21.scrapy爬虫部署
Posted lvjing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了21.scrapy爬虫部署相关的知识,希望对你有一定的参考价值。
1.启用 scrapyd
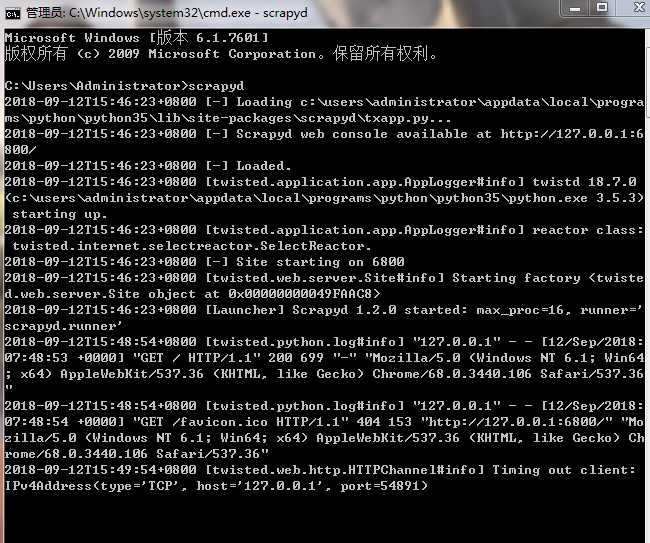
2.
在浏览器打开127.0.0.1:6800/
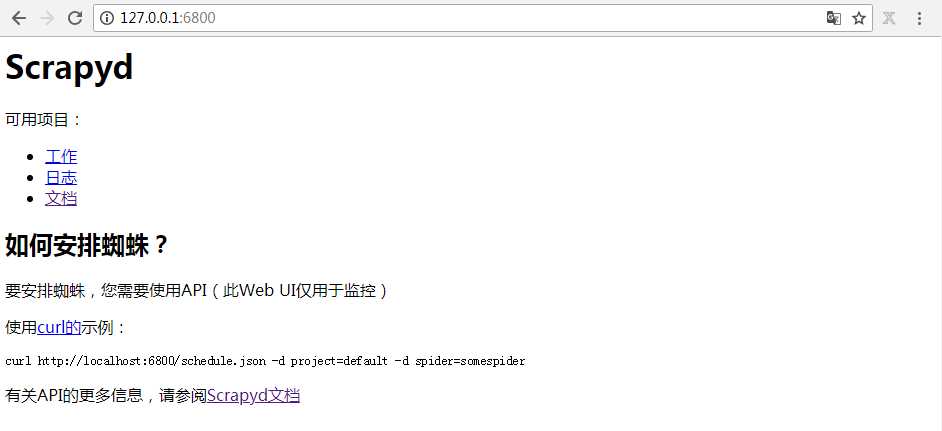
3.
scrapy.cfg 设置
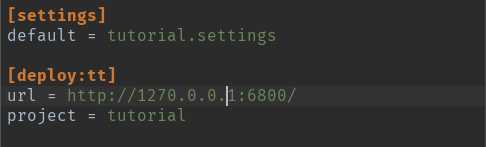
4.
遇到问题: scrapyd-deploy 不是内部命令

编辑 两个配置文件
@echo off
"C:UsersAdministratorAppDataLocalProgramsPythonPython35python.exe" "C:UsersAdministratorAppDataLocalProgramsPythonPython35Scriptsscrapy" %*
并添加到环境变量里
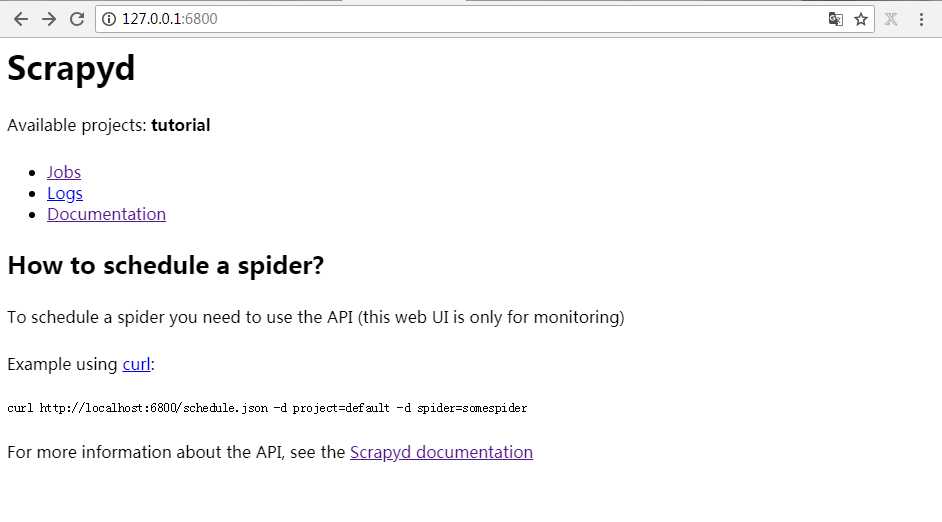
5.
部署成功

用 scrapyd-deploy -l 验证

可以看到有一个可用的 projects
6.启动爬虫使用curl命令
curl http://127.0.0.1/6800/schedule.json -d project=tutorial -d spider=QuotesSpider
windows 安装curl http://curl.haxx.se/download.html
将 curl.exe 放到c盘 system32 就可以全局使用


防火墙 高级设置 入站规则 新建规则 端口 根据情况 下一步就可以
这里 执行爬虫程序出了一点问题没有解决,明天再解决。
以上是关于21.scrapy爬虫部署的主要内容,如果未能解决你的问题,请参考以下文章