TCP/IP网络编程之地址族与数据序列
Posted beiluowuzheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TCP/IP网络编程之地址族与数据序列相关的知识,希望对你有一定的参考价值。
分配IP地址和端口号
IP是Internet Protocol(网络协议)的简写,是为收发网络数据而分配给计算机的值。端口号并非赋予计算机的值,而是为区分程序中创建的套接字而分配给套接字的序号
网络地址(Internet Address)
为使计算机连接到网络并收发数据,必须向其分配IP地址。IP地址分为两类:
- IPv4(Internet Protocol version 4):4字节地址族
- IPv6(Internet Protocol version 6):16字节地址族
IPv4和IPv6的差别主要是IP地址所用的字节数,目前通用的地址族为IPv4,IPv6是为了应对2010年前后IP地址耗尽的问题而提出的标准,即便如此,现在还是主要使用IPv4,IPv6的普及需要更长的时间
IPv4标准的4字节IP地址分为网络地址和主机(计算机)地址,且分为A、B、C、D、E等类型,图1-1展示了IPv4地址族,一般不会使用已被预约的E类地址,故省略
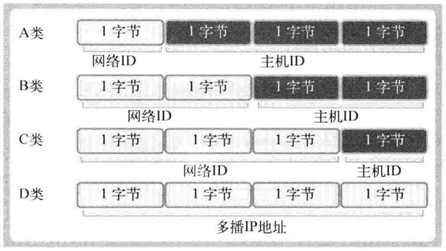
图1-1 IPv4地址族
网络地址(网络ID)是为区分网络而设置的一部分IP地址。假设向WWW.SEMI.COM公司传输数据,该公司内部构建了局域网,把所有计算机连起来。因此,首先应向SEMI.COM网络传输数据,也就是说,并非一开始就浏览所有4字节IP地址,进而找到目标主机;而是仅浏览4字节IP地址的网络地址,先把数据送到SEMI.COM网络,SEMI.COM网络(构成网络的路由器)接收到数据后,浏览传输数据的主机地址(主机ID)并将数据传给目标主机。图1-2展示了数据传输过程
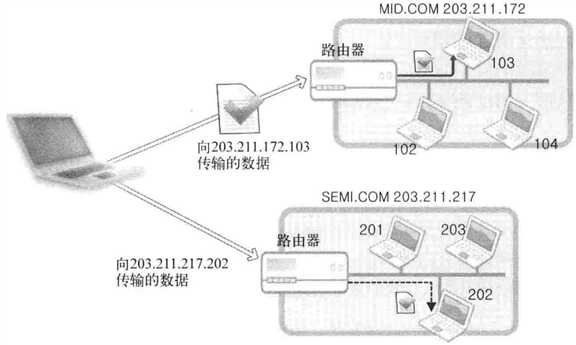
图1-2 基于IP地址的数据传输过程
某主机向203.211.172.103和203.211.217.202传输数据,其中203.211.172和203.211.217为该网络的网络地址。所以,“向相应网络传输数据”实际上是向构成网络的路由器(Route)或交换机(Switch)传递数据,由接收数据的路由器根据数据中的主机地址向目标主机传递数据
若想构建网络,需要一种物理设备完成外网与本网主机之间的数据交换,这种设备便是路由器或交换机。它们实际上也是一种计算机,只不过是为特殊目的而设计运行的,因此有了别名。所以,如果在我们使用的计算机上安装适当的软件,也可以将其作为交换机。另外,交换机比路由器功能要简单一些,但实际用途差别不大
网络地址分类与主机地址边界
只需通过IP地址的第一个字节即可判断网络地址占用的字节数,因为我们根据IP地址的边界区分网络地址,如下所示:
- A类地址的首字节范围:0~127
- B类地址的首字节范围:128~191
- C类地址的首字节范围:192~223
还有如下这种表述方式:
- A类地址的首位以0开始,0000 0000为0,0111 111为127,与上面的0~127对应
- B类地址的前2位以10开始,1000 0000为128,1011 1111为191,与上面的128~191对应
- C类地址的前3位以110开始,1100 0000为192,1101 1111为223,与上面的192~223对应
正因如此,通过套接字收发数据时,数据传到网络后即可轻松找到正确主机
用于区分套接字的端口号
IP用于区分计算机,只要有IP地址就能找到目标主机,但仅凭这些无法传输给目标主机中的应用程序,毕竟处理数据靠的还是目标主机中的程序。假设用户在上网的同时,一边欣赏视频,一边浏览网页,这里至少需要两个套接字,一个接收视频数据,一个接收网页数据,那么问题来了,怎么区分这两个套接字呢?或者说,怎么区分到达的数据是正在观看的视频,还是正在浏览的网页呢?这里就需要用到端口号了
计算机中一般配有NIC(Network Interface Card,网络接口卡)数据传输设备。通过NIC向计算机内部传输数据时会用到IP,操作系统负责把传递到内部的数据适配给套接字,这时就要利用端口号了。也就是说,通过NIC接收的数据内有端口号,操作系统正是参考此端口号把数据传输给相应端口的套接字,如图1-3所示
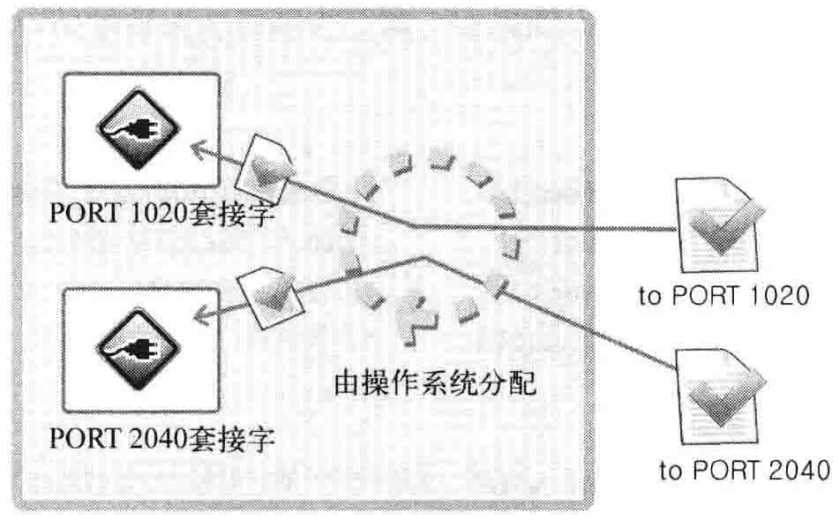
图1-3 数据分配过程
端口号就是同一操作系统内区分不同套接字而设置的,因此无法将一个端口号分配给不同套接字。另外,端口号由16位构成,可分配的端口号范围是0~65535。但0~1023是知名端口(Well-known PORT),一般分配给特定应用程序,所以应当分配此范围之外的端口。另外,虽然端口号不能重复,但TCP套接字和UDP套接字不会共用端口号,所以允许重复。例如:如果某TCP套接字使用8500号端口,则其他TCP套接字就无法使用该端口号,但UDP套接字可以使用
总之,数据传输目标地址同时包含IP地址和端口号,只有这样,数据才会被传输到最终的目的应用程序
地址信息的表示
应用程序中使用IP地址和端口号以结构体的形式给出了定义。这里将以IPv4为中心,围绕此结构体讨论目标地址的表示方法
struct sockaddr_in
{
short sin_family; //协议族Address family
unsigned short sin_port; //16位TCP/UDP端口号
struct in_addr sin_addr; //32位IP地址
unsigned char sin_zero[8]; //没有实际意义,只是为了跟SOCKADDR结构在内存中对齐
};
该结构体中提到另一结构体in_addr定义如下,它用来存放32位IP地址
struct in_addr
{
in_addr_t s_addr; //32位IPv4地址
};
讲解以上两个结构体前观察一些数据类型。uint16_t、int_addr_t等类型可以参考POSIX(Portable Operating System Interface,可移植操作系统接口)。POSIX是为Unix系列操作系统设立的标准,它定义了一些其他数据类型,如表1-1
| 数据类型名称 | 数据类型说明 | 声明的头文件 |
| int8_t | signed 8-bit int | sys/types.h |
| uint8_t | unsigned 8-bit int(unsigned char) | |
| int16_t | signed 16-bit int | |
| uint16_t | unsigned 16-bit int(unsigned short) | |
| int32_t | signed 32-bit int | |
| uint32_t | unsigned 32-bit int(unsigned long) | |
| sa_family_t | 地址族(address family) | sys/socket.h |
| socklen_t | 长度(length of struct) | |
| in_addr_t | IP地址,声明为uint32_t | netinet/in.h |
| in_port_t | 端口号,声明为uint16_t |
从这些数据类型声明也可掌握之前结构体的含义,那为什么需要额外定义这些数据类型呢?这是考虑到扩展性的结果。如果使用int32_t类型的数据,就能保证在任何时候都占用4个字节,即时将来使用64位表示int类型也是如此
结构体sockaddr_in的成员分析
成员sin_family:
每种协议适用的地址族均不同。比如,IPv4使用4字节地址族,IPv6使用16字节地址族,可以参考表1-2保存的sin_family地址信息
| 地址族(Adddress Family) | 含义 |
| AF_INET | IPv4网络协议中使用的地址族 |
| AF_INET6 | IPv6网络协议中使用的地址族 |
| AF_LOCAL | 本地通信中采用的Unix协议的地址族 |
AF_LOCAL只是为了说明具有多种地址族而添加的
成员sin_port:
该成员保存32位IP地址信息,且以网络字节序保存(后续还会说明何为网络字节序)
成员sin_addr:
该成员保存32位IP地址信息,且也以网络字节序保存。为理解好该成员,应同时观察结构体in_addr。但结构体in_addr声明为uint32_t,因此只需当做32位整数即可
成员sin_zero:
无特殊含义,只是为了结构体sockaddr_in的大小与sockaddr结构体保持一致而插入的成员。必须填充为0,否则无法得到想要的结果,后续还会介绍sockaddr
从之前介绍的代码也可看出,sockaddr_in结构体变量地址将以如下方式传递给bind函数,后续还会介绍到bind函数,现在来看下下面参数传递和类型转换的代码
struct sockaddr_in serv_addr;
……
if (bind(serv_sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr)) == -1)
error_handling("bind() error");
……
此处重要的是第二个参数的传递,实际上,bind函数的第二个参数期望得到sockaddr结构体变量地址值,包括地址族、端口号、IP地址等。从下列代码也可看出,直接向sockaddr结构体填充这些信息会带来麻烦
struct sockaddr
{
unsigned short sa_family; //地址族(Address Family)
char sa_data[14]; //地址信息
};
此结构体成员要求sa_data保存的信息需包含IP地址和端口号,剩余部分应填充0,这也是bind函数要求的。而这对于包含地址信息来讲非常麻烦,继而就有了新的结构体sockaddr_in。若按照之前的讲解填写sockaddr_in结构体,则将生成符合bind函数要求的字节流。最后转换为sockaddr型的结构体变量,再传递给bind函数即可
sockaddr_in是保存IPv4地址信息的结构体,那为何还需要通过sin_family单独指定地址族信息呢?这还是与sockaddr结构体有关,结构体sockaddr并非只为IPv4设计,这从保存地址信息的数组sa_data长度为14字节也可看出。因此,结构体sockaddr要求在sin_family中指定地址族信息,是为了与sockaddr保持一致,sockaddr_in结构体中也有地址族信息
网络字节序与地址变换
不同CPU中,4字节整数值1在内存空间的保存方式是不同的。4字节整数型值1可用二进制表示如下:
00000000 00000000 00000000 00000001
有些CPU以这种顺序保存到内存,另一些CPU则以倒序保存
00000001 00000000 00000000 00000000
若不考虑这些就收发数据则会发生问题,因为保存顺序的不同意味着对接收数据的解析顺序也不同
字节序(Order)与网络字节序
CPU向内存保存数据的方式有两种,这意味着CPU解析数据的方式也有两种:
- 大端序:高位字节存放到低位地址
- 小端序:高位字节存放到高位地址
用下面的例子进行说明,假设在0x20号开始的地址中保存4字节int类型数0x12345678,大端序CPU保存如图1-4所示:
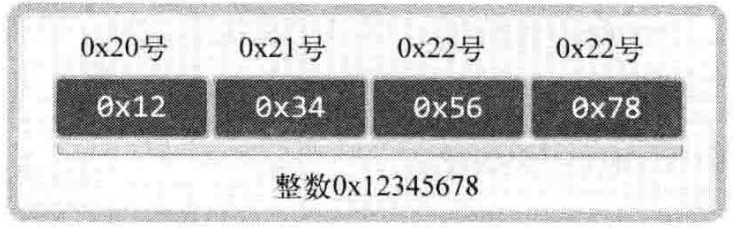
图1-4 大端序字节表示
整数0x12345678,0x12是最高位字节,0x78是最低位字节。因此,大端序先保存最高位字节0x12(最高位字节0x12存放到低位地址),小端序保存方式如图1-5所示:
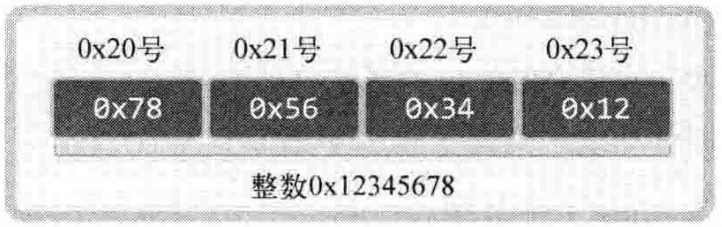
图1-5 小端序字节表示
先保存的是最低位字节0x78,从以上分析可以看出,每种CPU的数据保存方式均不同。因此,代表CPU数据保存方式的主机字节序(Host Byte Order)在不同CPU中也各不相同。目前主流的Intel系列CPU以小端序方式保存数据。那么,如果两台字节序不同的计算机之间交换数据,势必会出现这样的问题,大端序计算机传输数据0x1234时未考虑字节序问题,直接以0x12、0x34的顺序发送,结果接收端以小端序方式保存数据,因此小端序接收到的数据则变为0x3412,而非0x1234。正因如此,在通过网络传输数据时约定统一使用大端序传输数据
字节序转换
既然我们明白了在填充sockaddr_in结构体前将数据转换成网络字节序。接下来,我们就来了解一下关于转换字节序的函数:
- unsigned short htons(unsigned short);
- unsigned short ntohs(unsigned short);
- unsigned long htonl(unsigned long);
- unsigned long ntohl(unsigned long);
htons中的h代表主机(host)字节序,n代表网络(network)字节序。另外,s指的是short,l指的是long(Linux中long类型占用4个字节)。因此,htons是h、to、n、s的组合,也可以解释为“把short型数据从主机字节序转化为网络字节序”。而ntohs可以解释为“把short类型数据从主机字节序转化为网络字节序”。通常,以s作为后缀的函数中,s代表两个字节short,因此用于端口号转换,以l作为后缀的函数中,1代表4个字节,因此用于IP地址转换
下面通过示例说明以上函数的调用过程
endian_conv.c
#include <stdio.h>
#include <arpa/inet.h>
int main(int argc, char *argv[])
{
unsigned short host_port = 0x1234;
unsigned short net_port;
unsigned long host_addr = 0x12345678;
unsigned long net_addr;
net_port = htons(host_port);
net_addr = htonl(host_addr);
printf("Host ordered port:%#x
", host_port);
printf("Network ordered port:%#x
", net_port);
printf("Host ordered address:%#lx
", host_addr);
printf("Network ordered address:%#lx
", net_addr);
return 0;
}
- 第6、8行:各保存2个字节、4个字节的数据。当然,若运行的CPU不同,则保存的字节序也不同
- 第11、12行:变量host_port、host_addr中的数据转化为网络字节序。若运行环境为小端序CPU,则改变之后的字节序保存
编译并运行endian_conv.c
# gcc endian_conv.c -o endian_conv # ./endian_conv Host ordered port:0x1234 Network ordered port:0x3412 Host ordered address:0x12345678 Network ordered address:0x78563412
这就是小端序CPU中运行的结果。如果在大端序CPU中运行,则变量值不会改变
网络地址的初始化与分配
前面已讨论过网络字节序列,接下来介绍bind函数为代表的结构体的应用
将字符串信息转换为网络字节序的整型
sockaddr_in中保存地址信息的成员为32位整数型,因此,为了分配IP地址,需要将其表示为32位整数型数据。这对于只熟悉字符串信息的我们并非易事,对于IP的表示,我们熟悉点分十进制法,而非整数型数据表示法。幸运的是,有个函数会帮我们将字符串形式的IP转换为32位整数型数据
#include <arpa/inet.h> in_addr_t inet_addr(const char* strptr);//成功时返回32位大端序整数型值,失败时返回INADDR_NONE
如果向该函数传递“211.214.107.99”的点分十进制格式的字符串,它会将其转换为32位整数型数据并返回。当然,该整数型值满足网络字节序。另外,该函数的返回值类型in_addr_t在内部声明为32位整数型。下面示例表示该函数的调用过程
inet_addr.c
#include <stdio.h>
#include <arpa/inet.h>
int main(int argc, char *argv[])
{
char *addr1 = "1.2.3.4";
char *addr2 = "1.2.3.256";
unsigned long conv_addr = inet_addr(addr1);
if (conv_addr == INADDR_NONE)
printf("Error occured!
");
else
printf("Network ordered integer addr:%#lx
", conv_addr);
conv_addr = inet_addr(addr2);
if (conv_addr == INADDR_NONE)
printf("Error occured!
");
else
printf("Network ordered integer addr:%#lx
", conv_addr);
return 0;
}
- 第6行:一个字节能表示的最大整数为255,也就是说,它是错误的IP地址。利用该错误地址检验inet_addr函数的错误检测能力
- 第8、13行:通过运行结果验证第8行的函数能正常调用,而第13行的函数调用出现异常
编译并运行inet_addr.c
# ./inet_addr Network ordered integer addr:0x4030201 Error occured!
从运行结果上来看,inet_addr函数不仅可以把IP地址转换为32位整数型,而且可以检测无效的IP地址。另外,从输出结果可以验证确实转换为网络字节序
inet_aton函数与inet_addr函数在功能上完全相同,也将字符串形式IP地址转换为32位网络字节序整数并返回,只不过该函数利用了in_addr结构体
1
---恢复内容结束---
分配IP地址和端口号
IP是Internet Protocol(网络协议)的简写,是为收发网络数据而分配给计算机的值。端口号并非赋予计算机的值,而是为区分程序中创建的套接字而分配给套接字的序号
网络地址(Internet Address)
为使计算机连接到网络并收发数据,必须向其分配IP地址。IP地址分为两类:
- IPv4(Internet Protocol version 4):4字节地址族
- IPv6(Internet Protocol version 6):16字节地址族
IPv4和IPv6的差别主要是IP地址所用的字节数,目前通用的地址族为IPv4,IPv6是为了应对2010年前后IP地址耗尽的问题而提出的标准,即便如此,现在还是主要使用IPv4,IPv6的普及需要更长的时间
IPv4标准的4字节IP地址分为网络地址和主机(计算机)地址,且分为A、B、C、D、E等类型,图1-1展示了IPv4地址族,一般不会使用已被预约的E类地址,故省略
图1-1 IPv4地址族
网络地址(网络ID)是为区分网络而设置的一部分IP地址。假设向WWW.SEMI.COM公司传输数据,该公司内部构建了局域网,把所有计算机连起来。因此,首先应向SEMI.COM网络传输数据,也就是说,并非一开始就浏览所有4字节IP地址,进而找到目标主机;而是仅浏览4字节IP地址的网络地址,先把数据送到SEMI.COM网络,SEMI.COM网络(构成网络的路由器)接收到数据后,浏览传输数据的主机地址(主机ID)并将数据传给目标主机。图1-2展示了数据传输过程
图1-2 基于IP地址的数据传输过程
某主机向203.211.172.103和203.211.217.202传输数据,其中203.211.172和203.211.217为该网络的网络地址。所以,“向相应网络传输数据”实际上是向构成网络的路由器(Route)或交换机(Switch)传递数据,由接收数据的路由器根据数据中的主机地址向目标主机传递数据
若想构建网络,需要一种物理设备完成外网与本网主机之间的数据交换,这种设备便是路由器或交换机。它们实际上也是一种计算机,只不过是为特殊目的而设计运行的,因此有了别名。所以,如果在我们使用的计算机上安装适当的软件,也可以将其作为交换机。另外,交换机比路由器功能要简单一些,但实际用途差别不大
网络地址分类与主机地址边界
只需通过IP地址的第一个字节即可判断网络地址占用的字节数,因为我们根据IP地址的边界区分网络地址,如下所示:
- A类地址的首字节范围:0~127
- B类地址的首字节范围:128~191
- C类地址的首字节范围:192~223
还有如下这种表述方式:
- A类地址的首位以0开始,0000 0000为0,0111 111为127,与上面的0~127对应
- B类地址的前2位以10开始,1000 0000为128,1011 1111为191,与上面的128~191对应
- C类地址的前3位以110开始,1100 0000为192,1101 1111为223,与上面的192~223对应
正因如此,通过套接字收发数据时,数据传到网络后即可轻松找到正确主机
用于区分套接字的端口号
IP用于区分计算机,只要有IP地址就能找到目标主机,但仅凭这些无法传输给目标主机中的应用程序,毕竟处理数据靠的还是目标主机中的程序。假设用户在上网的同时,一边欣赏视频,一边浏览网页,这里至少需要两个套接字,一个接收视频数据,一个接收网页数据,那么问题来了,怎么区分这两个套接字呢?或者说,怎么区分到达的数据是正在观看的视频,还是正在浏览的网页呢?这里就需要用到端口号了
计算机中一般配有NIC(Network Interface Card,网络接口卡)数据传输设备。通过NIC向计算机内部传输数据时会用到IP,操作系统负责把传递到内部的数据适配给套接字,这时就要利用端口号了。也就是说,通过NIC接收的数据内有端口号,操作系统正是参考此端口号把数据传输给相应端口的套接字,如图1-3所示
图1-3 数据分配过程
端口号就是同一操作系统内区分不同套接字而设置的,因此无法将一个端口号分配给不同套接字。另外,端口号由16位构成,可分配的端口号范围是0~65535。但0~1023是知名端口(Well-known PORT),一般分配给特定应用程序,所以应当分配此范围之外的端口。另外,虽然端口号不能重复,但TCP套接字和UDP套接字不会共用端口号,所以允许重复。例如:如果某TCP套接字使用8500号端口,则其他TCP套接字就无法使用该端口号,但UDP套接字可以使用
总之,数据传输目标地址同时包含IP地址和端口号,只有这样,数据才会被传输到最终的目的应用程序
地址信息的表示
应用程序中使用IP地址和端口号以结构体的形式给出了定义。这里将以IPv4为中心,围绕此结构体讨论目标地址的表示方法
struct sockaddr_in
{
short sin_family; //协议族Address family
unsigned short sin_port; //16位TCP/UDP端口号
struct in_addr sin_addr; //32位IP地址
unsigned char sin_zero[8]; //没有实际意义,只是为了跟SOCKADDR结构在内存中对齐
};
该结构体中提到另一结构体in_addr定义如下,它用来存放32位IP地址
struct in_addr
{
in_addr_t s_addr; //32位IPv4地址
};
讲解以上两个结构体前观察一些数据类型。uint16_t、int_addr_t等类型可以参考POSIX(Portable Operating System Interface,可移植操作系统接口)。POSIX是为Unix系列操作系统设立的标准,它定义了一些其他数据类型,如表1-1
| 数据类型名称 | 数据类型说明 | 声明的头文件 |
| int8_t | signed 8-bit int | sys/types.h |
| uint8_t | unsigned 8-bit int(unsigned char) | |
| int16_t | signed 16-bit int | |
| uint16_t | unsigned 16-bit int(unsigned short) | |
| int32_t | signed 32-bit int | |
| uint32_t | unsigned 32-bit int(unsigned long) | |
| sa_family_t | 地址族(address family) | sys/socket.h |
| socklen_t | 长度(length of struct) | |
| in_addr_t | IP地址,声明为uint32_t | netinet/in.h |
| in_port_t | 端口号,声明为uint16_t |
从这些数据类型声明也可掌握之前结构体的含义,那为什么需要额外定义这些数据类型呢?这是考虑到扩展性的结果。如果使用int32_t类型的数据,就能保证在任何时候都占用4个字节,即时将来使用64位表示int类型也是如此
结构体sockaddr_in的成员分析
成员sin_family:
每种协议适用的地址族均不同。比如,IPv4使用4字节地址族,IPv6使用16字节地址族,可以参考表1-2保存的sin_family地址信息
| 地址族(Adddress Family) | 含义 |
| AF_INET | IPv4网络协议中使用的地址族 |
| AF_INET6 | IPv6网络协议中使用的地址族 |
| AF_LOCAL | 本地通信中采用的Unix协议的地址族 |
AF_LOCAL只是为了说明具有多种地址族而添加的
成员sin_port:
该成员保存32位IP地址信息,且以网络字节序保存(后续还会说明何为网络字节序)
成员sin_addr:
该成员保存32位IP地址信息,且也以网络字节序保存。为理解好该成员,应同时观察结构体in_addr。但结构体in_addr声明为uint32_t,因此只需当做32位整数即可
成员sin_zero:
无特殊含义,只是为了结构体sockaddr_in的大小与sockaddr结构体保持一致而插入的成员。必须填充为0,否则无法得到想要的结果,后续还会介绍sockaddr
从之前介绍的代码也可看出,sockaddr_in结构体变量地址将以如下方式传递给bind函数,后续还会介绍到bind函数,现在来看下下面参数传递和类型转换的代码
struct sockaddr_in serv_addr;
……
if (bind(serv_sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr)) == -1)
error_handling("bind() error");
……
此处重要的是第二个参数的传递,实际上,bind函数的第二个参数期望得到sockaddr结构体变量地址值,包括地址族、端口号、IP地址等。从下列代码也可看出,直接向sockaddr结构体填充这些信息会带来麻烦
struct sockaddr
{
unsigned short sa_family; //地址族(Address Family)
char sa_data[14]; //地址信息
};
此结构体成员要求sa_data保存的信息需包含IP地址和端口号,剩余部分应填充0,这也是bind函数要求的。而这对于包含地址信息来讲非常麻烦,继而就有了新的结构体sockaddr_in。若按照之前的讲解填写sockaddr_in结构体,则将生成符合bind函数要求的字节流。最后转换为sockaddr型的结构体变量,再传递给bind函数即可
sockaddr_in是保存IPv4地址信息的结构体,那为何还需要通过sin_family单独指定地址族信息呢?这还是与sockaddr结构体有关,结构体sockaddr并非只为IPv4设计,这从保存地址信息的数组sa_data长度为14字节也可看出。因此,结构体sockaddr要求在sin_family中指定地址族信息,是为了与sockaddr保持一致,sockaddr_in结构体中也有地址族信息
网络字节序与地址变换
不同CPU中,4字节整数值1在内存空间的保存方式是不同的。4字节整数型值1可用二进制表示如下:
00000000 00000000 00000000 00000001
有些CPU以这种顺序保存到内存,另一些CPU则以倒序保存
00000001 00000000 00000000 00000000
若不考虑这些就收发数据则会发生问题,因为保存顺序的不同意味着对接收数据的解析顺序也不同
字节序(Order)与网络字节序
CPU向内存保存数据的方式有两种,这意味着CPU解析数据的方式也有两种:
- 大端序:高位字节存放到低位地址
- 小端序:高位字节存放到高位地址
用下面的例子进行说明,假设在0x20号开始的地址中保存4字节int类型数0x12345678,大端序CPU保存如图1-4所示:
图1-4 大端序字节表示
整数0x12345678,0x12是最高位字节,0x78是最低位字节。因此,大端序先保存最高位字节0x12(最高位字节0x12存放到低位地址),小端序保存方式如图1-5所示:
图1-5 小端序字节表示
先保存的是最低位字节0x78,从以上分析可以看出,每种CPU的数据保存方式均不同。因此,代表CPU数据保存方式的主机字节序(Host Byte Order)在不同CPU中也各不相同。目前主流的Intel系列CPU以小端序方式保存数据。那么,如果两台字节序不同的计算机之间交换数据,势必会出现这样的问题,大端序计算机传输数据0x1234时未考虑字节序问题,直接以0x12、0x34的顺序发送,结果接收端以小端序方式保存数据,因此小端序接收到的数据则变为0x3412,而非0x1234。正因如此,在通过网络传输数据时约定统一使用大端序传输数据
字节序转换
既然我们明白了在填充sockaddr_in结构体前将数据转换成网络字节序。接下来,我们就来了解一下关于转换字节序的函数:
- unsigned short htons(unsigned short);
- unsigned short ntohs(unsigned short);
- unsigned long htonl(unsigned long);
- unsigned long ntohl(unsigned long);
htons中的h代表主机(host)字节序,n代表网络(network)字节序。另外,s指的是short,l指的是long(Linux中long类型占用4个字节)。因此,htons是h、to、n、s的组合,也可以解释为“把short型数据从主机字节序转化为网络字节序”。而ntohs可以解释为“把short类型数据从主机字节序转化为网络字节序”。通常,以s作为后缀的函数中,s代表两个字节short,因此用于端口号转换,以l作为后缀的函数中,1代表4个字节,因此用于IP地址转换
下面通过示例说明以上函数的调用过程
endian_conv.c
#include <stdio.h>
#include <arpa/inet.h>
int main(int argc, char *argv[])
{
unsigned short host_port = 0x1234;
unsigned short net_port;
unsigned long host_addr = 0x12345678;
unsigned long net_addr;
net_port = htons(host_port);
net_addr = htonl(host_addr);
printf("Host ordered port:%#x
", host_port);
printf("Network ordered port:%#x
", net_port);
printf("Host ordered address:%#lx
", host_addr);
printf("Network ordered address:%#lx
", net_addr);
return 0;
}
- 第6、8行:各保存2个字节、4个字节的数据。当然,若运行的CPU不同,则保存的字节序也不同
- 第11、12行:变量host_port、host_addr中的数据转化为网络字节序。若运行环境为小端序CPU,则改变之后的字节序保存
编译并运行endian_conv.c
# gcc endian_conv.c -o endian_conv # ./endian_conv Host ordered port:0x1234 Network ordered port:0x3412 Host ordered address:0x12345678 Network ordered address:0x78563412
这就是小端序CPU中运行的结果。如果在大端序CPU中运行,则变量值不会改变
网络地址的初始化与分配
前面已讨论过网络字节序列,接下来介绍bind函数为代表的结构体的应用
将字符串信息转换为网络字节序的整型
sockaddr_in中保存地址信息的成员为32位整数型,因此,为了分配IP地址,需要将其表示为32位整数型数据。这对于只熟悉字符串信息的我们并非易事,对于IP的表示,我们熟悉点分十进制法,而非整数型数据表示法。幸运的是,有个函数会帮我们将字符串形式的IP转换为32位整数型数据
#include <arpa/inet.h> in_addr_t inet_addr(const char* strptr);//成功时返回32位大端序整数型值,失败时返回INADDR_NONE
如果向该函数传递“211.214.107.99”的点分十进制格式的字符串,它会将其转换为32位整数型数据并返回。当然,该整数型值满足网络字节序。另外,该函数的返回值类型in_addr_t在内部声明为32位整数型。下面示例表示该函数的调用过程
inet_addr.c
#include <stdio.h>
#include <arpa/inet.h>
int main(int argc, char *argv[])
{
char *addr1 = "1.2.3.4";
char *addr2 = "1.2.3.256";
unsigned long conv_addr = inet_addr(addr1);
if (conv_addr == INADDR_NONE)
printf("Error occured!
");
else
printf("Network ordered integer addr:%#lx
", conv_addr);
conv_addr = inet_addr(addr2);
if (conv_addr == INADDR_NONE)
printf("Error occured!
");
else
printf("Network ordered integer addr:%#lx
", conv_addr);
return 0;
}
- 第6行:一个字节能表示的最大整数为255,也就是说,它是错误的IP地址。利用该错误地址检验inet_addr函数的错误检测能力
- 第8、13行:通过运行结果验证第8行的函数能正常调用,而第13行的函数调用出现异常
编译并运行inet_addr.c
# ./inet_addr Network ordered integer addr:0x4030201 Error occured!
从运行结果上来看,inet_addr函数不仅可以把IP地址转换为32位整数型,而且可以检测无效的IP地址。另外,从输出结果可以验证确实转换为网络字节序
inet_aton函数与inet_addr函数在功能上完全相同,也将字符串形式IP地址转换为32位网络字节序整数并返回,只不过该函数利用了in_addr结构体
#include <arpa/inet.h> int inet_aton(const char *string, struct in_addr*addr);//成功时返回1,失败时返回0
- string:含有需转换的IP地址信息的字符串地址
- addr:将保存转件结果的in_addr结构体变量的地址值
实际编程中若要调用inet_addr函数,需将转换后的IP地址信息代入sockaddr_in结构体中声明的in_addr结构体变量。而inet_aton函数则不需此过程,原因在于,若传递in_addr结构体变量地址值,函数会自动把结果填入该结构体变量。通过示例了解一下inet_aton函数调用过程
inet_aton.c
#include <stdio.h>
#include <stdlib.h>
#include <arpa/inet.h>
void error_handling(char *message);
int main(int argc, char *argv[])
{
char *addr = "127.232.124.79";
struct sockaddr_in addr_inet;
if (!inet_aton(addr, &addr_inet.sin_addr))
error_handling("Conversion error");
else
printf("Network ordered integer addr:%#x
", addr_inet.sin_addr.s_addr);
return 0;
}
void error_handling(char *message)
{
fputs(message, stderr);
fputc(‘
‘, stderr);
exit(1);
}
- 第9、10行:转换后的IP地址信息需保存到sockaddr_in的in_addr型变量才有意义。因此,inet_aton函数的第二个参数要求得到in_addr型的变量地址值。这就省去了手动保存IP地址信息的过程
编译并运行inet_aton.c
# gcc inet_aton.c -o inet_aton # ./inet_aton Network ordered integer addr:0x4f7ce87f
最后再介绍一个与inet_aton函数相反的函数,此函数可以把网络字节序整数型IP转换成我们熟悉的字符串形式
#include <arpa/inet.h> char *inet_ntoa(struct in_addr in);//成功时返回转换的字符串地址值,失败时返回-1
该函数将通过参数传入的整数型IP地址转换为字符串格式并返回。但调用时需小心 ,返回值类型为char指针,返回字符串地址意味着字符串已保存到内存空间了,但该函数未向程序员要求分配内存,而是在其函数内部申请内存并保存字符串。也就是说,调用完函数后,应立即将字符串复制到其他的内存空间。因为,若再次调用inet_ntoa函数,则有可能覆盖之前保存的字符串信息。总之,再次调用inet_ntoa函数前返回的字符串地址值是有效的,若需长期保存,则应将字符串复制到其他内存空间。下面给出该函数调用示例:
inet_ntoa.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <arpa/inet.h>
int main(int argc, char *argv[])
{
struct sockaddr_in addr1, addr2;
char *str_ptr;
char str_arr[20];
addr1.sin_addr.s_addr = htonl(0x1020304);
addr2.sin_addr.s_addr = htonl(0x1010101);
str_ptr = inet_ntoa(addr1.sin_addr);
strcpy(str_arr, str_ptr);
printf("Dotted-Decimal notation1:%s
", str_ptr);
inet_ntoa(addr2.sin_addr);
printf("Dotted-Decimal notation2:%s
", str_ptr);
printf("Dotted-Decimal notation3:%s
", str_arr);
return 0;
}
- 第15行:向inet_ntoa函数传递结构体变量addr1中的IP地址信息并调用该函数,返回字符串形式的IP地址
- 第16行:浏览并复制第15行中返回的IP地址信息
- 第19、20行:再次调用inet_ntoa函数。由此得出,第15行中返回的地址已覆盖了新的IP地址字符串,可通过第20行的输出结果进行验证
- 第21行:第16行中复制了字符串,因此可以正确输出第15行中返回的IP地址字符串
编译运行inet_ntoa.c
# gcc inet_ntoa.c -o inet_ntoa # ./inet_ntoa Dotted-Decimal notation1:1.2.3.4 Dotted-Decimal notation2:1.1.1.1 Dotted-Decimal notation3:1.2.3.4
网络地址初始化
结合前面所学的内容,现在介绍创建套接字过程中常见的网络地址信息初始化方法
struct sockaddr_in addr; char *serv_ip = "211.217.168.13"; //声明IP地址字符串 char *serv_port = "8500"; //声明端口号字符串 memset(&addr, 0, sizeof(addr)); //结构体变量addr的所有成员初始化为0 addr.sin_family = AF_INET; //指定地址族 addr.sin_addr.s_addr = inet_addr(serv_ip); //基于字符串的IP地址初始化 addr.sin_port = htons(atoi(serv_port)); //基于字符串的端口号初始化
上述代码中,memset函数将每一个字节初始化为同一个值:第一个参数为结构体变量addr的地址值,即初始化为addr,第二个参数为0,因此初始化为0;最后一个参数中传入addr的长度。因此addr的所有字节均初始化为0。这么做是为了将sockaddr_in结构体成员sin_zero初始化为0,另外,最后一行代码调用atoi函数把字符串类型的值转换成整数型。总之,上面的代码利用字符串格式的IP地址和端口号初始化了sockaddr_in结构体变量
另外,代码中的IP地址和端口号采用了硬编码,这并不是一个好的写法,因为运行环境改变就得更改代码。因此,我们运行示例main函数时传入IP地址和端口号
请求方法不同意味着调用的函数也不同,服务器端的准备工作通过bind函数完成,而客户端则通过connect函数完成。因此,函数调用前需要的地址值类型也不同,服务端声明sockaddr_in结构体变量,将其初始化为赋予服务器端IP和套接字的端口号,然后调用bind函数;而客户端则声明sockaddr_in结构体,并初始化为要与之连接的服务器端套接字的IP和端口号,然后调用connect函数
INADDR_ANY
每次创建服务器端套接字都要输入IP地址会有些繁琐,此时可如下初始化地址信息
struct sockaddr_in addr; char *serv_port = "8500"; //声明端口号字符串 memset(&addr, 0, sizeof(addr)); //结构体变量addr的所有成员初始化为0 addr.sin_family = AF_INET; //指定地址族 addr.sin_addr.s_addr = htonl(INADDR_ANY); addr.sin_port = htons(atoi(serv_port)); //基于字符串的端口号初始化
与之前方式最大的区别在于,利用常数INADDR_ANY分配服务器端的IP地址。若是采用这种方式,则可自动获取运行服务端的计算机IP地址,不必亲自输入。而且,若同一计算机中已分配多个IP地址(多宿主计算机),则只要端口号一致,就可以从不同IP地址接收数据。因此,服务端中优先考虑这种方式
向套接字分配网络地址
既然已讨论了sockaddr_in结构体的初始化方法,接下来就把初始化的地址信息分配给套接字,bind函数负责这项操作:
#include <sys/socket.h> int bind(int sockfd, struct sockaddr *myaddr, socklen_t addrlen);
- sockfd:要分配地址信息(IP地址和端口号)的套接字文件描述符
- myaddr:存有地址信息的结构体变量地址值
- addrlen:第二个结构体变量的长度
如果此函数调用成功,则将第二个参数指定的地址信息分配给第一个参数中的相应套接字。下面给出服务器端常见的套接字初始化过程:
int serv_sock; struct sockaddr_in serv_addr; char *serv_port = "9190"; /*创建服务器端套接字(监听套接字)*/ serv_sock = socket(PF_INET, SOCK_STREAM, 0); /*地址信息初始化*/ memset(&serv_addr, 0, sizeof(serv_addr)); serv_addr.sin_family = AF_INET; serv_addr.sin_addr.s_addr = htonl(INADRR_ANY); serv_addr.sin_port = htons(atoi(serv_port)); /*分配地址信息*/ bind(serv_sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr));
……
服务端代码结构以上,当然还有未显示的异常处理代码
以上是关于TCP/IP网络编程之地址族与数据序列的主要内容,如果未能解决你的问题,请参考以下文章
Windows 环境下的 Socket 编程 2 - 地址族与数据序列
Windows 环境下的 Socket 编程 2 - 地址族与数据序列