mysql如何去除两个字段数据相同的记录
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql如何去除两个字段数据相同的记录相关的知识,希望对你有一定的参考价值。
方法有很多,这里介绍两种
方法一、
如果要保留id的最小值,例如:
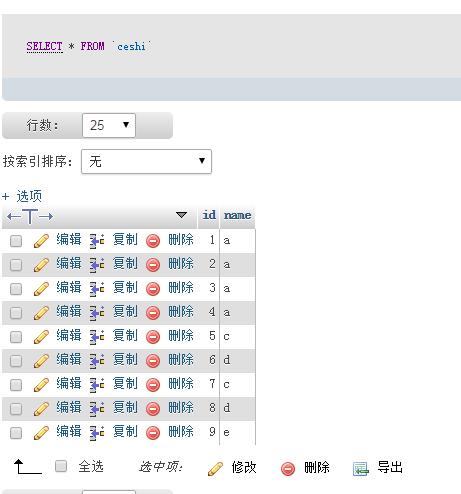
数据:
执行sql:select count(*) as count ,name,id from ceshi group by name
<img
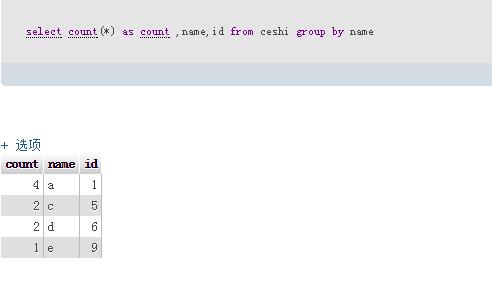
最后要删除的sql为:delete from ceshi where id not in (select count(*) as count ,name,id from ceshi group by name)
如果想保留id的最大值:
简单的办法是:delete from ceshi where id not in (select count(*) as count ,name,id from (select * from ceshi order by id desc) group by name)
如果想要删除的是两个列里面对应相同的数据,也就是说表里面有两条记录的name都是admin,要是只想保留其中一条的话,order by 的时候增加一个值即可,例如:
delete from ceshi where id not in (select count(*) as count ,name,id from ceshi group by name,email)
方法二、
只需要把你这张表当成两张表来处理就行了。
DELETE p1 from TABLE p1, TABLE p2 WHERE p1.name = p2.name AND p1.email = p2.email AND p1.id < p2.id;
这里有个问题,保留最新的那一条(也就是ID最小的那个)
上面的的语句,p1.id < p2.id,所以获取到的是id最大的,因为p1.id小于p2.id就会被删除,只有最大的值不满足。如果要获取id最小的那个,只需要把'<'改成'>'即可。
当然是用group by,count可以更精准控制重复n次的情况。
参考技术A想要去除两个字段数据相同的记录只需要把把这张表当成两张表来处理:
下面的的语句,p1.id < p2.id,所以获取到的是id最大的,因为p1.id小于p2.id就会被删除,只有最大的值不满足。如果要获取id最小的那个,只需要把'<'改成'>'即可。
DELETE p1 from TABLE p1, TABLE p2 WHERE p1.name = p2.name AND p1.email = p2.email AND p1.id < p2.id;如果需求是只要把重复的删掉,保留最新的就行可以使用上面的语句。
如果需要稍微复杂,可以用group by,count精准控制重复n次的情况。
参考技术B mysql查询重复字段,及删除重复记录的方法数据库中有个大表,需要查找其中的名字有重复的记录id,以便比较。如果仅仅是查找数据库中name不重复的字段,很容易:
SELECT min(`id`),`name` FROM `table` GROUP BY `name`;
但是这样并不能得到说有重复字段的id值。(只得到了最小的一个id值)查询哪些字段是重复的也容易:
SELECT `name`,count(`name`) as count FROM `table` GROUP BY `name` HAVING count(`name`) >1 ORDER BY count DESC;
但是要一次查询到重复字段的id值,就必须使用子查询了,于是使用下面的语句。
SELECT `id`,`name` FROM `table` WHERE `name` in (
SELECT `name`
FROM `table`
GROUP BY `name` HAVING count(`name`) >1);
但是这条语句在mysql中效率太差,感觉mysql并没有为子查询生成零时表。于是使用先建立零时表:
create table `tmptable` as (
SELECT `name`
FROM `table`
GROUP BY `name` HAVING count(`name`) >1);
然后使用多表连接查询:
SELECT a.`id`, a.`name` FROM `table` a, `tmptable` t WHERE a.`name` = t.`name`;
结果这次结果很快就出来了。
========================
查询及删除重复记录的方法
(一)
1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断
select * from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录
delete from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)
3、查找表中多余的重复记录(多个字段)
select * from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录
delete from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录
select * from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)本回答被提问者采纳 参考技术C
假设你的表名是mytable,可能含有相同数据的字段是numA和numB,那么删除两个字段数据相同的记录方法为:
1.查询具有相同数据的记录
2.进行删除
随便贴一个
sql - How can I remove duplicate rows?
稍微讲一下其中一个思路(里面有很多很好的答案 你可以自己去看)
就是做一个group by 保留其中id 最大的(你说自增长 id最大的应该就是最新的)就可以了
具体sql query 可以这样写
delete from test where id not in(
select name,email,max(id) from test
group by name,email having id is not null)
以上是关于mysql如何去除两个字段数据相同的记录的主要内容,如果未能解决你的问题,请参考以下文章