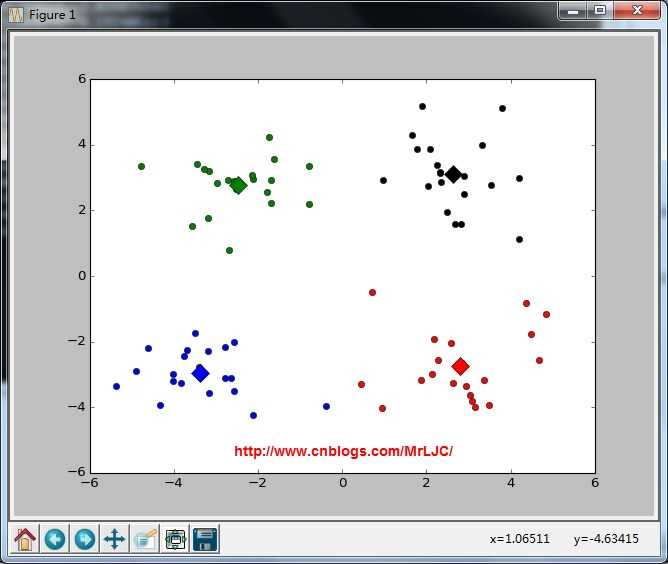
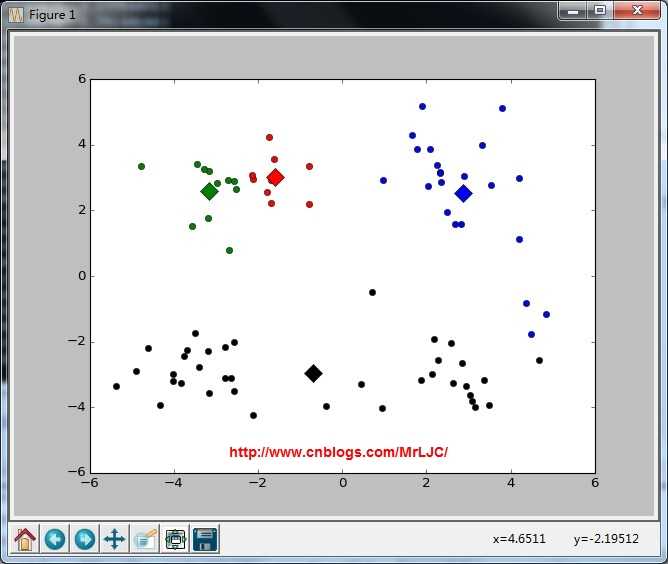
K-means聚类算法
算法优缺点:
优点:容易实现
缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢
使用数据类型:数值型数据
算法思想
k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去。
1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好。另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚类你可能就会考虑分成三类(L,M,S)等
2.然后我们需要选择最初的聚类点(或者叫质心),这里的选择一般是随机选择的,代码中的是在数据范围内随机选择,另一种是随机选择数据中的点。这些点的选择会很大程度上影响到最终的结果,也就是说运气不好的话就到局部最小值去了。这里有两种处理方法,一种是多次取均值,另一种则是后面的改进算法(bisecting K-means)
3.终于我们开始进入正题了,接下来我们会把数据集中所有的点都计算下与这些质心的距离,把它们分到离它们质心最近的那一类中去。完成后我们则需要将每个簇算出平均值,用这个点作为新的质心。反复重复这两步,直到收敛我们就得到了最终的结果。
函数
loadDataSet(fileName)
从文件中读取数据集distEclud(vecA, vecB)
计算距离,这里用的是欧氏距离,当然其他合理的距离都是可以的randCent(dataSet, k)
随机生成初始的质心,这里是虽具选取数据范围内的点kMeans(dataSet, k, distMeas=distEclud, createCent=randCent)
kmeans算法,输入数据和k值。后面两个事可选的距离计算方式和初始质心的选择方式show(dataSet, k, centroids, clusterAssment)
可视化结果
-

1 #coding=utf-8 2 from numpy import * 3 4 def loadDataSet(fileName): 5 dataMat = [] 6 fr = open(fileName) 7 for line in fr.readlines(): 8 curLine = line.strip().split(‘ ‘) 9 fltLine = map(float, curLine) 10 dataMat.append(fltLine) 11 return dataMat 12 13 #计算两个向量的距离,用的是欧几里得距离 14 def distEclud(vecA, vecB): 15 return sqrt(sum(power(vecA - vecB, 2))) 16 17 #随机生成初始的质心(ng的课说的初始方式是随机选K个点) 18 def randCent(dataSet, k): 19 n = shape(dataSet)[1] 20 centroids = mat(zeros((k,n))) 21 for j in range(n): 22 minJ = min(dataSet[:,j]) 23 rangeJ = float(max(array(dataSet)[:,j]) - minJ) 24 centroids[:,j] = minJ + rangeJ * random.rand(k,1) 25 return centroids 26 27 def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent): 28 m = shape(dataSet)[0] 29 clusterAssment = mat(zeros((m,2)))#create mat to assign data points 30 #to a centroid, also holds SE of each point 31 centroids = createCent(dataSet, k) 32 clusterChanged = True 33 while clusterChanged: 34 clusterChanged = False 35 for i in range(m):#for each data point assign it to the closest centroid 36 minDist = inf 37 minIndex = -1 38 for j in range(k): 39 distJI = distMeas(centroids[j,:],dataSet[i,:]) 40 if distJI < minDist: 41 minDist = distJI; minIndex = j 42 if clusterAssment[i,0] != minIndex: 43 clusterChanged = True 44 clusterAssment[i,:] = minIndex,minDist**2 45 print centroids 46 for cent in range(k):#recalculate centroids 47 ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]#get all the point in this cluster 48 centroids[cent,:] = mean(ptsInClust, axis=0) #assign centroid to mean 49 return centroids, clusterAssment 50 51 def show(dataSet, k, centroids, clusterAssment): 52 from matplotlib import pyplot as plt 53 numSamples, dim = dataSet.shape 54 mark = [‘or‘, ‘ob‘, ‘og‘, ‘ok‘, ‘^r‘, ‘+r‘, ‘sr‘, ‘dr‘, ‘<r‘, ‘pr‘] 55 for i in xrange(numSamples): 56 markIndex = int(clusterAssment[i, 0]) 57 plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex]) 58 mark = [‘Dr‘, ‘Db‘, ‘Dg‘, ‘Dk‘, ‘^b‘, ‘+b‘, ‘sb‘, ‘db‘, ‘<b‘, ‘pb‘] 59 for i in range(k): 60 plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize = 12) 61 plt.show() 62 63 def main(): 64 dataMat = mat(loadDataSet(‘testSet.txt‘)) 65 myCentroids, clustAssing= kMeans(dataMat,4) 66 print myCentroids 67 show(dataMat, 4, myCentroids, clustAssing) 68 69 70 if __name__ == ‘__main__‘: 71 main()