五种回归方法的比较
Posted jin-liang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了五种回归方法的比较相关的知识,希望对你有一定的参考价值。
引言
线性和逻辑回归通常是人们为机器学习和数据科学学习的第一个建模算法。 两者都很棒,因为它们易于使用和解释。 然而,它们固有的简单性也有一些缺点,在许多情况下它们并不是回归模型的最佳选择。 实际上有几种不同类型的回归,每种都有自己的优点和缺点。
在这篇文章中,我们将讨论5种最常见的回归算法及其属性,同时评估他们的性能。 最后,希望让您更全面地了解回归模型!
目录
- 线性回归
- 多项式回归
- 岭回归
- 套索回归
- 弹性网络回归
线性回归(Linear Regression)
回归是一种用于建模和分析变量之间关系的技术,通常是它们如何结合并且与一起产生特定结果相关。 线性回归指的是完全由线性变量组成的回归模型。 从简单的情况开始,单变量线性回归是一种技术,用于使用线性模型对单个输入自变量和输出因变量之间的关系进行建模。
更一般的情况是多变量线性回归,其中为多个独立输入变量(特征变量)和输出因变量之间的关系创建模型。 模型保持线性,输出是输入变量的线性组合。 我们可以建模多变量线性回归,如下所示:
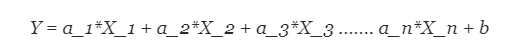
其中a_n是系数,X_n是变量,b是偏差。 我们可以看到,此函数不包含任何非线性,因此仅适用于对线性可分离数据进行建模,因为我们只是使用系数权重a_n来加权每个特征变量X_n的重要性。
关于线性回归的几个关键点:
- 建模快速简便,当要建模的关系不是非常复杂且没有大量数据时尤其有用。
- 非常直观地理解和解释。
- 线性回归对异常值非常敏感。
python实例:
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn import metrics
data=datasets.load_boston()# load data
#定义评估函数
def evaluation(y_true,y_pred,index_name=[‘OLS‘]):
df=pd.DataFrame(index=[index_name],columns=[‘平均绝对误差‘,‘均方误差‘,‘r2‘])
df[‘平均绝对误差‘]=metrics.mean_absolute_error(y_true, y_pred).round(4)
df[‘均方误差‘]=metrics.mean_squared_error(y_true,y_pred)
df[‘r2‘]=metrics.r2_score(y_true,y_pred)
return df
df=pd.DataFrame(data.data,columns=data.feature_names) target=pd.DataFrame(data.target,columns=[‘MEDV‘])
简单的可视化分析:
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="whitegrid", color_codes=True)
g=sns.pairplot(data[list(data.columns)[:5]], hue=‘ZN‘,palette="husl",diag_kind="hist",size=2.5)
for ax in g.axes.flat:
plt.setp(ax.get_xticklabels(), rotation=45)
plt.tight_layout()
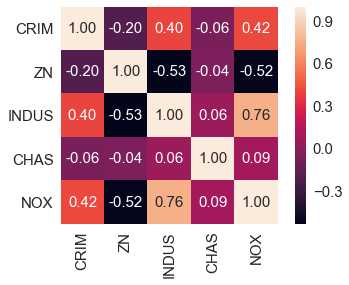
特征的相关系数图:
cm = np.corrcoef(data[list(data.columns)[:5]].values.T) #corrcoef方法按行计算皮尔逊相关系数,cm是对称矩阵
#使用np.corrcoef(a)可计算行与行之间的相关系数,np.corrcoef(a,rowvar=0)用于计算各列之间的相关系数,输出为相关系数矩阵。
sns.set(font_scale=1.5) #font_scale设置字体大小
cols=list(data.columns)[:5]
hm = sns.heatmap(cm,cbar=True,annot=True,square=True,fmt=‘.2f‘,annot_kws={‘size‘: 15},yticklabels=cols,xticklabels=cols)
# plt.tight_layout()
# plt.savefig(‘./figures/corr_mat.png‘, dpi=300)
用statsmodels模块的OLS
import statsmodels.api as sm X=df[df.columns].values y=target[‘MEDV‘].values #add constant X=sm.add_constant(X) # build model model=sm.OLS(y,X).fit() prediction=model.predict(X) print(model.summary())
也可以用sklearn模块:
from sklearn import linear_model lm = linear_model.LinearRegression() model = lm.fit(X,y) y_pred = lm.predict(X) lm.score(X,y) #系数 lm.coef_ #截距 lm.intercept_
evaluation(y,y_pred)

多项式回归(Polynomial Regression)
当我们想要创建一个适合处理非线性可分数据的模型时,我们需要使用多项式回归。 在这种回归技术中,最佳拟合线不是直线。 它是一条适合数据点的曲线。 对于多项式回归,一些自变量的幂大于1.例如:
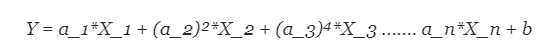
我们可以让一些变量具有指数,其他变量没有指数,并且还为每个变量选择我们想要的精确指数。 但是,选择每个变量的精确指数自然需要了解数据如何与输出相关。
note:
- 能够建模非线性可分离数据; 线性回归不能做到这一点。 它通常更灵活,可以建立一些相当复杂的关系。
- 完全控制特征变量的建模(指定要设置)。
- 需要仔细设计。 需要一些数据知识才能选择最佳指数。
- 如果指数选择不当,容易过度拟合。
python实例:
from sklearn.preprocessing import PolynomialFeatures poly_reg = PolynomialFeatures(degree = 4) X_Poly = poly_reg.fit_transform(X) lin_reg_2 =linear_model.LinearRegression() lin_reg_2.fit(X_Poly, y) y_pred=lin_reg_2.predict(poly_reg.fit_transform(X)) evaluation(y,y_pred,index_name=[‘poly_reg‘])
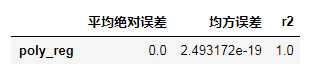
可以看到,误差很小,r2很大,模型已经过拟合。
岭回归(ride regression)
在特征变量之间存在高共线性的情况下,标准线性或多项式回归将失败。 共线性是独立变量之间存在近线性关系。 高共线性的存在可以通过几种不同的方式确定:
- 即使理论上该变量应该与Y高度相关,回归系数也不显着。
- 添加或删除X特征变量时,回归系数会发生显着变化。
- X特征变量具有高成对相关性(检查相关矩阵)。
我们首先可以看一下标准线性回归的优化函数,以获得有关岭回归如何帮助的一些见解:
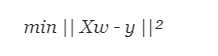
其中X代表特征变量,w代表权重,y代表实际值。 岭回归是一种补救措施,用于缓解回归模型中预测变量之间的共线性。 由于特征变量存在共线性,因此最终回归模型具有高方差。
为了缓解这个问题,Ridge Regression为变量添加了一个小的平方偏差因子:
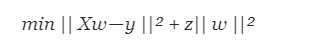
在模型中引入少量偏差,但大大减小了方差。
note:
- 该回归的假设与最小二乘回归类似,但没有正态性假设。
- 它会缩小系数的值,但不会达到零,这表明没有特征选择功能
python实例:
from sklearn.linear_model import Ridge ridge_reg = Ridge(alpha=1, solver="cholesky") ridge_reg.fit(X, y) y_pred=ridge_reg.predict(X evaluation(y,y_pred,index_name=‘ridge_reg‘)

套索回归(lasso regression)
套索回归与岭回归非常相似,因为两种技术都具有相同的前提。 我们再次为回归优化函数添加一个偏置项,以减少共线性的影响,从而减小模型方差。 然而,不是使用像岭回归那样的平方偏差,而套索回归使用绝对值偏差:
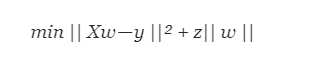
Ridge和Lasso回归之间存在一些差异,这些差异基本上可以回归到L2和L1正则化的属性差异:
- 内置特征选择:经常被提及为L1范数的有用属性,而L2范数则不然。这实际上是L1范数的结果,它倾向于产生稀疏系数。例如,假设模型有100个系数,但只有10个系数具有非零系数,这实际上是说“其他90个预测变量在预测目标值方面毫无用处”。 L2范数产生非稀疏系数,因此不具有此属性。因此,可以说Lasso回归做了一种“参数选择”,因为未选择的特征变量的总权重为0。
- 稀疏性:指矩阵(或向量)中只有极少数条目为非零。 L1范数具有产生许多具有零值的系数或具有很少大系数的非常小的值的特性。这与Lasso执行一种特征选择的前一点相关联。
- 计算效率:L1范数没有解析解,但L2有。在计算上可以有效地计算L2范数解。然而,L1范数具有稀疏性属性,允许它与稀疏算法一起使用,这使得计算在计算上更有效。
from sklearn.linear_model import Lasso lasso_reg = Lasso(alpha=0.1) lasso_reg.fit(X, y) y_pred=lasso_reg.predict(X) evaluation(y,y_pred,index_name=‘lasso_reg‘)

弹性网络回归(ElasticNet Regression)
ElasticNet是Lasso和Ridge Regression技术的混合体。 它使用L1和L2正则化来考虑两种技术的影响:
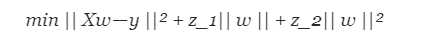
在Lasso和Ridge之间进行权衡的一个实际优势是:它允许Elastic-Net在旋转下继承Ridge的一些稳定性。
note:
- 它在高度相关的变量的情况下鼓励群体效应,而不是像Lasso那样将其中的一些归零。
- 所选变量的数量没有限制。
python实例:
enet_reg = linear_model.ElasticNet(l1_ratio=0.7) enet_reg.fit(X,y) y_pred=enet_reg.predict(X) evaluation(y,y_pred,index_name=‘enet_reg ‘)

小结:
这篇文章简单总结了5种常见类型的回归及其属性。 所有这些回归正则化方法(Lasso,Ridge和ElasticNet)在数据集中变量之间的高维度和多重共线性的情况下都能很好地工作。 希望对大家有帮助!
以上是关于五种回归方法的比较的主要内容,如果未能解决你的问题,请参考以下文章