kafka初识
Posted liclblog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka初识相关的知识,希望对你有一定的参考价值。
参考来自Kafka入门实战pdf
1.kafka的基本概念
1.主题:
Kafka 将一组消息抽象归纳为一个主题(Topic),也就是说,一个主题就是对消息的一个 分类。生产者将消息发送到特定主题,消费者订阅主题或主题的某些分区进行消费。
2.消息:
消息是 Kafka 通信的基本单位,由一个固定长度的消息头和一个可变长度的消息体构成。 在老版本中,每一条消息称为 Message:在由 Java 重新实现的客户端中,每一条消息称为 Record。
3. 分区和副本:
Kafka 将一组消息归纳为一个主题,而每个主题又被分成一个或多个分区(Partition)。 每 个分区由一系列有序、不可变的消息组成,是一个有序队列。 每个分区在物理上对应为一个文件夹,分区的命名规则为主题名称后接“一”连接符,之 后再接分区编号,分区编号从 0 开始,编号最大值为分区的总数减 l。 每个分区又有一至多个 副本(Replica),分区的副本分布在集群的不同代理上,以提高可用性。 从存储角度上分析, 分区的每个副本在逻辑上抽象为一个日志(Log)对象,即分区的副本与日志对象是一一对应 的。 每个主题对应的分区数可以在 Kafka 启动时所加载的配置文件中配置,也可以在创建主题 时指定。当然,客户端还可以在主题创建后修改主题的分区数。 分区使得 Kafka 在井发处理上变得更加容易,理论上来说,分区数越多吞吐量越高,但这 要根据集群实际环境及业务场景而定。同时,分区也是 Kafka 保证消息被顺序消费以及对消息 进行负载均衡的基础。 Kafka 只能保证一个分区之内消息的有序性,并不能保证跨分区消息的有序性。 每条消息 被追加到相应的分区中,是顺序写磁盘,因此效率非常高,这是 Kafka 高吞吐率的一个重要保 证。同时与传统消息系统不同的是, Kafka 并不会立即删除已被消费的消息,由于磁盘的限制 消息也不会一直被存储(事实上这也是没有必要的),因此 Kafka 提供两种删除老数据的策略, 一是基于消息己存储的时间长度, 二是基于分区的大小。这两种策略都能通过配置文件进行配 置.(关于更多分区,主题的概念请参考https://blog.csdn.net/zwgdft/article/details/54633105 这篇博客)
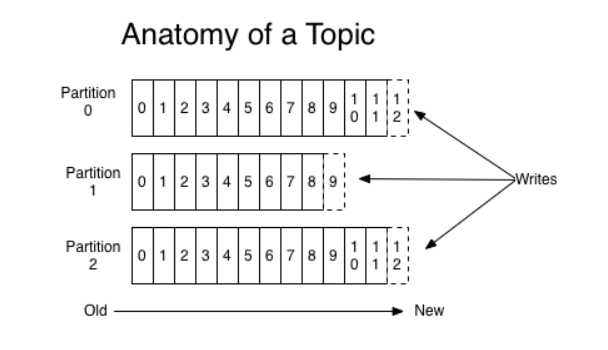 官网结构图
官网结构图
4. Leader 副本和 Follower 副本
由于 Kafka 副本的存在,就需要保证一个分区的多个副本之间数据的一致性, Kafka 会选 择该分区的一个副本作为 Leader 副本,而该分区其他副本即为 Follower 副本,只有 Leader 副 本才负责处理客户端读/写请求, Follower 副本从 Leader 副本同步数据。 如果没有 Leader 副本, 那就需要所有的副本都同时负责读/写请求处理,同时还得保证这些副本之间数据的一致性,假 设有 n 个副本则需要有 n×n 条通路来同步数据,这样数据的一致性和有序性就很难保证。 引入 Leader 副本后客户端只需与 Leader 副本进行交互,这样数据一致性及顺序性就有了 保证。 Follower 副本从 Leader 副本同步消息,对于 n 个副本只需 n-1 条通路即可,这样就使得 系统更加简单而高效。副本 Follower 与 Leader 的角色并不是固定不变的,如果 Leader 失效, 通过相应的选举算法将从其他 Follower 副本中选出新的 Leader 副本。
5. 偏移量
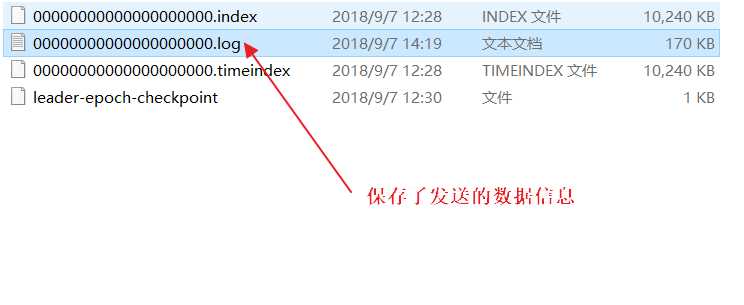
任何发布到分区的消息会被直接追加到日志文件(分区目录下以" .log”为文件名后缀的 数据文件〉的尾部,而每条消息在日志文件中的位置都会对应一个按序递增的偏移量。偏移量
是一个分区下严格有序的逻辑值,它并不表示消息在磁盘上的物理位置。 由于 Kafka 几乎不允 许对消息进行随机读写,因此 Kafka 并没有提供额外索引机制到存储偏移量,也就是说并不会 给偏移量再提供索引。消费者可以通过控制消息偏移量来对消息进行消费,如消费者可以指定 消费的起始偏移量。为了保证消息被顺序消费, 消费者己消费的消息对应的偏移量也需要保存。 需要说明的是,消费者对消息偏移量的操作并不会影响消息本身的偏移量。 旧版消费者将消费 偏移量保存到 ZooKeeper 当中,而新版消费者是将消费偏移量保存到 Kafka 内部一个主题当中。 当然,消费者也可以自己在外部系统保存消费偏移量,而无需保存到 Kafka 中。(上图.log文件)
6. 日志段
一个日志又被划分为多个日志段(LogSegment),日志段是 Kafka 日志对象分片的最小单 位。与 日志对象一样,日志段也是一个逻辑概念, 一个日志段对应磁盘上一个具体日志文件和 两个索引文件。日志文件是以 “.log”为文件名后缀的数据文件,用于保存消息实际数据。 两 个索引文件分别以“.index”和“.timeindex”作为文件名后缀,分别表示消息偏移量索引文件 和消息时间戳索引文件。
进入到自己的kafka日志文件夹下
7. 代理
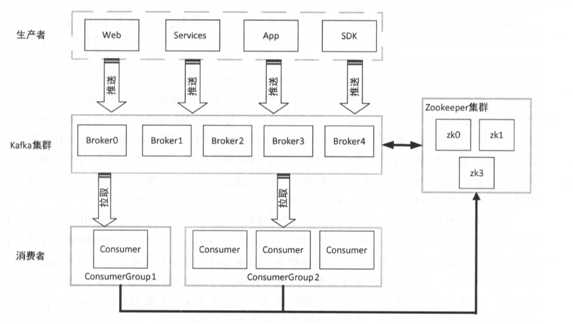
在 Kafka 基本体系结构中我们提到了 Kafka 集群。 Kafka 集群就是由一个或多个 Kafka 实 例构成,我们将每一个 Kafka 实例称为代理( Broker ),通常也称代理为 Kafka 服务器 ( KafkaServer)。在生产环境中 Kafka 集群一般包括一台或多台服务器,我们可以在一台服务器 上配置一个或多个代理。每一个代理都有唯一的标识 id,这个 id 是一个非负整数。在一个 Kafka 集群中,每增加一个代理就需要为这个代理配置一个与该集群中其他代理不同的 id, id 值可以 选择任意非负整数即可,只要保证它在整个 Kafka 集群中唯一,这个 id 就是代理的名字,也就 是在启动代理时配置的 broker.id 对应的值,因此在本书中有时我们也称为 brokerId。 由于给每 个代理分配了不同的 brokerId,这样对代理进行迁移就变得更方便,从而对消费者来说是透明 的, 不会影响消费者对消息的消费。代理有很多个参数配置,后续说明。
8. 生产者
生产者(Producer)负责将消息发送给代理,也就是向 Kafka 代理发送消息的客户端。
9. 消费者和消费纽
消费者(Comsumer)以拉取(pull)方式拉取数据,它是消费的客户端。在 Kafka 中每一 个消费者都属于一个特定消费组(ConsumerGroup),我们可以为每个消费者指定一个消费组, 以 groupld 代表消费组名称,通过 group.id 配置设置。 如果不指定消费组,则该消费者属于默 认消费组 test-consumer-group。 同时,每个消费者也有一个全局唯一的 id, 通过配置项 client.id 指定,如果客户端没有指定消费者的 id, Kafka 会自动为该消费者生成一个全局唯一的 id,格 式为${groupld }-$ {hostN ame }-$ {times tamp}-$ {UUID 前 8 位字符}。同一个主题的一条消息只能
~ .3 Kafka 基本概念 5
被同一个消费组下某一个消费者消费,但不同消费组的消费者可同时消费该消息。 消费组是 Kafka 用来实现对一个主题消息进行广播和单播的手段,实现消息广播只需指定各消费者均属于不同 的消费组,消息单播则只需让各消费者属于同一个消费组。
10. ISR Kafka 在 ZooKeeper 中动态维护了一个 ISR (In-sync Replica),即保存同步的副本列表, 该 列表中保存的是与 Leader 副本保持消息同步的所有副本对应的代理节点 id。 如果一个 Follower 副本岩机(本书用岩机来特指某个代理失效的情景,包括但不限于代理被关闭,如代理被人为 关闭或是发生物理故障、心跳检测过期、网络延迟、进程崩溃等)或是落后太多,则该 Follower 副本节点将从 ISR 列表中移除。
11. ZooKeeper
这里我们并不打算介绍 ZooKeeper 的相关知识,只是简要介绍 ZooKeeper 在 Kafka 中的作 用。 Kafka 利用 ZooKeeper 保存相应元数据信息, Kafka 元数据信息包括如代理节点信息、 Kafka 集群信息、旧版消费者信息及其消费偏移量信息、主题信息、分区状态信息、分区副本分配方 案信息、动态配置信息等。 Kafka 在启动或运行过程当中会在 ZooKeeper 上创建相应节点来保 存元数据信息, Kafka 通过监昕机制在这些节点注册相应监听器来监昕节点元数据的变化,从 而由 ZooKeeper 负责管理维护 Kafka 集群,同时通过 ZooKeeper 我们能够很方便地对 Kafka 集 群进行水平扩展及数据迁移。 通过以上 Kafka 基本概念的介绍,我们可以对 Kafka 基本结构图进行完善。
以上是关于kafka初识的主要内容,如果未能解决你的问题,请参考以下文章