决策树决策树与Jupyter小部件的交互式可视化
Posted jin-liang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树决策树与Jupyter小部件的交互式可视化相关的知识,希望对你有一定的参考价值。
简介
决策树是广泛用于分类和回归任务的监督模型。 在本文中,我们将讨论决策树分类器以及如何动态可视化它们。 这些分类器在训练数据上构建一系列简单的if / else规则,通过它们预测目标值。
在本演示中,我们将使用sklearn_wine数据集,使用sklearn export_graphviz函数,我们可以在Jupyter中显示树。
from sklearn.tree import DecisionTreeClassifier, export_graphviz from sklearn import tree from sklearn.datasets import load_wine from IPython.display import SVG from graphviz import Source from IPython.display import display # load dataset data = load_wine() # feature matrix X = data.data # target vector y = data.target # class labels labels = data.feature_names # print dataset description print(data.DESCR) estimator = DecisionTreeClassifier() estimator.fit(X, y) graph = Source(tree.export_graphviz(estimator, out_file=None , feature_names=labels, class_names=[‘0‘, ‘1‘, ‘2‘] , filled = True)) display(SVG(graph.pipe(format=‘svg‘)))

在树形图中,每个节点包含分割数据的条件(if / else规则)以及节点的一系列其他度量。基尼是指基尼杂质,它是节点杂质的量度,即节点内样品的均匀程度。我们说当一个节点的所有样本属于同一个类时它是纯粹的。在这种情况下,不需要进一步拆分,这个节点称为叶子。 Samples是节点中的实例数,而value数组显示每个类的这些实例的分布。在底部,我们看到节点的多数类。当export_graphviz的填充选项设置为True时,每个节点将根据多数类进行着色。
虽然易于理解,但通过构建复杂模型,决策树往往会过度拟合数据。过度拟合的模型很可能不会在“看不见的”数据中很好地概括。防止过度拟合的两种主要方法是修剪前和修剪后。预修剪意味着在创建之前限制树的深度,而后修剪是在树构建之后移除非信息节点。
Sklearn学习决策树分类器仅实现预修剪。可以通过若干参数来控制预修剪,例如树的最大深度,节点保持分裂所需的最小样本数以及叶所需的最小实例数。下面,我们在相同的数据上绘制决策树,这次设置max_depth = 3。
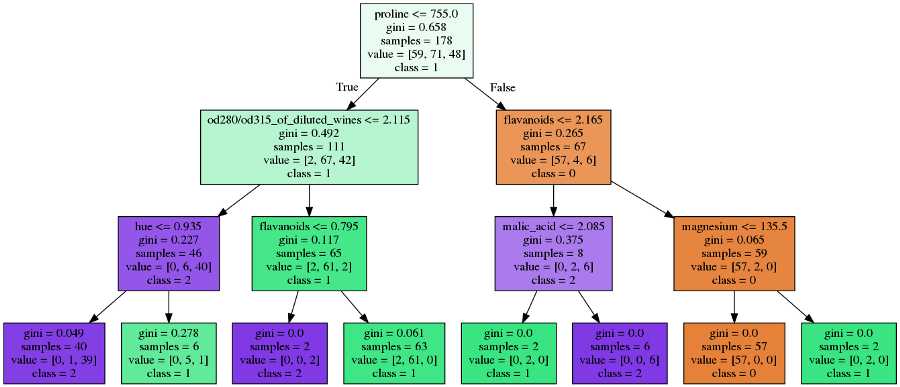
这个模型不太深,因此比我们最初训练和绘制的模型简单。
除了预修剪参数之外,决策树还有一系列其他参数,我们在构建分类模型时尝试优化这些参数。 我们通常通过查看准确度指标来评估这些参数的影响。 为了掌握参数的变化如何影响树的结构,我们可以再次在每个阶段可视化树。 我们可以使用Jupyter Widgets(ipywidgets)来构建我们树的交互式绘图,而不是每次进行更改时都绘制树。
Jupyter小部件是交互式元素,允许我们在笔记本中呈现控件。 通过pip和conda安装ipywidgets有两种选择。
用pip安装
pip install ipywidgets
jupyter nbextension enable --py widgetsnbextension
用conda安装
conda install -c conda-forge ipywidgets
对于此应用程序,我们将使用交互式功能。 首先,我们定义一个训练和绘制决策树的函数。 然后,我们将此函数与针对交互式函数感兴趣的每个参数的一组值一起传递。 后者返回我们用display显示的Widget实例。
from sklearn.tree import DecisionTreeClassifier, export_graphviz from sklearn import tree from sklearn.datasets import load_wine from IPython.display import SVG from graphviz import Source from IPython.display import display from ipywidgets import interactive # load dataset data = load_wine() # feature matrix X = data.data # target vector y = data.target # class labels labels = data.feature_names def plot_tree(crit, split, depth, min_split, min_leaf=0.2): estimator = DecisionTreeClassifier(random_state = 0 , criterion = crit , splitter = split , max_depth = depth , min_samples_split=min_split , min_samples_leaf=min_leaf) estimator.fit(X, y) graph = Source(tree.export_graphviz(estimator , out_file=None , feature_names=labels , class_names=[‘0‘, ‘1‘, ‘2‘] , filled = True)) display(SVG(graph.pipe(format=‘svg‘))) return estimator inter=interactive(plot_tree , crit = ["gini", "entropy"] , split = ["best", "random"] , depth=[1,2,3,4] , min_split=(0.1,1) , min_leaf=(0.1,0.5)) display(inter)

在此示例中,我们公开以下参数:
- criterion:衡量节点分裂质量的标准
- splitter:每个节点的拆分策略
- max_depth:树的最大深度
- min_samples_split:节点中所需的最小实例数
- min_samples_leaf:叶节点上所需的最小实例数
最后两个参数可以设置为整数或浮点数。 浮点数被解释为实例总数的百分比。 有关参数的更多详细信息,请阅读sklearn类文档。
以上是关于决策树决策树与Jupyter小部件的交互式可视化的主要内容,如果未能解决你的问题,请参考以下文章