ES && Lecence介绍[转]
Posted qianqian-li
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ES && Lecence介绍[转]相关的知识,希望对你有一定的参考价值。
https://www.jianshu.com/p/40ec55c6e614 备注
1. Lucene介绍
为了更深入地理解ElasticSearch的工作原理,特别是索引和查询这两个过程,理解Lucene的工作原理至关重要。本质上,ElasticSearch是用Lucene来实现索引的查询功能的。
1.1 定义
Lucene是一个成熟的、高性能的、可扩展的、轻量级的,而且功能强大的搜索引擎包。Lucene的核心jar包只有一个文件,而且不依赖任何第三方jar包。更重要的是,它提供的索引数据和检索数据的功能开箱即用。当然,Lucene也提供了多语言支持,具有拼写检查、高亮等功能。
1.2 架构
1.2.1 术语
Lucene中的术语和 <
1.2.2 存储
Apache Lucene把所有的信息都写入到一个称为倒排索引的数据结构中,倒排索引的介绍可以参考 <
1.3 数据分析
学习ES初期,我经常考虑的问题是,传入到Document中的数据是如何转变成倒排索引的?查询语句是如何转换成一个个Term使高效率文本搜索变得可行?这种转换数据的过程就称为文本分析(analysis)
文本分析工作由analyzer组件负责。analyzer由一个分词器(tokenizer)和0个或者多个过滤器(filter)组成,也可能会有0个或者多个字符映射器(character mappers)组成。
Lucene中的tokenizer用来把文本拆分成一个个的Token。Token包含了比较多的信息,比如Term在文本的中的位置及Term原始文本,以及Term的长度。文本经过tokenizer处理后的结果称为token stream。token stream其实就是一个个Token的顺序排列。token stream将等待着filter来处理。
除了tokenizer外,Lucene的另一个重要组成部分就是filter链,filter链将用来处理Token Stream中的每一个token。这些处理方式包括删除Token,改变Token,甚至添加新的Token。Lucene中内置了许多filter,读者也可以轻松地自己实现一个filter。有如下内置的filter:
- Lowercase filter:把所有token中的字符都变成小写
- ASCII folding filter:去除tonken中非ASCII码的部分
- Synonyms filter:根据同义词替换规则替换相应的token
- Multiple language-stemming
- filters:把Token(实际上是Token的文本内容)转化成词根或者词干的形式。
所以通过Filter可以让analyzer有几乎无限的处理能力:因为新的需求添加新的Filter就可以了。
1.4 索引和查询
-
索引过程:Lucene用用户指定好的analyzer解析用户添加的Document。当然Document中不同的Field可以指定不同的analyzer。如果用户的Document中有title和description两个Field,那么这两个Field可以指定不同的analyzer。
-
搜索过程:用户的输入查询语句将被选定的查询解析器(query parser)所解析,生成多个Query对象。当然用户也可以选择不解析查询语句,使查询语句保留原始的状态。在ElasticSearch中,有的Query对象会被解析(analyzed),有的不会,比如:前缀查询(prefix query)就不会被解析,精确匹配查询(match query)就会被解析。对用户来说,理解这一点至关重要。
对于索引过程和搜索过程的数据解析这一环节,我们需要把握的重点在于:倒排索引中词应该和查询语句中的词正确匹配。如果无法匹配,那么Lucene也不会返回我们喜闻乐见的结果。举个例子:如果在索引阶段对文本进行了转小写(lowercasing)和转变成词根形式(stemming)处理,那么查询语句也必须进行相同的处理。或是查询使用的analyzer必须和索引时使用的analyzer相同。
1.4 查询语言
用户使用Lucene进行查询操作时,输入的查询语句会被分解成一个或者多个Term以及逻辑运算符号。一个Term,在Lucene中可以是一个词,也可以是一个短语(用双引号括引来的多个词)。如果事先设定规则:解析查询语句,那么指定的analyzer就会用来处理查询语句的每个term形成Query对象。
具体的语法细节部分,想要描述起来是个庞大的工程,具体可参考对应文档。
在ES中也可以使用Lucene的语法进行查询,使用方法可参考:https://www.elastic.co/guide/en/elasticsearch/reference/5.2/modules-scripting-expression.html
2. ES 介绍
2.1 介绍
引用我认为最简洁的一句话来概括ES
**Elasticsearch 是一个基于Lucene的分布式搜索和分析引擎.**- 1
2.2 基本概念
-
索引(Index):ElasticSearch把数据存放到一个或者多个索引(indices)中。ElasticSearch内部用Apache Lucene实现索引中数据的读写。但是在ElasticSearch中被视为单独的一个索引(index),在Lucene中可能不止一个。这是因为在分布式体系中,ElasticSearch会用到分片(shards)和备份(replicas)机制将一个索引(index)存储多份。
-
文档(Document):文档(Document)由一个或者多个字段(Field)组成。ES中的文档(Document)是没有固定的模式和统一的结构。
- 文档类型(Type):每个文档在ElasticSearch中都必须设定它的类型。文档类型使得同一个索引中在存储结构不同文档时,只需要依据文档类型就可以找到对应的参数映射(Mapping)信息,方便文档的存取。
-
节点(Node):单独一个ElasticSearch服务器实例称为一个节点。对于许多应用场景来说,部署一个单节点的ElasticSearch服务器就足够了。但是考虑到容错性和数据过载,配置多节点的ElasticSearch集群是明智的选择。
-
集群(Cluster):集群是多个ElasticSearch节点的集合。是提供高可用与高性能的重要手段
-
分片索引(Shard):集群能够存储超出单机容量的信息。为了实现这种需求,ElasticSearch把数据分发到多个存储Lucene索引的物理机上。这些Lucene索引称为分片索引,这个分发的过程称为索引分片(Sharding)。
需要注意的是:集群中分片的数量需要在索引创建前配置好,而且服务器启动后是无法修改的,至少目前无法修改。
-
索引副本(Replica):当集群负载增长,用户搜索请求可能会阻塞在单个节点上时,通过索引副本(Replica)机制就可以解决这个问题。在提供基础查询性能的同时,也保证了数据的安全性。即如果主分片数据丢失,ElasticSearch通过索引副本使得数据不丢失。索引副本可以随时添加或者删除,所以用户可以在需要的时候动态调整其数量。
-
网管(Gateway):ES运行过程中需要的所有数据(文档,状态、索引参数等)都被存储在Gateway中。
2.3 工作原理
本部分从启动,故障检测,数据索引,查询 四个部分进行总结
2.3.1 启动
当Elasticsearch节点启动时,会使用发现(discovery)模块来通过发送广播请求的方式发现同一个集群中的其他节点。
在集群中有一个节点被选为主(master)节点。该节点负责集群的状态管理以及在集群拓扑变化时做出反应,分发索引分片至集群的相应节点上去。
在用户看来集群中节点的角色是透明的。使用的过程中不需要知道哪个节点是管理节点,请求可以发送给任意节点,如果有需要,任意节点可以并行发送子查询给其他节点,并合并搜索结果,然后返回给用户。所有这些操作并不需要经过管理节点处理(请记住,Elasticsearch是基于对等架构的)。
在启动阶段,管理节点会读取集群的状态信息并检查有哪些索引分片,并决定哪些分片将用作主分片。此后,整个集群进入黄色状态。
这意味着集群可以执行查询,但是系统的吞吐量以及各种可能的状况是未知的(这种状况可以简单理解为所有的主分片已经被分配了,但是副本没有被分配)。下面的事情就是寻找到冗余的分片用作副本。如果某个主分片的副本数过少,管理节点将决定基于某个主分片创建分片和副本。如果一切顺利,集群将进入绿色状态(这意味着所有主分片以及副本均已分配好)。
2.3.2 故障检测
集群正常工作时,管理节点会监控所有可用节点,通过PING的方式检查它们是否正在工作。如果任何节点在预定义的超时时间内不响应,则认为该节点已经断开,然后错误处理过程开始启动。这意味着可能要在集群–分片之间重新做平衡,选择新的主节点等。对每个丢失的主分片,一个新的主分片将会从原来的主分片的副本中选出来。
2.3.3 与ElasticSearch通信
Elasticsearch对外公开了一个设计精巧的API,通过这些API可以进行索引以及查询的操作,传参的方式主要包括URL携带或是JSON文档的形式。
2.3.4 数据索引
数据索引的方式可以通过简单的API一条一条的索引,也可以通过Bulk API(包括HTTP,UDP两种)进行批量的创建索引。
有一件事情需要记住,建索引操作只会发生在主分片上,而不是副本上。当一个索引请求被发送至一个节点上时,如果该节点没有对应的主分片或者只有副本,那么这个请求会被转发到拥有正确的主分片的节点。然后,该节点将会把索引请求群发给所有副本,等待它们的响应(这一点可以由用户控制),最后,当特定条件具备时(比如说达到规定数目的副本都完成了更新时)结束索引过程。
流程如下
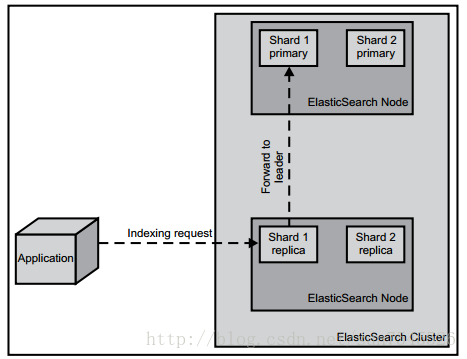
2.3.5 查询
Elasticsearch提供了丰富的查询功能,后续章节会对查询功能进行简单的总结,本节主要讨论查询的机制。
关于查询操作需要注意的是:查询并不是一个简单的、单步骤的操作。一般来说,查询分为两个阶段:分散阶段(scatter phase)和合并阶段(gather phase)。在分散阶段将查询分发到包含相关文档的多个分片中去执行查询,而在合并阶段则从众多分片中收集返回结果,然后对它们进行合并、排序,进行后续处理,然后返回给客户端。该机制可以由下图描述。
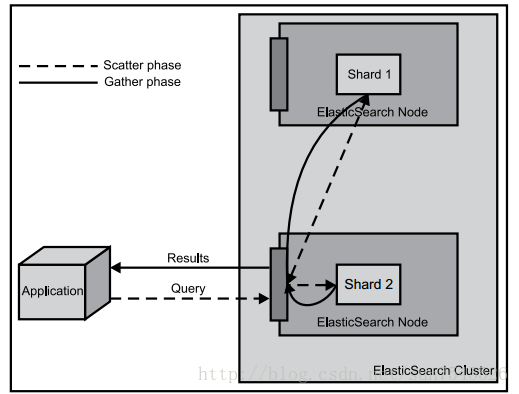
参考
- 《深入理解Elasticsearch》
- https://www.elastic.co/guide/cn/elasticsearch/guide/current/foreword_id.html
以上是关于ES && Lecence介绍[转]的主要内容,如果未能解决你的问题,请参考以下文章
十分钟玩转模块化:ES Modules && ConmonJS 使用详解
JavaScript的ES6中async&&await的简单使用以及介绍
Android音视频十三OpenSL ES介绍&基于OpenSL ES实现音频采集