Pinpoint完整集群实现,包括flink集群的加入
Posted easton-wang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pinpoint完整集群实现,包括flink集群的加入相关的知识,希望对你有一定的参考价值。
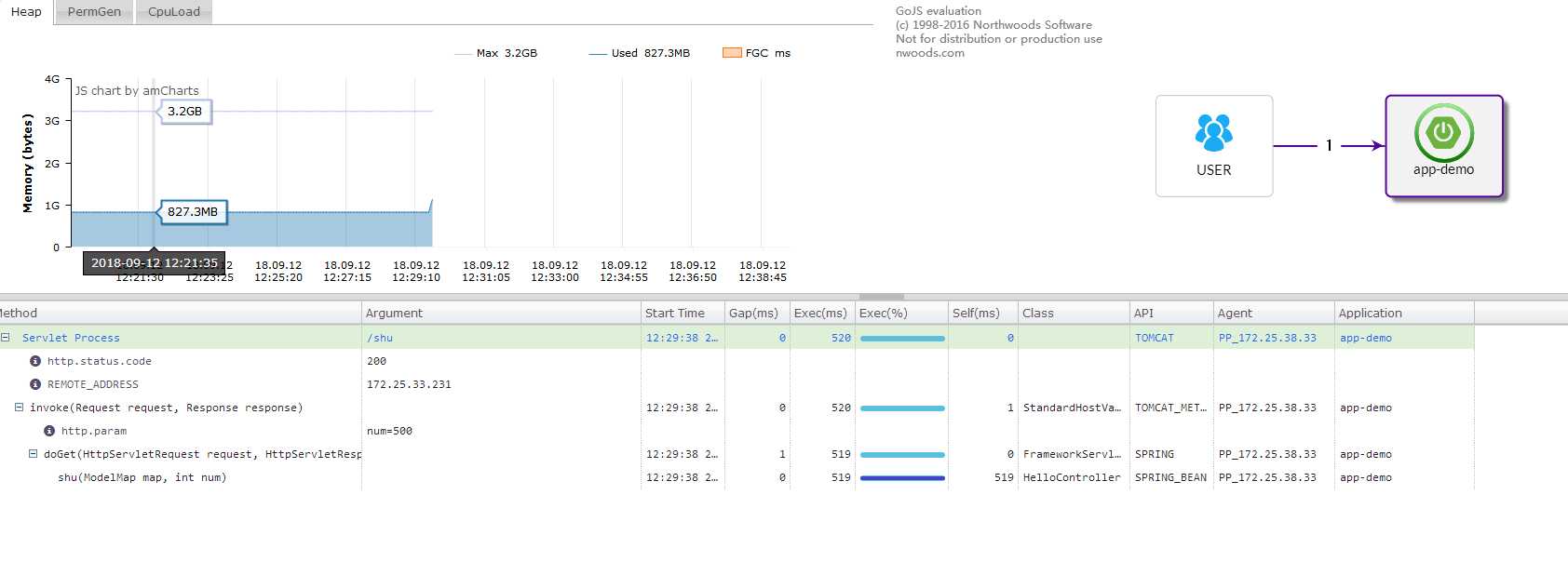
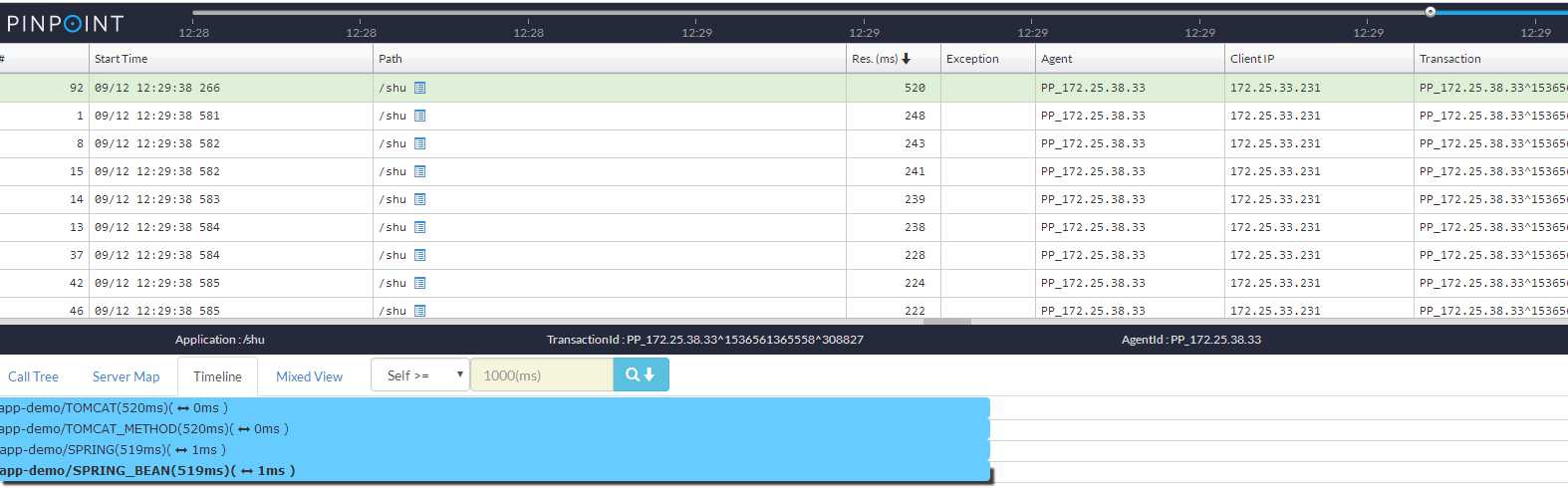
Pinpoint是韩国人开发的一套基于java的Apm(应用性能监控),具有低延迟、实时监控、拓扑发现、低性能损耗的特点(官方预估是3%),同事有一个完善的web后台,一目了然查看应用拓扑。
安装使用前我搜索了网上一堆的文档,几乎都是半路货或是比较旧,一半靠官网,一半靠摸索理解,还好感谢官网的协助,最终全部搭建成功。为了方便以后其它人的使用,我用ansible搭建成大部分的初始化部分,但剩下几个小步骤还是需要手动执行下,例如数据库的导入,修改job的架包等
这里要搭建是一套可以实际用的pinpoint集群,我测试环境用3台机器来实现,分别是
172.25.33.230 : zookeeper,hadoop,hbase,collector,web,nginx
172.25.33.231 : zookeeper,hadoop,hbase,collector
172.25.33.232 : zookeeper,hadoop,hbase,collector
搭建的顺序首选是
1、搭建一套zookeeper集群
2、搭建一套hdfs集群
3、搭建hbase集群
4、搭建flink集群
5、启动多个collector应用,利用nginx负载均衡(实际使用建议用keepalive)
6、启动web管理后台
7、使用一个jar应用添加agent进行测试
看起来是不是具体搭建比较麻烦,包括各种配置。这里我用ansible几乎完成全部配置,只要稍微修改下参数的设置,就可以完成一整套搭建,所以搭建的顺序改成
1、三个测试机器部署ssh免密登录
2、下载配置好的环境
3、批量ansible.vars.yml 中的IP,
4、安装ansible,执行ansible-playbook
5、启动以及导入数据库
6、搭建一个nginx用于负载均衡controller
7、启动所有东西
这样看起来就比较简单实现,下面开始来搭建
1、三个测试机器部署ssh免密登录
1 #进入root目录 2 ssh-keygen #一路回车 3 cd /root/.ssh 4 mv id_rsa.pub authorized_keys 5 scp -p authorized_keys 172.25.33.231:/root/.ssh/ 6 scp -p authorized_keys 172.25.33.232:/root/.ssh/
然后作下测试:
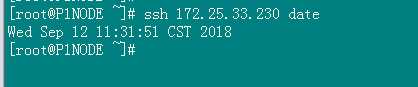
ssh 免密是必须的,这个关系到hdfs的搭建,hbase集群的搭建
2、下载配置好的环境
cd /opt git clone https://github.com/rainard/apm-pinpoint.git mv apm-pinpoint apm cd apm
3、批量ansible.vars.yml 中的IP
这个好像没啥好说的,直接用文本全部替换,把三个ip都替换成实际搭建要用到的IP,例如下图。文章最后我再解释这些参数的意义,
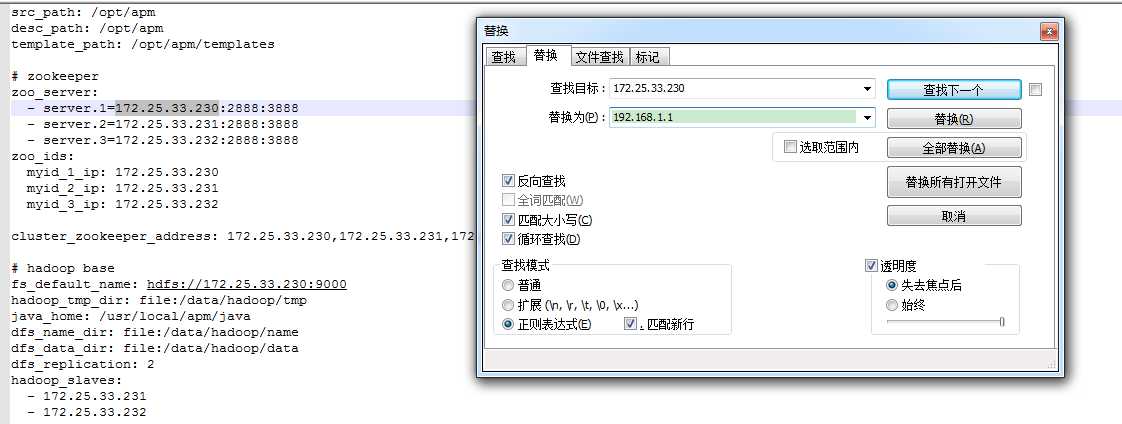
替换mysql的帐号密码(ansible.vars.yml)
## pinpoint-web jdbc config jdbc_driverClassName: com.mysql.jdbc.Driver jdbc_url: jdbc:mysql://172.25.33.230:3306/pinpoint?characterEncoding=UTF-8 jdbc_user: root jdbc_password: test
4、安装ansible,执行ansible-playbook
安装ansible
yum install -y ansible
执行ansible-playbook
cd /opt/apm
ansible-playbook ansible_rsync.play.yml

这样执行完后,整个集群基本就配置好了,下面做一些收尾工作,然后启动集群
5、启动以及导入数据库
在三台机器的/etc/profile中添加必须的路径配置,添加完最好重启下
JAVA_HOME=/usr/local/apm/java HADOOP_HOME=/usr/local/apm/hadoop HADOOP_INSTALL=$HADOOP_HOME HADOOP_MAPRED_HOME=$HADOOP_HOME HADOOP_COMMON_HOME=$HADOOP_HOME HADOOP_HDFS_HOME=$HADOOP_HOME YARN_HOME=$HADOOP_HOME HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native HBASE_CLASSPATH=$HADOOP_HOME/etc/hadoop/ HBASE_MANAGES_ZK=false ZOOKEEPER_HOME=/usr/local/apm/zookeeper PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin: PATH=$PATH:/usr/local/mysql/bin:
在三台机器上启动zookeeper集群
/usr/local/apm/zookeeper/bin/zkServer.sh start ;
测试zookeeper的启动情况
/usr/local/apm/zookeeper/bin/zkServer.sh status
下面的启动操作在172.25.33.230上面执行
hdfs格式化namenode,仅第一次启动需要
/usr/local/apm/hadoop/bin/hdfs namenode -format
启动hdfs集群
/usr/local/apm/hadoop/sbin/start-all.sh
启动hbase集群
/usr/local/apm/hbase/bin/start-hbase.sh
导入hbase数据库
/usr/local/apm/hbase/bin/hbase shell /usr/local/apm/hbase-create.hbase
启动flink集群
/usr/local/apm/flink/bin/start-cluster.sh
导入web数据库(非必须,只是用于报警)
*** 关于mysql ****
web的报警部分数据存在mysql,如果你想要报警相关,需要把额外提供一个mysql,并创建pinpoint数据库
#下面两个sql文件导入pinpoint数据库 /usr/local/apm/pinpoint-web-tomcat/ROOT/WEB-INF/classes/sql/CreateTableStatement-mysql.sql /usr/local/apm/pinpoint-web-tomcat/ROOT/WEB-INF/classes/sql/SpringBatchJobRepositorySchema-mysql.sql
启动web
/usr/local/apm/pinpoint-web-tomcat/bin/startup.sh
--------------collector
三个机器启动collector
/usr/local/apm/pinpoint-controller-tomcat/bin/startup.sh
利用nginx为三个collector做负载均衡,实际运用中建议加上keepalive,这里提供nginx的一个虚机配置文件
[[email protected] tcp]# cat pinpoint.conf upstream 9994_tcp_upstreams { #least_timefirst_byte; #fail_timeout=15s; server 172.25.33.230:9994; server 172.25.33.231:9994; server 172.25.33.232:9994; } upstream 9995_udp_upstreams { #least_timefirst_byte; server 172.25.33.230:9995; server 172.25.33.231:9995; server 172.25.33.232:9995; } upstream 9996_udp_upstreams { #least_timefirst_byte; server 172.25.33.230:9996; server 172.25.33.231:9996; server 172.25.33.232:9996; } server { listen 39994; proxy_pass 9994_tcp_upstreams; #proxy_timeout 1s; proxy_connect_timeout 1s; } server { listen 39995 udp; proxy_pass 9995_udp_upstreams; proxy_timeout 1s; #proxy_responses1; } server { listen 39996 udp; proxy_pass 9996_udp_upstreams; proxy_timeout 1s; #proxy_responses1; }
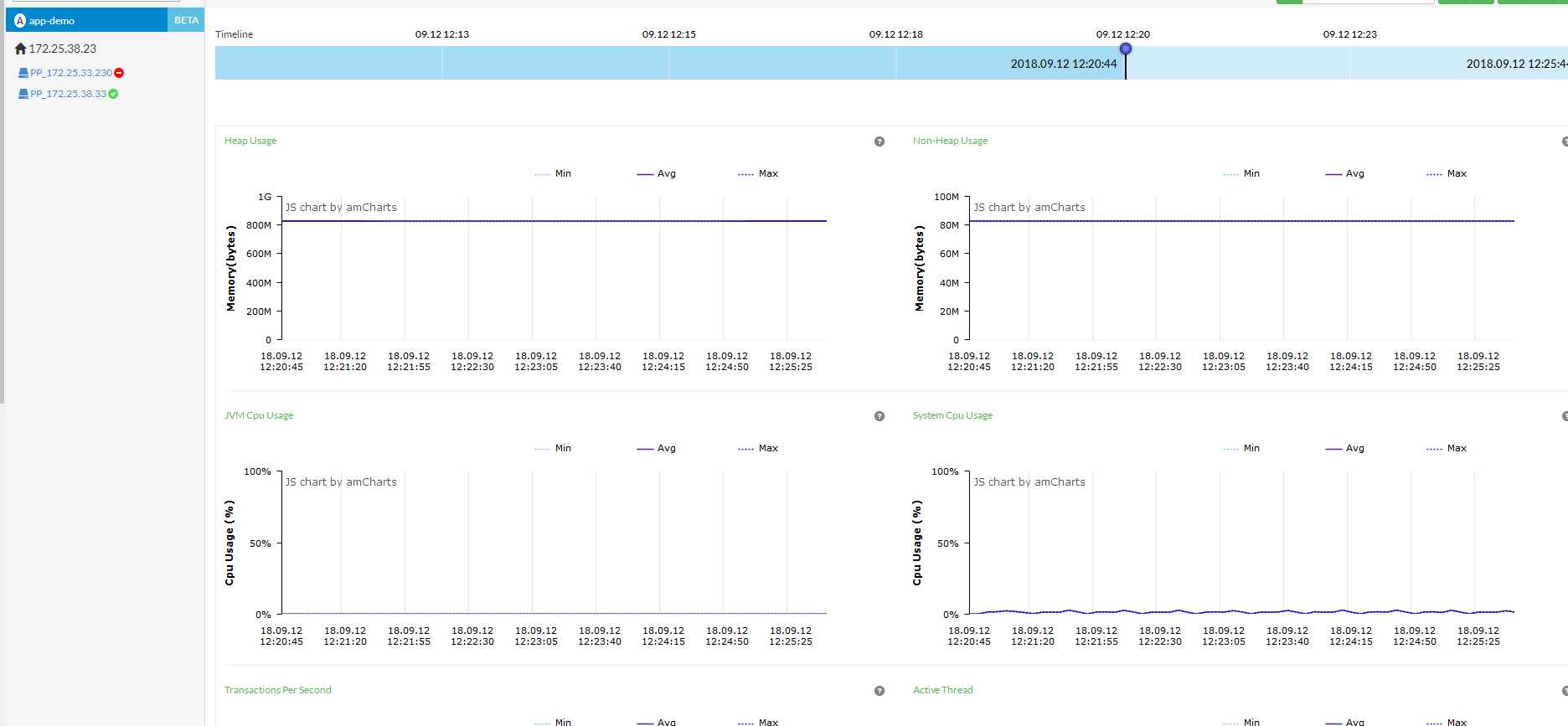
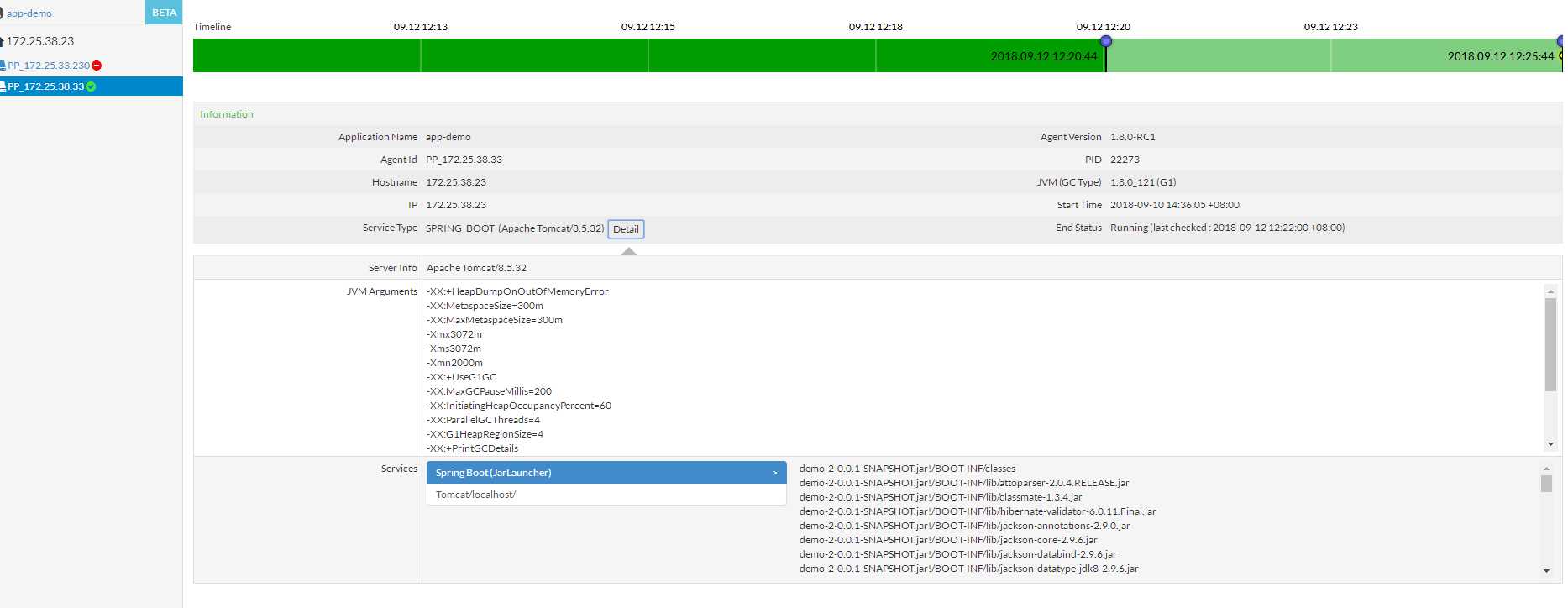
到这里,集群的所有操作以及搭建完毕,那么agent怎么操作呢?
在启动的jvm里面添加
-javaagent:/usr/local/apm/pinpoint-agent/pinpoint-bootstrap-1.8.0-RC1.jar -Dpinpoint.agentId=PP_172.25.33.230
-Dpinpoint.applicationName=app-demo
javaagent : 是agent架包的位置
Dpinpoint.agentId : 是这个应用部署的节点id,节点唯一
Dpinpoint.applicationName :是应用的名称,每个应用唯一
以上是关于Pinpoint完整集群实现,包括flink集群的加入的主要内容,如果未能解决你的问题,请参考以下文章