数据转图像表征学习均值编码转换目标变量
Posted wzdly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据转图像表征学习均值编码转换目标变量相关的知识,希望对你有一定的参考价值。
原文:https://www.toutiao.com/i6597192035214557710/
几种新的特征转换思维:
1.数据转换成图像
Kaggle上有一个微软恶意软件分类挑战,它的数据集包含一组已知的恶意软件文件,对于每个文件,原始数据包含文件二进制内容的十六进制表示。此前,参赛者在网上从没接触过类似的数据集,而他们的目标是开发最优分类算法,把测试集中的文件放到各自所属的类别中。比赛冠军的特征方法:
将恶意文件的字节文档看成黑白图像,其中每个字节的像素强度在0-255之间。然而,标准图像处理技术与n-gram等其他特征不兼容。所以之后,我们从asm文件而不是字节文件中提取黑白图像。
下图是同一恶意软件的字节图像、asm图像对比(左边是字节图像,右边是asm图像):

asm文件是用汇编语言写成的源程序文件。这个团队发现把asm文件转成图像后,图像的前800-1000个像素的像素强度可以作为分类恶意软件的一个可靠特征。单独使用这个特征并不会给分类器性能带来明显变化,但当它和其他n-gram特征一起使用时,性能提升效果就很显著了。
2.表征学习特征
自编码器能从数据样本中进行无监督学习,这意味着算法直接从训练数据中捕捉最显著的特征,无需其他特征工程。
3.均值编码
用平均数这样的统计量度来对分类值进行编码,这就叫均值编码。
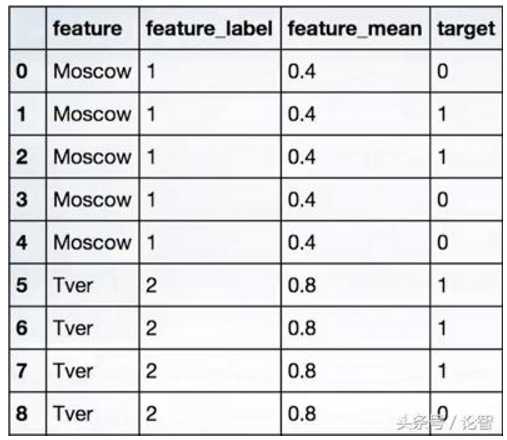
feature_label是scikit-learn编码的标签,feature_mean就是莫斯科标签下的真实目标数量/莫斯科标签下的目标总数,也就是2/5=0.4;
对于Tver标签—m=Tver标签下的真实目标数量=3,n=Tver标签下的目标总数=4,相应的,Tver编码就是m/n=3/4=0.75(约等于0.8);
数据分析中经常会遇到类别属性,比如日期、性别、街区编号、IP地址等。绝大部分数据分析算法是无法直接处理这类变量的,需要先把它们先处理成数值型量。如果这些变量的可能值很多,也就是高基数,那么在这种情况下,使用label encoding会出现一系列连续数字,在特征中添加噪声标签和编码会导致精度不佳,使用one-hot编码,随着特征不断增加,数据集的维数也在不断增加,这会阻碍编码。因此,这时均值编码是最好的选择之一。但它也有缺点,就是容易过拟合,所以使用时要配合适当的正则化技术:CV 、Regularization Smoothing、Regularization Expanding mean。
4.转换目标变量
当我们拿到一个高度偏斜的数据时,如果我们不做任何处理,最后模型的性能肯定会受影响。
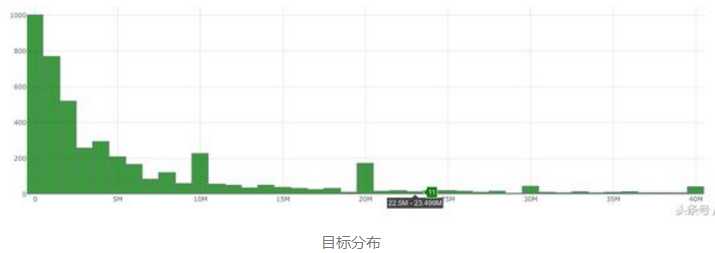
如上图所示,这里的数据高度偏斜,如果我们把目标变量转成log(1+目标)格式,那么它的分布就接近高斯分布了。
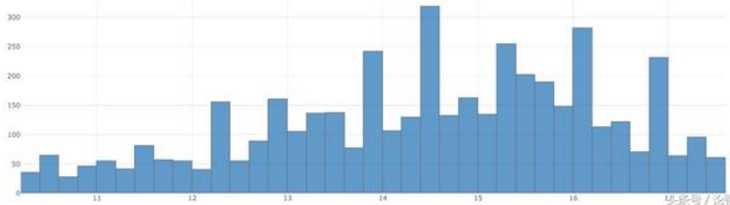
需要注意的是,提交预测值时,我们需要进行转换回来。
以上是关于数据转图像表征学习均值编码转换目标变量的主要内容,如果未能解决你的问题,请参考以下文章