1.1 DAL数据访问层
Posted lijiejoy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了1.1 DAL数据访问层相关的知识,希望对你有一定的参考价值。
分布式(Distributed)数据访问层(Data Access Layer),简称DAL,是利用mysql Proxy、Memcached、集群等技术优点而构建的一个架构系统。主要目的是解决高并发、大数据流操作遇到的和数据访问有关的问题,例如怎么进行切库分表,怎样能够更好的防止服务单点故障等等。
分布式数据访问层的诞生
是由手机之家一位资深的开发者和架构师许超先最先提出的。
2007年,手机之家的用户已经接近1000万、PV也到了500万以上,正处于中小型网站向大型网站的过渡时期。那时候,我们明显感觉到我们在技术上已经遇上了瓶颈,一个是系统负载过高,经常要担心我们的数据库是不是又挂了,进而造成整个系统的瘫痪。第二个是5年积累下来的代码也已经非常难以维护,因为分层模糊,结果到处充满着数据库访问逻辑、到处充满着缓存读写逻辑,再加上表的设计不合理,造成无法简单地进行水平伸缩。总之我们的系统已经到了不得不进行改造的地步了。 后来,老高(手机之家创始人高春辉)组了一个研发团队,旨在从根本上解决上述提到的问题。在此后一年的时间里,我们走了很多弯路,经历了很多痛苦,不过,也正是在这段时间里产生了DAL的雏形,经过若干次改进变成了后来的DAL1.0。DAL的产生完全是形势使然。 DAL1.0上线后数据库的QPS明显下降从几千降到几百。事实证明,我们找到了一条行得通的路子。所以才有DAL的后续版本的开发,才有今天的DAL2.x版本的产生……
分布式数据库访问层的特点
1、可伸缩
这里指水平可伸缩。事实上,这点更应该是整个系统要考虑的目标了,而非DAL,DAL要考虑的是怎么更好地支持。举例说,我们可以一个库一个服务,甚至可以是一个表一个服务,库、表拆分后,DAL应能路由查询、合并结果,而不是让应用程序去操心这些事。
2、高可用性
(1) .我们认为出错失败是很正常的,一台机器倒下了,其它机器应继续保持系统正常运作。容错是很重要的一个要求。
(2) 系统规模大了以后,很容易出现“异构”的情况,如原有模块MySQL表引擎是MyISAM的,是不支持事务的,而新上的模块又采用了InnoDB表引擎,在这种情况下,DAL应能对原有模块进行优雅降级。即:一个系统支持多种数据库,来实现数据库层的迁移,升级等。
(3).失败恢复也是要考虑的,失败后,需要把失败前驻留在内存中的消息找回来。
(4).另外,DAL本身也在快速的迭代当中,升级是很经常的事,应能进行在线热升级(不重启原有服务)。
3、良好的性能
对于根据id来取进行的查询,在缓存命中的情况下,应该达到和Memcached不相上下的读取速度。在缓存不命中的情况下,则应该充分利用分库分表和并行计算的优势,最大化地提高查询的效率。对于修改型查询,挂在上面的监听器,不应该影响性能。
4、易于编程
需要设计一套简单好用的API便于应用程序的开发。API必须是自完备的应用开发者不需要太费力就能记住的。应用开发人员不再关心分库分表问题,不再关心缓存问题,特别是缓存清除问题。甚至不再关心后端的数据库是MySQL,还是Oracle,或者是其它。
5、可定制、可扩展、可维护的架构设计
像连接池组件、缓存组件、查询分析组件、消息队列组件、通讯协议等等不应该写死,应设计成可方便定制的。还应该提供足够的钩子用于扩展。只有这样,DAL 的架构才是灵活的、拥抱变化的。简单说,我们定的是机制,提供的是策略,机制是软件目标和宗旨的体现,一般是不能轻易改变的,而策略则应当是能比较简单地进行切换的。
分布式数据访问层应用案例
1、TDDL
淘宝根据自己的业务特点开发了TDDL(Taobao Distributed Data Layer)框架,主要解决了分库分表对应用的透明化以及异构数据库之间的数据复制,它是一个基于集中式配置的 jdbc datasource实现,具有主备,读写分离,动态数据库配置等功能。
TDDL所处的位置(tddl通用数据访问层,部署在客户端的jar包,用于将用户的SQL路由到指定的数据库中):
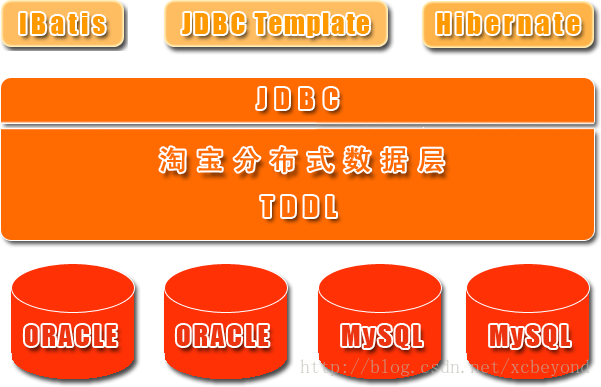
淘宝很早就对数据进行过分库的处理, 上层系统连接多个数据库,中间有一个叫做DBRoute的路由来对数据进行统一访问。DBRoute对数据进行多库的操作、数据的整合,让上层系统像操作 一个数据库一样操作多个库。但是随着数据量的增长,对于库表的分法有了更高的要求,例如,你的商品数据到了百亿级别的时候,任何一个库都无法存放了,于是 分成2个、4个、8个、16个、32个……直到1024个、2048个。好,分成这么多,数据能够存放了,那怎么查询它?这时候,数据查询的中间件就要能 够承担这个重任了,它对上层来说,必须像查询一个数据库一样来查询数据,还要像查询一个数据库一样快(每条查询在几毫秒内完成),TDDL就承担了这样一 个工作。在外面有些系统也用DAL(数据访问层) 这个概念来命名这个中间件。
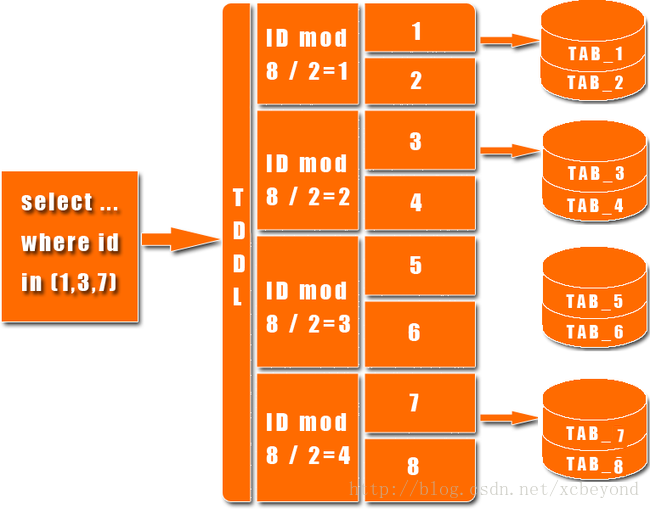
下图展示了一个简单的分库分表数据查询策略:
主要优点:
(1).数据库主备和动态切换
(2).带权重的读写分离
(3).单线程读重试
(4).集中式数据源信息管理和动态变更
(5).剥离的稳定jboss数据源
(6).支持mysql和oracle数据库
(7).基于jdbc规范,很容易扩展支持实现jdbc规范的数据源
(8).无server,client-jar形式存在,应用直连数据库
(9).读写次数,并发度流程控制,动态变更
(10).可分析的日志打印,日志流控,动态变更
TDDL必须要依赖diamond配置中心(diamond是淘宝内部使用的一个管理持久配置的系统,目前淘宝内部绝大多数系统的配置,由diamond来进行统一管理,同时diamond也已开源)。
TDDL源码:https://github.com/alibaba/tb_tddl
2、CobarClient
Cobar Client是一个轻量级分布式数据访问层(DAL)基于iBatis(已更名为MyBatis)和Spring框架实现。
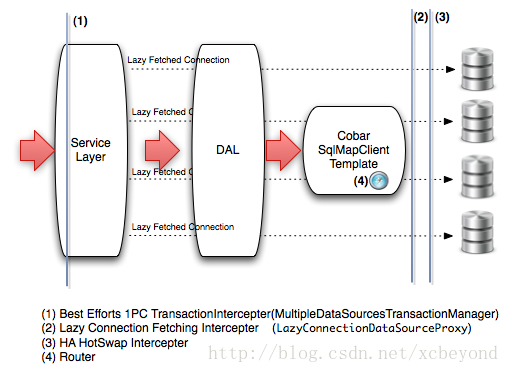
主要特性:
(1).可以支持垂直和水平数据切分数据库集群的访问。
(2).支持双机热备的HA解决方案, 应用方可以根据情况选用数据库特定的HA解决方案(比如Oracle的RAC),或者选用CobarClient提供的HA解决方案。
(3).小数据量的数据集计(Aggregation), 暂时只支持简单的数据合并。
(4).数据库本地事务的支持, 目前采用Best Efforts 1PC模式的事务管理。
(5).数据访问操作相关SQL的记录, 分析等.(可以采用国际站现有Ark解决方案,但CobarClient提供扩展的切入接口)。
转自:https://blog.csdn.net/xcbeyond/article/details/54976983
以上是关于1.1 DAL数据访问层的主要内容,如果未能解决你的问题,请参考以下文章