常用数据结构
Posted thelovelybugfly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常用数据结构相关的知识,希望对你有一定的参考价值。
数据结构:
数据结构是计算机存储, 组织数据的一种方式,是指一种或多种特定关系的数据元素的集合。
集合:
数据结构间除了 同属于一个集合 的相互属性之外 , 别无其他关系。
线性结构:
数据结构中元素存在一对一的相互关系。
树形结构:
数据结构中元素存在一对多的相互关系。
图形结构:
数据结中的元素存在多对多的相互关系。
常用的数据结构:
数组,栈,队列,链表,树,图,堆,散列表。
数组:
数组是在内存中开辟一块连续的存储空间,并在此空间存放元素,像是一节火车, 有10个车厢,从01到10 有固定的编号,通过编号可以快速找到这节车厢。
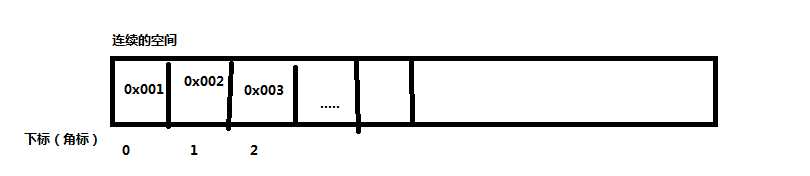
数组的特点:
元素类型固定,长度固定,通过脚标查询,所以查询快,增删慢。
栈 :
线性结构。顺序进出,只有一个出口,按进出顺序进行出入
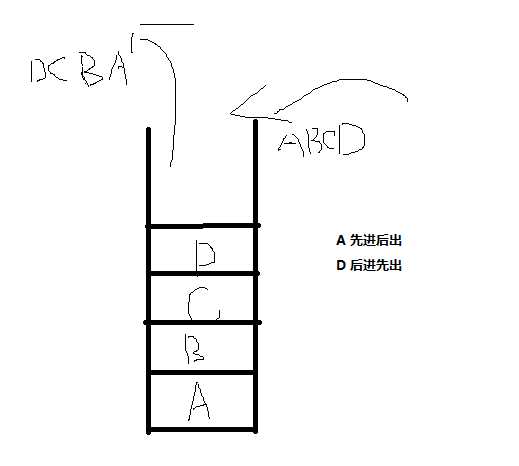
如果要删除某个元素,只能从出口端,一个一个的顺序删除,同理,增加也是 。只能通过入口端顺序的添加进去, 其底层就是LinkedList去实现的。
链表:
链表是一种物理存储单元上不连续,无顺序的存储结构。数据元素的逻辑顺序是根据链表中的指针链接次序实现的。链表由一系列结点组成,结点在运行时动态的生成的。
链表大致可分为:单链表,双链表和有序链表。
可以这样理解: 链表中的地址,是通过别的结点中获取的, 比如A结点,有B结点的地址,B 结点有C 结点的地址,要想找C 结点的地址,就寻找B来获取C 的地址,那么ABC 的关系就构成一个链表。
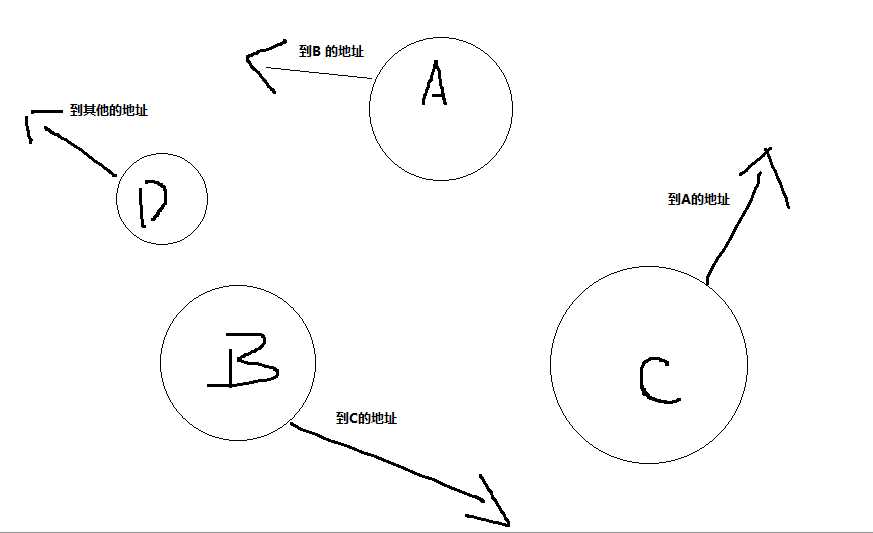
单链表:
就是A 有且只有B 的地址,B 有且只有C 的地址,这样的类型。
双链表:
就是A 有B 的地址,还有D 的地址。有两个元素的地址。
循环链表:
就是A 有B 的地址, B 有C 的地址,C 有A 的地址, 这样构成一个循环。
有序链表:
以某种顺序给链表的元素排序,比如按照内容大小,哈希值等等。
相比于数组来说:
链表好处: 链表不需要确定大小,存储空间也不需要是连续的。
链表缺点: 由于不是连续存储的空间,所以查找元素比较麻烦吃力;相比于数组只存储元素,链表的元素不仅要存储元素,还要存储其他元素的地址。相对的内存开销变大。
二叉树:
在计算机科学中,二叉树是每个结点最多有两个子树的树结构。顶上的叫根节点。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆
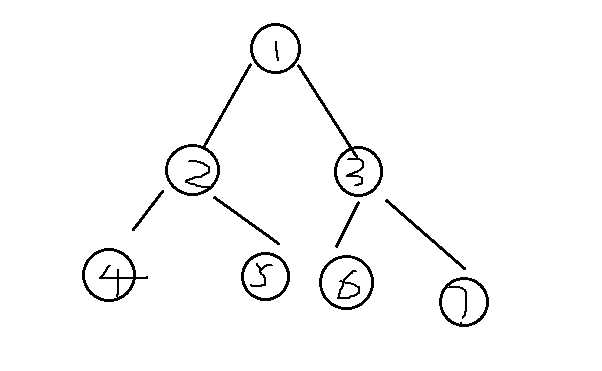
遍历是对树的最基本的运算,所谓遍历二叉树,就是按照一定的规则和属性走便二叉树的所有节点,使每一个节点都被访问一次,而且只被访问一次。由于二叉树是非线性结构,所以,树的遍历实际上是将二叉树的各个结点转换为一个线性序列来表示。
二叉树的遍历分为四种 : 分别是 前序遍历,中序遍历,后序遍历,按层遍历。
按上图说示为例:
前序遍历:根-->左-->右 1-->2--4--5--3--6--7
中序遍历:左-->根-->右 4-->2--5--1--6--3--7
后序遍历:左-->右-->根 4-->2--5--6--7--3--1
按层遍历:从上到下,从左到右(1-->2-->3-->4-->5-->6-->7)
二叉树和树的区别:
二叉树,顾名思义就是有每个节点有且最多只有两个分支。可以有一个分支,但是树 则没有,树的节点可以有不确定多个分支。
二叉树的节点有左右之分,树的节点没有左右之分。
散列表(哈希表):
百度百科上这样解释哈希表:
记录的存储位置=f(关键字)
这里的对应关系f称为散列函数,又称为哈希(Hash函数),采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。
哈希表hashtable(key,value) 就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。(或者:把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。)
而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位。
数组的特点是:寻址容易,插入和删除困难;
而链表的特点是:寻址困难,插入和删除容易。
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们提起的哈希表。
PO 一下 看到的大佬总结的
Hash的应用
1、Hash主要用于信息安全领域中加密算法,它把一些不同长度的信息转化成杂乱的128位的编码,这些编码值叫做Hash值. 也可以说,Hash就是找到一种数据内容和数据存放地址之间的映射关系。
2、查找:哈希表,又称为散列,是一种更加快捷的查找技术。我们之前的查找,都是这样一种思路:集合中拿出来一个元素,看看是否与我们要找的相等,如果不等,缩小范围,继续查找。而哈希表是完全另外一种思路:当我知道key值以后,我就可以直接计算出这个元素在集合中的位置,根本不需要一次又一次的查找!
举一个例子,假如我的数组A中,第i个元素里面装的key就是i,那么数字3肯定是在第3个位置,数字10肯定是在第10个位置。哈希表就是利用利用这种基本的思想,建立一个从key到位置的函数,然后进行直接计算查找。
3、Hash表在海量数据处理中有着广泛应用。
Hash Table的查询速度非常的快,几乎是O(1)的时间复杂度。
hash就是找到一种数据内容和数据存放地址之间的映射关系。
散列法:元素特征转变为数组下标的方法。
我想大家都在想一个很严重的问题:“如果两个字符串在哈希表中对应的位置相同怎么办?”,毕竟一个数组容量是有限的,这种可能性很大。解决该问题的方法很多,我首先想到的就是用“链表”。我遇到的很多算法都可以转化成链表来解决,只要在哈希表的每个入口挂一个链表,保存所有对应的字符串就OK了。
散列表的查找步骤
当存储记录时,通过散列函数计算出记录的散列地址
当查找记录时,我们通过同样的是散列函数计算记录的散列地址,并按此散列地址访问该记录
关键字——散列函数(哈希函数)——散列地址
优点:一对一的查找效率很高;
缺点:一个关键字可能对应多个散列地址;需要查找一个范围时,效果不好。
散列冲突:不同的关键字经过散列函数的计算得到了相同的散列地址。
好的散列函数=计算简单+分布均匀(计算得到的散列地址分布均匀)
哈希表是种数据结构,它可以提供快速的插入操作和查找操作。
优缺点
优点:不论哈希表中有多少数据,查找、插入、删除(有时包括删除)只需要接近常量的时间即0(1)的时间级。实际上,这只需要几条机器指令。
哈希表运算得非常快,在计算机程序中,如果需要在一秒种内查找上千条记录通常使用哈希表(例如拼写检查器)哈希表的速度明显比树快,树的操作通常需要O(N)的时间级。哈希表不仅速度快,编程实现也相对容易。
如果不需要有序遍历数据,并且可以提前预测数据量的大小。那么哈希表在速度和易用性方面是无与伦比的。
缺点:它是基于数组的,数组创建后难于扩展,某些哈希表被基本填满时,性能下降得非常严重,所以程序员必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的哈希表中,这是个费时的过程)。
以上是关于常用数据结构的主要内容,如果未能解决你的问题,请参考以下文章