分布式任务队列celery用法详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式任务队列celery用法详解相关的知识,希望对你有一定的参考价值。
celery基础介绍: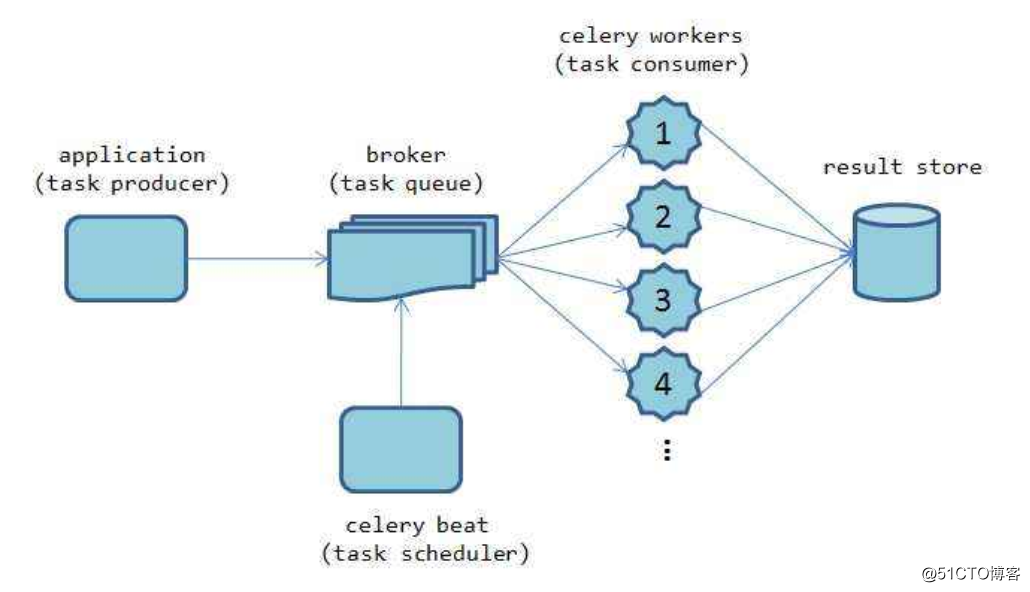
这个图我们可以看出,celery基本结构也就是三部分
1 第一部分 broker也就是中间件消息队列,作用就是用来接收应用的请求
这一部分常见玩法可以是rabbitmq和redis等
2 第二部分 worker 也就是工作队列 也就是celery本身的任务队列服务,一般情况下大型的生产应用我们会结合supervisor来管理这么多的worker
3 第三部分 result 存储,就是把执行的结果,状态等信息进行存储,常规用法我们可以用rabbitmq redis,mysql,mongodb等来做
环境部署:
1pip install celery
2 安装 rabbitmq 这个我得博客有篇文章做了详细讲解
3 安装redis ,源码安装很简单,不做介绍
首先做一个基础的例子体验什么是celery
[[email protected] www]# cat tasks.py
#!/usr/bin/python
#coding:utf-8
from celery import Celery
app = Celery(‘tasks‘, broker=‘amqp://‘,backend=‘redis://‘)
#app.config_from_object(‘celeryconfig‘)
@app.task
def add(x, y):
return x + y
broker是接受的消息队列的地址我这里用的rabbitmq的地址
backend是后端的存储我这里用的是redis
启动task
celery -A tasks worker --loglevel=info
然后我们新开一个终端进入python命令行去调用task
#python
#from tasks import add
#add.delay(2,4)

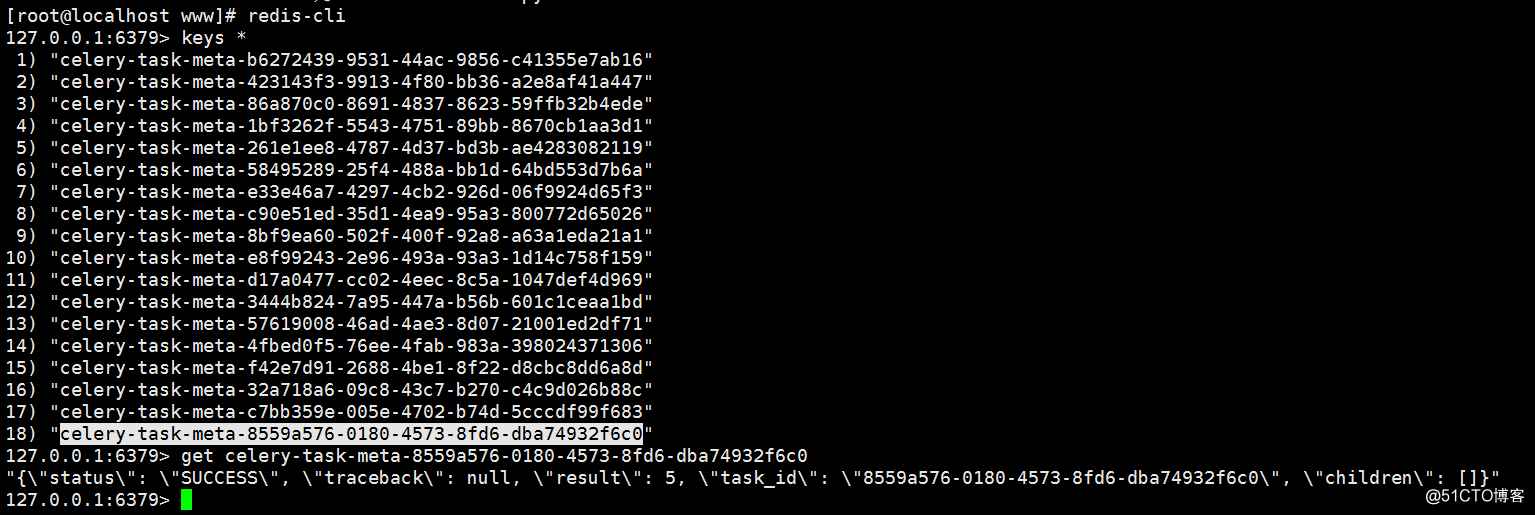
可以看出我们每次在python终端调用add这个任务 celery的worker 信息里面就会收到操作并记录信息 同时redis里面记录相应的状态
======================================================
celery与tasks分离
[[email protected] test]# cat celery.py
#!/usr/bin/python
#coding:utf-8
from future import absolute_import ,unicode_literals
from celery import Celery
app = Celery(
‘test‘,
broker=‘amqp://‘,
backend=‘redis://‘,
include=[‘test.tasks‘]
)
app.conf.update(
result_expires=3500,
)
if name == ‘main‘:
app.start()
[[email protected] test]# cat tasks.py
#!/usr/bin/python
#coding:utf-8
from future import absolute_import ,unicode_literals
from test.celery import app
@app.task
def add(x,y):
return x + ybr/>@app.task
def cheng(x,y):
return x * y
后台启动 celery
celery multi start w1 -A proj -l info --logfile=/var/log/celery.log
celery有一堆的配置参数来控制每一个task这里不做解说详情见官网
重点是思路:
1 以前批量执行paramiko脚本的时候,一旦执行的机器多了,后来优化成多线程用threading来做,看到这个异步的任务队列,我们可以把机器按队列进行分组,进行路由限制数量,流量控制等等来对大批量的task任务进行分批量并发操作
2 还可以结合python框架web界面 applicate的过程,celery的worker的过程状态和后端的结果状态都集成到一个页面,实时监测,界面化操作
以上是关于分布式任务队列celery用法详解的主要内容,如果未能解决你的问题,请参考以下文章