分类预测,交叉验证调超参数
Posted caiyishuai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分类预测,交叉验证调超参数相关的知识,希望对你有一定的参考价值。
调参数是一件很头疼的事情,今天学习到一个较为简便的跑循环交叉验证的方法,虽然不是最好的,如今网上有很多调参的技巧,目前觉得实现简单的,以后了解更多了再更新。
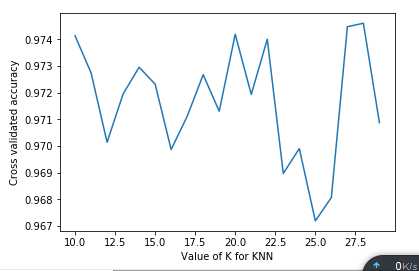
import numpy as np from pandas import read_csv import pandas as pd import sys import importlib from sklearn.neighbors import KNeighborsClassifier from sklearn.ensemble import GradientBoostingClassifier from sklearn import svm from sklearn import cross_validation from sklearn.metrics import hamming_loss from sklearn import metrics importlib.reload(sys) from sklearn.linear_model import LogisticRegression from imblearn.combine import SMOTEENN from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier #92% from sklearn import tree from xgboost.sklearn import XGBClassifier from sklearn.linear_model import SGDClassifier from sklearn import neighbors from sklearn.naive_bayes import BernoulliNB import matplotlib as mpl import matplotlib.pyplot as plt from sklearn.metrics import confusion_matrix from numpy import mat from sklearn.cross_validation import cross_val_score ‘‘‘分类0-1‘‘‘ root1="D:/ProgramData/station3/get_10.csv" root2="D:/ProgramData/station3/get_more.csv" root3="D:/ProgramData/station3/get_more9_10.csv"#现已删除 data1 = read_csv(root3) #数据转化为数组 #print(data1) data1=data1.values #print(root3) ‘‘‘设置调参的参数范围‘‘‘ k_range = range(10,30) k_scores = [] for k in k_range: print(k) clf = XGBClassifier(learning_rate= 0.28, min_child_weight=0.7, max_depth=21, gamma=0.2, n_estimators = k ,seed=1000) X_Train = data1[:,:-1] Y_Train = data1[:,-1] X, y = SMOTEENN().fit_sample(X_Train, Y_Train) ‘‘‘交叉验证,循环跑,cv是每次循的次数‘‘‘ scores = cross_val_score(clf, X, y, cv=10, scoring=‘accuracy‘) ‘‘‘得到平均值‘‘‘ k_scores.append(scores.mean()) print(k_scores) ‘‘‘画出图像‘‘‘ plt.plot(k_range, k_scores) plt.xlabel("Value of K for KNN") plt.ylabel("Cross validated accuracy") plt.show()
输出:
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
[0.97412964956075354, 0.9727391061798798, 0.97013721043132806, 0.97194859003086298, 0.97294995933403183, 0.97231558127609719, 0.96986246148807409, 0.97110881317341868, 0.97266934815981898, 0.97129916102078995, 0.97418346359522834, 0.97193130399012762, 0.97399918501338656, 0.96896580483736439, 0.9699006181068961, 0.96718751547141646, 0.96806405658951156, 0.97446711004726705, 0.97459883656499302, 0.97087357015888409]
?
以上是关于分类预测,交叉验证调超参数的主要内容,如果未能解决你的问题,请参考以下文章