004简单介绍WordCount,统计文本单词次数
Posted sirlijun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了004简单介绍WordCount,统计文本单词次数相关的知识,希望对你有一定的参考价值。
MapReduce简介
- MapReduce是一种分布式计算模型,主要解决海量数据的计算问题。
- MR有两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算。
MapReduce的原理图
- MR执行的流程
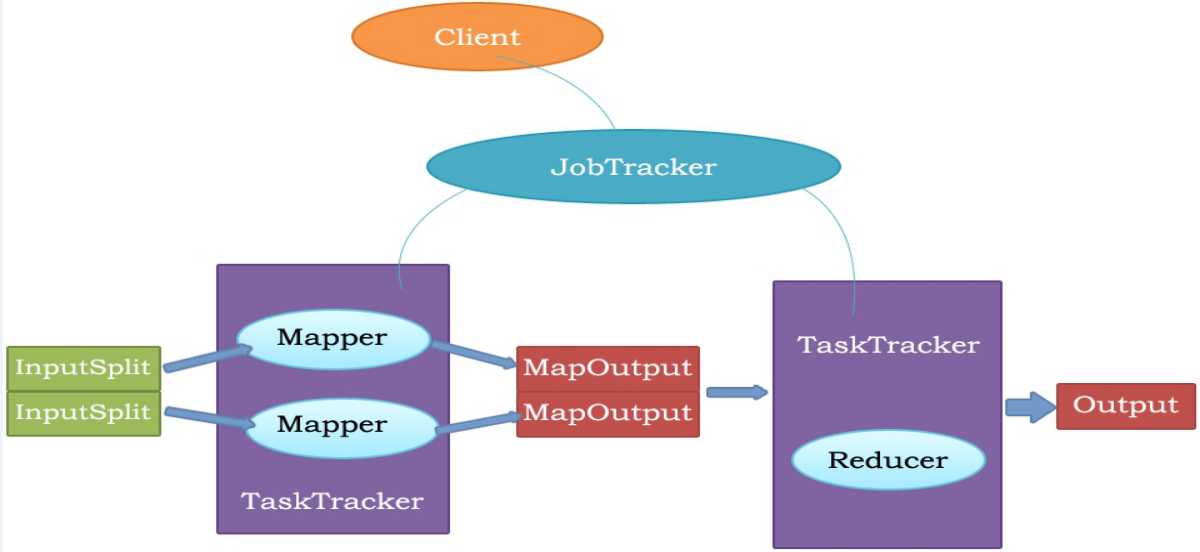
2.MR原理图
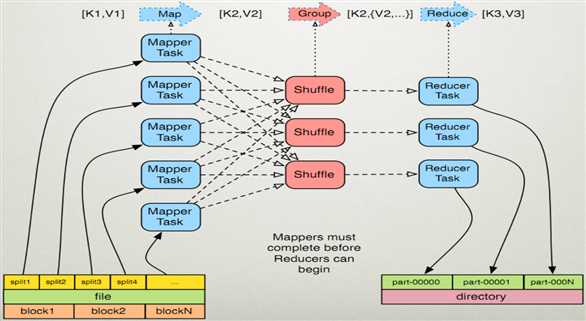
- 根据代码简单了解MR。
package com.lj.MR;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//super.map(key, value, context);
String[] arr = value.toString().split(" ");
Text keyOut = new Text();
IntWritable valueOut = new IntWritable();
for(String s :arr){
keyOut.set(s);
valueOut.set(1);
try {
context.write(keyOut,valueOut);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
package com.lj.MR; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.io.Text; import java.io.IOException; public class WCReducce extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //super.reduce(key, values, context); int count = 0; for(IntWritable iw:values){ count = count + iw.get(); } context.write(key,new IntWritable(count)); } }
package com.lj.MR; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.log4j.BasicConfigurator; public class WCApp { public static void main(String[] args) { BasicConfigurator.configure(); Configuration conf = new Configuration();
//此处为本地测试 // conf.set("fs.defaultFS","file:///D://ItTools"); try { //单例模式 Job job = Job.getInstance(conf); //任务作业名字 job.setJobName("WCApp"); //搜索类 job.setJarByClass(WCApp.class); //设置输入格式 job.setInputFormatClass(TextInputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setMapperClass(WCMapper.class); job.setReducerClass(WCReducce.class); job.setNumReduceTasks(1); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.waitForCompletion(false); } catch (Exception e) { e.printStackTrace(); } } }
- 代码简单解析:
根据执行流程图我们不难发现,首先我们从Mapper下手,然后着手Reducer,而Reducer的key(in),value(in),肯定是Mapper的key(out),value(out),否则我们不难发现,一定会类型不匹配,直接报错。
MAP:就是将原本文字转换成(k,v),其中k就是word,v就是单词的出现的次数
Shuffle:将相同的k排列一起
Reduce:将相同的k的v相加
以上是关于004简单介绍WordCount,统计文本单词次数的主要内容,如果未能解决你的问题,请参考以下文章