数据分析笔试
Posted luban
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析笔试相关的知识,希望对你有一定的参考价值。
1、KMO值在( )范围内,因子分析才是有效的。
解答:kmo检验统计量是用于比较变量间简单相关系数和偏相关系数的指标,主要用于多元统计的因子分析。当所有变量的简单相关系数的平方和远远大于偏相关系数的平方和时,kmo值越接近于1,原有变量越适合做因子分析。0.7-0.8适合,0.8-0.9很适合,0.9-1非常适合。0.6-0.7不太适合,0.5-0.6勉强适合,小于0.5不适合。BartlettP值小于或者等于0.01适合。
2、数据分析的方法包含( )、( )、( )等。
解答:描述性统计,回归分析。方差分析,假设检验。
选择题。较为简单
简答题。
1、某网站7月份共访问用户数4100人,已知访问网站有两种登陆方式A 和B 。使用A登陆的7月份总用户数为2835,使用B方式登陆的7月份总用户数为1400,既使用过A又使用过B登陆的7月份总用户数为985.
问:可以看出,总访问数—使用A登陆方式的总用户数=1265,那么A与B的重复用户数=B登陆用户数—1265=135,而实际得到的既使用A登陆方式又使用B登录方式的7月份总用户数为985,显然这是矛盾的,问题出在哪里?给出计算方法。
2、新浪公司楼下有一便利店,35平米,收银员2位,每天提供早餐、中餐、晚餐。如果你来做估算,计算每天的营业额是多少?
3、抽样估计的优良标准。
解答:无偏性,一致性,有效性。
4、写出相关和回归分析的内容。
解答:相关分析是对两个变量之间线性关系的描述和度量。
回归分析侧重于考察变量之间的数量伴随关系。
5、一道关于产品成本降低率和销售利润的直线回归分析的题目,记不清了。
2012新浪校园招聘数据分析师职位笔试题目。A卷(数据挖掘方向)
1、输入两个整数n 和m ,从数列1、2、3....n中随意取几个数,使其等于m,将其所有可能的组合列出来,如果考虑递归算法,请将算法的思路或者伪码写出来即可,求解思路:
2、有100个人做5道题目,第一道题目做的人有55人,第二道做对的人有89人,第三道作对的人有97人,第四道作对的人有79人,第五道作对的人有46人,已知至少作对三道才是过关,问至少多少人过关?(提供的数字我已经记不清了就随便写的几个)
3、证明根号2是无理数。
4、聚类分析方法对变量之间多重共线性的影响。
5、新浪公司楼下有一便利店,35平米,收银员2位,每天提供早餐、中餐、晚餐。如果你来做估算,计算每天的营业额是多少?
1.平均数,中位数,众树,方差,标准差的含义,并举例子解释。
2.你心目中的数据分析师是什么样的?
3.两个水桶,一个小点的桶可以装4升水,大的桶装11升水,问怎么操作可以两个桶盛5升水?
4.数据分布有哪些?选择熟悉的数据分布并写出其适用的场景。
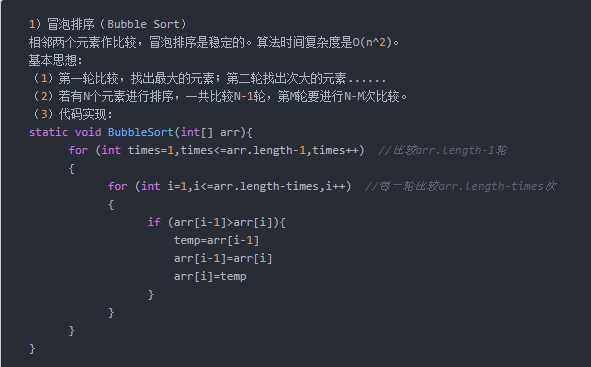
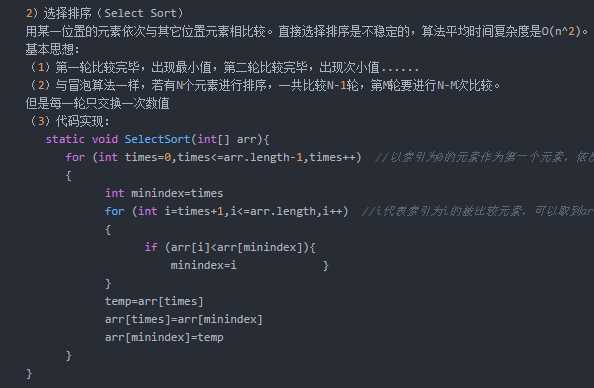
5.写出三种熟悉的排序算法,选择一个写出其伪代码。
6.Hadoop生态系统组件有哪些?写出你熟悉的三个。
7.什么是幸存者偏差?
8.写出10种linux命令,写出其参数。
9.用一种编程语言,实现1+2+3+4+5+.....+100
10.实现求1,2,3,...100之间的质数。
11.给几个表,mysql语言编写。(时间来不及,就没有写,挺复杂的)
12.给了三个图表,全是英文的,对其做分析。
最小化误差是为了让我们的模型拟合我们的训练数据,而规则化参数是防止我们的模型过分拟合我们的训练数据,提高泛化能力。
1)准确率(precision rate):TP/(TP+FP)
2)召回率(recall rate):TP/(TP+FN)
-
对于不平衡类的分类器评价,使用ROC和AUC作为评价分类器的指标
3)ROC曲线:
ROC关注两个指标- True Positive Rate ( TPR,真正率 ) = TP / [ TP + FN] ,TPR与召回率大小相等。
- False Positive Rate( FPR,假正率 ) = FP / [ FP + TN] ,
在ROC 空间中,每个点的横坐标是FPR,纵坐标是TPR
4)AUC值:AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而AUC作为数值可以直观的评价分类器的好坏,值越大越好。
过拟合表现在训练数据上的误差非常小,而在测试数据上误差反而增大。其原因一般是模型过于复杂,过分得去拟合数据的噪声和outliers。
常见的解决办法是正则化是:增大数据集,正则化
L1正则与L2正则区别:
L1:计算绝对值之和,用以产生稀疏性(使参数矩阵中大部分元素变为0),因为它是L0范式的一个最优凸近似,容易优化求解;
L2:计算平方和再开根号,L2范数更多是防止过拟合,并且让优化求解变得稳定很快速;
所以优先使用L2 norm是比较好的选择。
链接:https://www.jianshu.com/p/a64aa70d0fbc
以上是关于数据分析笔试的主要内容,如果未能解决你的问题,请参考以下文章