数据可视化过程不完全指南
Posted shujufenxishi111
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据可视化过程不完全指南相关的知识,希望对你有一定的参考价值。
数据集犹如世界历史状态的快照,能帮助我们捕捉不断变化的事物,而数据可视化则是将复杂数据以简单的形式展示给用户的良好手段(或媒介)。结合个人书中所学与实际工作所学,对数据可视化过程做了一些总结形成本文供各位看客"消遣"。

个人以为数据可视化服务商业分析的经典过程可浓缩为:从业务与数据出发,经过数据分析与可视化形成报告,再跟踪业务调整回到业务,是个经典闭环。
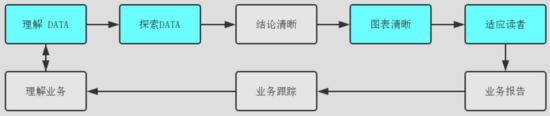
本文主题为数据可视化,将重点讲解与数据可视化相关的环节,也即上图中蓝色的环节。
一、理解 DATA
进行 DATA 探索前,我们需先结合业务去理解 DATA,这里推荐运用 5W1H 法,也即在拿到数据后问自身以下几个问题:
- Who: 是谁搜集了此数据? 在企业内可能更关注是来自哪个业务系统。
- How: 是如何采集的此数据? 尽可能去了解详细的采集规则,采集规则是影响后续分析的重要因素之一。如:数据来自埋点,来自后端还是前端差异很大,来自后端则多是实时的,来自前端则需更近一步了解数据在什么网络状态会上传、无网络状态下又是如何处理的。
- What: 是关于什么业务什么事? 数据所描述的业务主题。
- Why: 为什么搜集此数据? 我们想从数据中了解什么,其实也就是我们此次分析的目标。
- When: 是何时段内的业务数据?
- Where: 是何地域范围内的业务数据?
通过回答以上几个问题,我们能快速了解:数据来源是什么?它的可信度有多少?它在描述何时发生的怎样的业务(问题)?我们为什么要搜集此数据?等等。从而快速了解数据与业务开展近一步的探索与分析。
二、探索 DATA
之前的文章中,我们曾经分享过如何快速地探索 DATA ( 「如何成为一名数据分析师:数据的初步认知」 ),其中有谈到如何通过诸如平均数/中位数/众数等描述统计、通过相关系数统计快速探索 DATA 的方法。本文主要讲解可视化,所以将从可视化的角度去介绍如何通过可视化方法进行数据探索。
在探索、研究阶段,更重要的是要从不同的角度去观察数据,并逐步深入到对业务更重要的事情上。在这个阶段,我们不必去过多地追求图表美化,而应该尽可能快速地尝试更多个角度。下面我们根据数据/主题类型的差异分开阐述:
1. 分类数据的探索
在业务分析中,我们常常将人群、地点和其他事物进行分类,分类能为我们带来结构化,能让我们快速掌握信息。
在分类数据可视化中,我们最多使用的是条形图;但当试图观察分类中的比例时,我们可能也会选择饼图、瀑布图;当不仅关心一级分类还关心子分类时候,我们可能会选择树形图。通过对分类数据的可视化,我们能快速地获取最大、最小值,同时也能方便地了解到数据集的范围,因为它在一定程度上还反映了数据分布特征。下图展示了可视化分类数据的一些选择:
a. 条形图,用长度作为视觉暗示,利于直接比较。
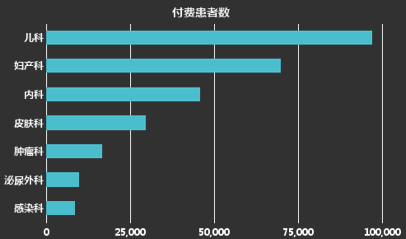
b. 使用饼图、柱形堆叠图、瀑布图等,能在分类数据中对比占比情况。
c. 使用树形图,能在展示一级分类的子类统计,可实现维度的又一层下钻。

2. 时序数据的探索
业务分析中,我们常常关心事物随着时间的变化趋势,以及数据随时间变化的规律(时间周期下的规律)。所以,对时序数据的探索,主要有两种模式:其一为随着时间线索向右延伸的时序图,诸如:折线图、堆积面积图等;其二为根据时间周期,统计汇总的柱形图、日历图、径向图等。
a. 用于观察事物随时间线索变化的探索。
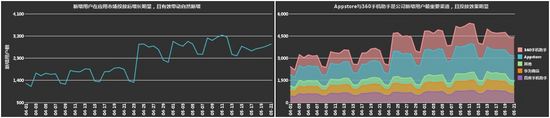
b. 用于发现事物随时间周期变化规律的探索。
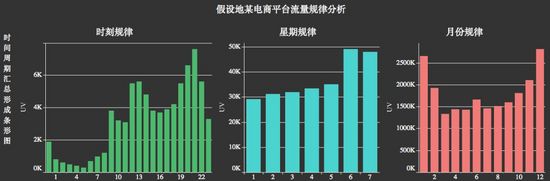
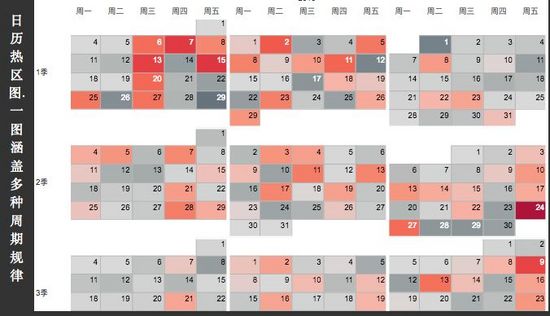
3. 空间数据的探索
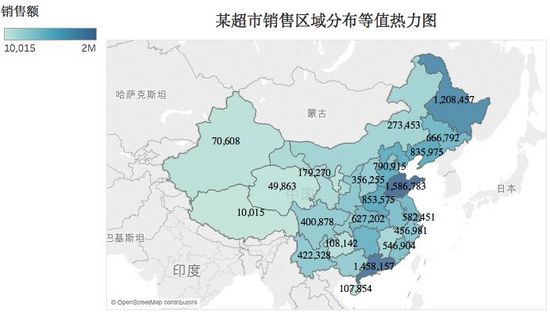
空间数据探索主要是期望展现或者发现业务事件在地域分布上的规律,即区域模式。全球数据通常按照国家分类,而国内数据则按照省份去分类,对于省份数据则按照市、区分类,以此类推,逐步向细分层次下钻。空间数据探索最常用为等值热力图,如下:
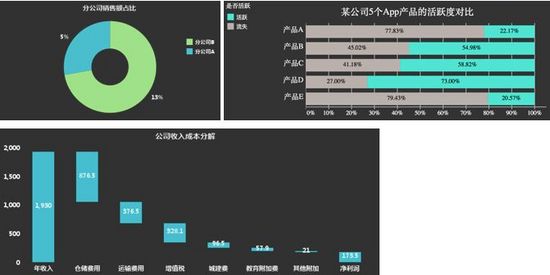
4. 多元变量的探索
数据探索过程中,有时候我们需要对比多个个体多个变量,从而寻找数据个体间的差异或者数据变量间的关系。在这种情况下,我们推荐使用散点图、气泡图,或者将多个简单图表组合生成“图矩阵”,通过对比“图矩阵”来进行多元变量的探索。其中,散点图和气泡图适合变量相对较少的场景,对于变量5个及以上的场景我们更多地是推荐“图矩阵”。
a. 变量相对较少(5个以下)的场景我们采用散点图与气泡图。

b. 变量多(5个及以上)的场景我们采用多个简单图表组成的“图矩阵”,下图为最简单的“图矩阵”多元热力图:
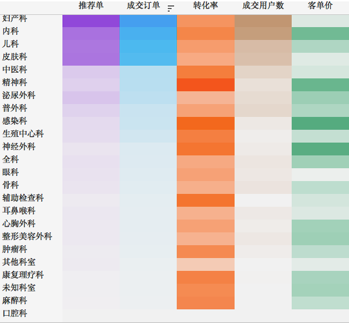
5. 数据分布的探索
探索数据的分布,能帮助我们了解数据的整体的区间分布、峰值以及谷值以及数据是否稳定等等。
之前在分类数据探索阶段曾提到分类清晰的条形图在一定程度上向我们反映了数据的分布信息。但,之前我们是对类别做的条形图,更多时候我们是需查看数据“坐落区间”,这里我们推荐直方图以及直方图的变型密度曲线图(密度曲线图,上学时代学的正态分布就常用密度曲线图绘制)。此外,对数据分布探索有一个更为科学的图表类型,那就是:箱线图。
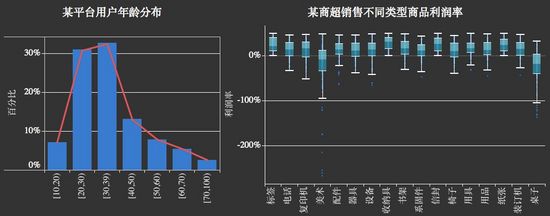
三、图表清晰
1. 合理"搭配"可视化的组件
所谓可视化,其实就是根据数据,用标尺、坐标系、各种视觉暗示以及背景信息描述进行组合来表现数据。下图为可视化组件的“框架图”:
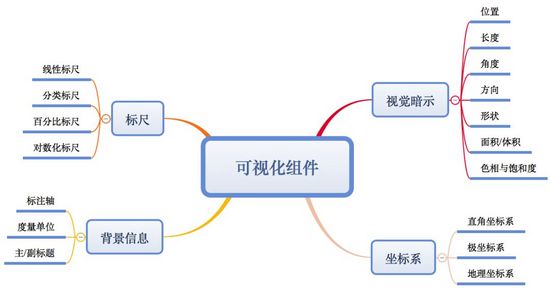
a. 视觉暗示
可视化最基本的形式就是简单地将数据映射成图形,大脑可以在数字与图形间来回切换从而寻找模式。所以我们必须选择合适的视觉暗示来保证数据的本质没有在大脑地来回切换中丢失,并且尽可能让大脑能轻松获得信息。

从上到下,对人脑而言视觉暗示清晰程度逐渐降低。
位置
使用位置作视觉暗示时,大脑是在比较给定空间或者坐标系中数值的位置。它的优势在于占用空间会少于其他视觉暗示,但劣势也很明显,我们很难去辨别每一个点代表什么。所以,应用位置作为视觉暗示主要用于发现趋势规律或者群集分布规律,散点图是位置作为视觉暗示的典型运用。
长度
使用长度作为视觉暗示,大脑的理解模式是条形越长,绝对值越大。优点非常明显人眼对于长度的“感受”往往是最准确的。条形图是长度作为视觉暗示的最常见图表。
角度
使用角度作为视觉暗示,大脑的理解模式为两向量如何相交,相交角度是否大于90度或180度。角度作为视觉暗示的最常见图表式饼图。
方向
使用方向作为视觉暗示,大脑的理解模式为坐标系中一个向量的方向。在折线图中显示为斜率,在迁徙图中显示为箭头所指方向。
形状
使用形状作为视觉暗示,对大脑而言往往代表着不同的对象或者类别。可用于在散点图中区分不同群集。
面积/体积
使用面积/体积作为视觉暗示,面积大则绝对值大。需要注意的一点是,用面积显示2倍关系时,应该是面积乘倍而不是边长乘倍。
色相与饱和度
不同的颜色通常用来表示分类数据,每个颜色代表一个分组;不同的色相通畅用来表示连续数据,常见模式是颜色越深代表数值越大。
b. 坐标系
- 直角坐标系:绝大多数的图表都在直角坐标系中完成,它是最常用的坐标系。在直角坐标系中,关注的两个点之间的距离,距离是欧式距离。
- 极坐标系:极坐标系是显示角度的坐标系,如果用过饼图那么就已经接触过极坐标系了。
- 地理坐标系:简单点理解,它由经纬度组成,将世界各地的位置显示在图表中,因与现实世界直接相关而倍受喜爱。
c. 标尺
标尺的重要性在于与坐标系一起决定了图形的投影方式。
- 线性标尺:间距处处相等,无论处于什么位置,是大众最熟悉、最容易接受的标尺,不容易产生误解;
- 分类标尺:分类数据往往采用分类标尺,如:年龄段、性别、学历等等,值得注意的一点是,对于有序的分类,我们应尽量对分类标尺做排序以适应读者的阅读模式;
- 百分比标尺:其实仍旧是线性标尺,只是刻度值为百分比;
- 对数标尺:指按照对数化将坐标轴压缩,适合数值跨度非常大的场景。但需考虑读者是否能够适应对数标尺,毕竟它并不常见。
d. 背景信息
背景信息,所指即我们在理解 DATA 通过 “5W1H” 法回答的问题。包括数据背景与业务背景。
基本的原则是,如果信息在图形元素中没有得到巧妙地暗示,我们久需要通过标注坐标轴、注明度量单位,添加额外说明等方法来告诉读者图表中每一个数据及其视觉暗示代表什么。
2. 美化,让可视化更为清晰
在研究阶段,我们重点尝试从各种不同的角度切入去观察数据,没有过多地考虑表达是否准确,图形是否美观。
但,当我们进展到准备将分析报告呈现给业务方或领导时,必须对可视化图表进行优化使其是清晰易读的。否则,我们很可能要挨批了。
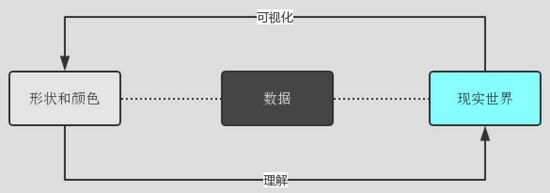
上图为,数据可视化与现实世界的连接关系。清晰易读的可视化一定是在尽可能地减少读者从可视化图表理解转换为现实世界的难度。而增强数据比较、合理注解引导、减少读者理解步骤是达成这一目的的良好手段,下面为大家详细展开介绍:
a. 增强数据比较,降低大脑进行信息比较的难度
当我们在阅读可视化图表时,我们的大脑会自然地进行比较从而获取信息。增强数据比较,可有效降低信息比较难度,使大脑更容易抓住关键信息,减少模凌两可,使大脑获取信息更具确定性。
建立视觉层次,用醒目的颜色突出数据,淡化其他元素
有层次感的图表更易读,用户能更快地抓住图表中的重点信息。相反,扁平图则缺少流动感,读者相对较难理解。建立视觉层次,我们可以用醒目的颜色突出显示数据,并淡化其他元素使其作为背景,淡化元素可采用淡色系或虚线。
散点图的目标是为寻找规律与模式,拟合数据线是下图的关键。弱化数据点、强化拟合趋势线使其形成鲜明的2个层次。
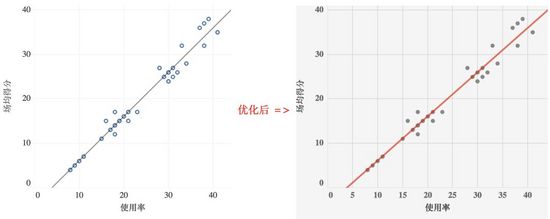
高亮显示重点内容
高亮显示可以帮助读者在茫茫数据中一下找到重点。它既可以加深人们对已看到数据的印象,也可以让人们关注到那些应该注意的东西。需要注意的是,使用“高亮”突出显示时,我们应尽可能使用当前图表中尚未使用的视觉暗示。
下面为常见的电商转化漏斗,其中下单步骤是最应当关注的环节,使用红色高亮能会使读者的目光快速落在这一关键步骤中。
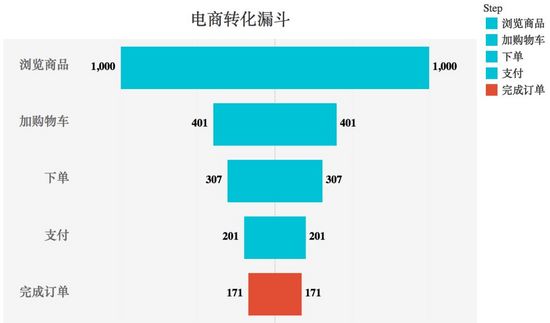
其他技巧
除了以上介绍两大增强比较技巧,我们可以通过以下一些小技巧来增强数据比较:
- 提升色阶跨度,倘若图表中所用颜色色阶跨度太小,我们将难以区分差异,合理提升色阶跨度能有效增强比较;
- 合理增大标尺跨度,有时候我们只需要对标尺做合理地放大,数据差异将清晰好几倍;
- 添加参考线(建议采用虚线),参考线作为对比基准,可有效增强数值与基准的比较。
b. 合理注解与引导,使读者快速理解图表信息并抓住信息重点
仅通过图形元素,我们很难向读者展示充分的信息,合理增加注解能有效帮助读者理解图表;增加适当的箭头等符号引导能帮助读者快速抓住关键信息。
合理注解:背景信息、分析结论以及统计学概念
- 如果报表的读者对数据、业务背景并不十分熟悉,我们应考虑在标题或其他报告文字中直接说明背景。
- 如果是结论性图表,我们可在主标题中直接说明结论。如果结论得出的过程较复杂,我们还可以在副标题中辅助说明是如何推导得到的结论。
- 如果图表中,有大部分读者都不熟悉的统计学概念,我们应适当地进行注解,以帮助读者了解相关概念。
下图,主标题数据背景注解让读者快速了解业务背景,副标题说明结论能有效引导读者朝着什么方向去阅读图表
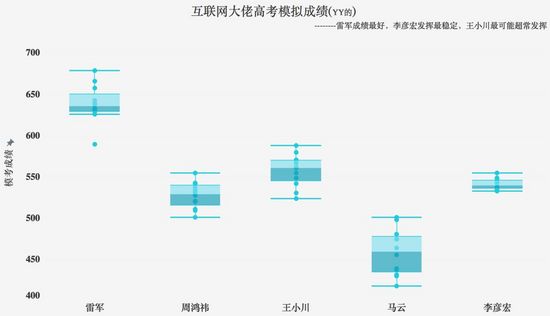
合理增加引导:增加适当的箭头指向
分析阶段,我们是报表的制作者;汇报阶段,我们是报告的讲解者。我们可以将自身作为报告的导游,引导读者按照我们的期望去阅读图表。而增加箭头等符号的引导是最直接有效的方式。
c. 通过引入计算、视觉暗示直接符合读者“背景暗示”等方法可有效降低读者理解步骤
创造性地从不同角度进行计算
有时,我们只需在图表上先做一个图表计算就可以让图表离结论更近一个层次,从而减少读者从可视化图表到现实世界的理解步骤。常见的可用计算包括:平均值计算、环比增长率、基准点上下、累加统计等。
示例1:将员工销售业绩与团队均值做差值,快速辨别员工的销售表现
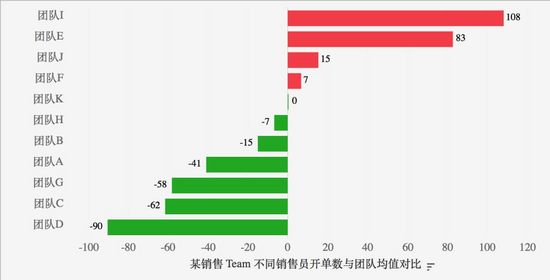
示例2:将2个采购商的采购成本按照一年累计汇总后可使采购成本差异更显著
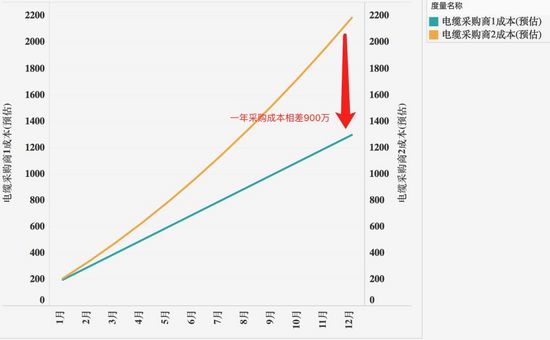
选择符合读者“背景期望”的视觉暗示
人在世界上生存久了都会形成一定的潜意识,有一些潜意识是“人群通用的”,在可视化过程中,我们应该合理运用。比如:在失业、就业统计中,失业用负数表示,就业用正数表示,就是一种符合大多数人“背景期望”的一种场景。
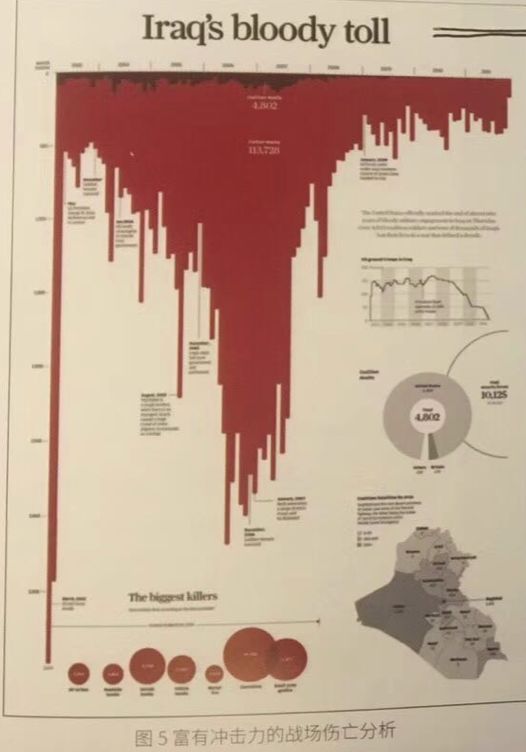
示例1: 之前在一本书中看到的一个关于伊拉克战争可视化。此图的主题在于批判战争的残酷造成了巨大的伤亡,所以作者采用了与血液相同的红色作为主色调,倒挂的柱形也能给人以压抑感,同样符合“背景期望”。
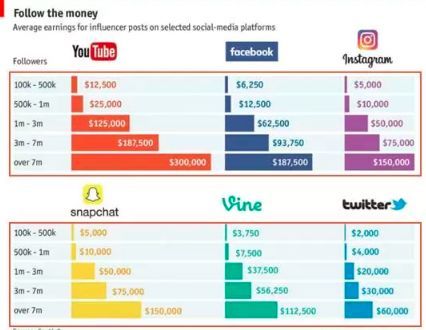
示例2: 之前一位同事分享的一个关于美国一些互联网平台网红收入的可视化。在色彩上它直接采用对应互联网平台自身logo的色系。符合人的“背景期望”阅读过程将非常轻松。
四、适应读者
别忘了,我们的可视化是为读者进行的,我们应考虑目标读者的特点制作他们易于、乐于理解的可视化。尤其要避免的一个陷阱是:过分追求新颖图表,反而使得图表难以理解,结果违背了可视化的初衷。
为读者而可视化,要求我们试图去了解读者,了解他们对可视化的偏好,尤其是能够接受新颖的图表类型,以及他们对业务的理解程度等等。
此外,还有一个非常关键且通用的建议:让我们的报告以讲故事的方式展开,我们自身则作为这个报告的导游,合理有效地引导读者看完你创造的“分析故事”。
好,以上即为个人对数据可视化服务商业分析的过程所有总结。
以上是关于数据可视化过程不完全指南的主要内容,如果未能解决你的问题,请参考以下文章