNode节点数量不够三个,存储就会报错。也就是DataNode节点的数量不小于block数量。
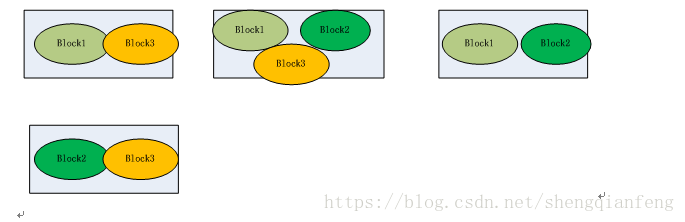
Block 大小和副本数通过 Client 端上传文件时设置,文件已经上传服务器成功后,文件block的副本数可以变更,比如文件被append追加修改(因为文件修改仅仅支持追加)生成新的block。Block Size 不可变更,所以虽然block数量增加了,但是block数据块64M大小依然不变。
NameNode:保存metadate元数据,接受客户端读写。
1 NameNode保存metadata元数据,包括:
? 文件 owership(属组和属主)和 permissions(权限)
? 文件包含哪些block块及这些block块ID
? Block 保存在哪个DataNode (由 DataNode 启动时上报),即block块的位置信息。
2 metadate 元数据会在启动时从磁盘加载到内存
也就是说启动后,内存和磁盘中都有一份metadata元数据信息。
? metadata 存储到磁盘文件名为”fsimage” ,在NameNode启动时加载到内存,
而DataNode启动时会上报block的位置信息给NameNode,然后NameNode把block的位置信息保存到内存中。也就是说磁盘上的fsimage文件中此时就少了block的位置信息了。
? Block 的位置信息不会保存到fsimage
? edits 记录对 metadata 的操作日志
那么,metadata元数据的操作日志是什么情况下产生的呢?
答:比如上传新文件时,元数据进行内存操作之后记录edits日志,记录了元数据信息。
那么问题来了:
1为什么比如上传文件时,对元数据内存操作后,要记录edits日志,而不直接操作fsimage日志呢?
因为对于大数据系统来说,大量的文件上传时会操作内存中的元数据,然后如果直接操作fsimage元数据文件,就会造成IO瞬间爆发,造成阻塞。所以记录的只是操作记录edits日志。
2 随着时间增加,fsimage文件并没有跟内存元数据保持同步,而落后了很多。怎么办?
SecondaryNameNode的作用就提现出来。
SecondaryNameNode:不是主也不是从节点。主要用来辅助NameNode完成fsimage文件的同步的更新的,这个过程叫做合并edits日志。因为同步更新时根据edits日志来更新的,也就是fsimage日志和edits日志的合并。
1 SNN 执行合并时机
? 根据配置文件设置的时间间隔fs.checkpoint.period 默认 3600 秒
? 根据配置文件设置edits log 大小 fs.checkpoint.size 规定 edits 文件的最大值默
认是 64MB

2 SNN合并流程
? 首先,NameNode生成一个新的edits日志文件为元数据操作做准备。
? 接着,SecondrayNameNode从NameNode读取edits和fsimage文件到自己节点。
? 进行合并,生成一个新的fsimage文件。
? SecondrayNameNode把新fsimage文件传输给NameNode,NameNode更新fsimage。
? 当下一个合并时机到来时依次类推。
DataNode ( DN )
– 存储数据( Block )
–启动 DN 线程的时候会向 NN 汇报 block 信息
–通过向 NN 发送心跳保持与其联系( 3 秒一次),如果 NN 10 分钟没有收
到 DN 的心跳,则认为其已经 lost ,并 copy 其上的 block 到其它 DN。
问题:dataNode已经挂掉了,是怎么保持block副本为3个呢?
答:NameNode其实会进行checkSize检查每个block的副本数,如果不足则进行复制,所以也不需要知道挂掉的那个节点任何信息。如果复制时发现DataNode节点数小于配置副本数,报错!
Block 的副本放置策略
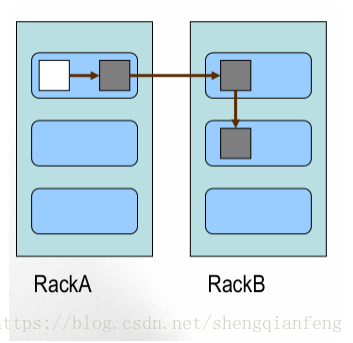
–第一个副本:放置在上传文件的 DataNode ;
如果是集群外提交,则随机挑选一台,磁盘不太满, CPU 不太忙的节点。
–第二个副本:放置在于第一个副本不同的机架的节点上。
–第三个副本:与第二个副本相同机架的节点。
–更多副本:随机节点
HDFS写流程:
其实就是上传为件,通过hdfs API.
1 客户端请求NameNode,传递参数文件大小、文件名、文件“客户端”用户
2 NameNode收到文件后,比如1G,NameNode服务端配置的有默认block大小,在客户端没有指定block大小时使用。会返回告诉客户端block大小、空闲DataNode机器(DataNode跟NameNode保持三秒一次的心跳)
3 客户端通过输出流,把数据按照字节流方式写到DataNode上去,边写边切成block,就是写够64M后就生成了第一个block,然后继续写第二个block到当前DataNode或者其他的DataNode上。写完后,文件就上传成功了。
注意:副本和客户端无关,当第一个block写完后就会复制副本给其他的DataNode节点。
HDFS读流程:
1 客户端请求NameNode,NameNode接收到文件路径,返回此文件的元数据(文件哪些block及编号、block位置信息)给客户端。
2 客户端通过字节输入流到DataNode上读取依次block。每个block有是3个以上副本,到哪里读?会找到副本所在dataNode空闲的节点读取。
3 读取完成,告诉NameNode汇报。
搭建HDFS集群环境:
准备:
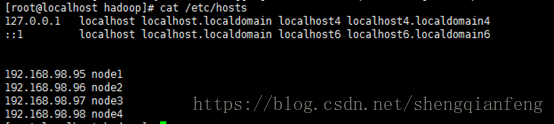
1 准备机器192.168.98.95(node1)、192.168.98.96(node2)、192.168.98.97(node3)、192.168.98.98(node4)四台机器
2 各节点时间相同,差几秒没事
3 设置免登录、检查jdk1.7
配置Hosts:
scp –p /etc/hosts [email protected]:/etc
设置免登录:
#这个命令会产生一个公钥(~/.ssh/id_rsa.pub)和密钥(~/.ssh/id_rsa)
ssh-keygen -t dsa -P ‘‘ -f ~/.ssh/id_dsa
# 将自己的公钥导入认证文件中,就直接可以ssh本机ip,进行登陆,不需要输入密码
cat ~/pub_key >> ~/.ssh/authorized_keys
所以,将其他机器的pub_key导入到本机认证文件中就可以实现免登录。
比如使用192.168.98.95(node1)访问192.168.98.96(node2),免登录:
-
# ssh-keygen -t dsa -P ‘‘ -f ~/.ssh/id_dsa
-
-
#scp -p ~/.ssh/id_dsa.pub root@node2:/opt
复制到了192.168.98.96(node2),然后在192.168.98.96(node2)执行以下命令:
-
#cat /opt/id_dsa.pub >> ~/.ssh/authorized_keys
-
-
Ok!
-
#cd /root/hadoop-2.5.1/etc/hadoop
-
-
# vi hadoop-env.sh
修改JAVA_HOME
-
#vi core-site.xml
-
-
<property>
-
-
<name>fs.defaultFS</name>
-
-
<value>hdfs://node1:9000</value>
-
-
</property>
-
-
-
<property>
-
-
<name>hadoop.tmp.dir</name>
-
-
<value>/opt/hadoop-2.5</value>
-
-
</property>
#vi hdfs-site.xml
-
-
<property>
-
-
<name>dfs.www.trgj888.com namenode.secondary.http-address</name>
-
-
<value>hdfs://www.thq666.com/ node2:50090</value>
-
-
</property>
-
-
<property>
-
-
<name>dfs.namenode.secondary.https-address</name>
-
-
<value>hdfs://www.yigou521.com/ node2:50091</value>
-
-
</property>
-
-
<property>
-
-
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
-
-
<value>false<www.yongshiyule178.com /value>
-
-
</property>
#vi slavers
-
node2
-
-
node3
-
-
node4
#vi master
node2
加入hadoop环境变量到/etc/profile

#hdfs namenode -format --只能在namenode下敲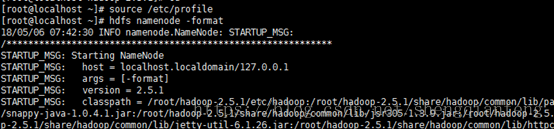
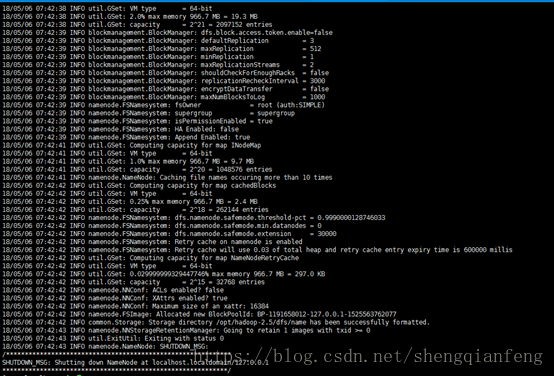
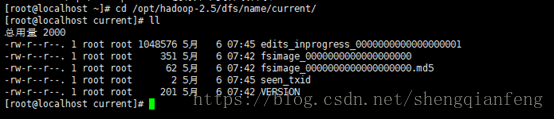
帮我们创建了/opt/hadoop-2.5/dfs/name/current
及其下的fsimage文件
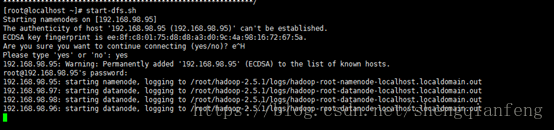
启动hadoop
#start-dfs.sh
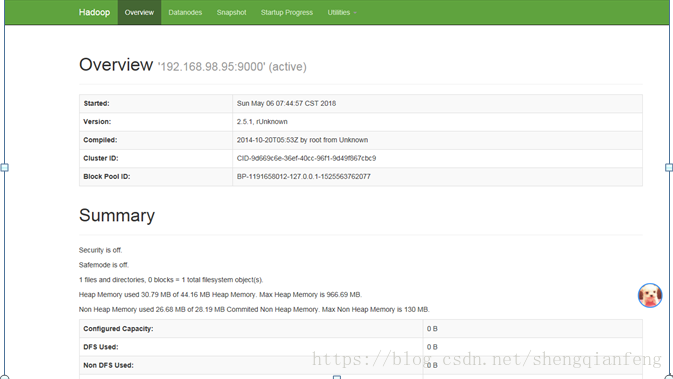
关闭防火墙
#systemctl stop www.taohuayuan178.com/ firewalld.servicehttp://192.168.98.95:50070/
http://192.168.98.96:50090

问题:不知什么情况datanode只有node4,没有node2和node3呢?-www.tygj178.com-namdeNode和dataNode的clusterID不一致!
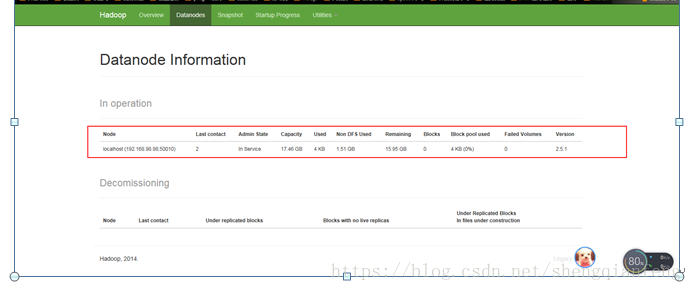
Hadoop日志也没有看出错误:/root/hadoop-2.5.1/logs
tail -fhadoop-root-namenode-localhost.localdomain.log
以上是关于HDFS设计思想的主要内容,如果未能解决你的问题,请参考以下文章