tensorflow源码学习之一 -- tf架构
Posted lixiaolun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了tensorflow源码学习之一 -- tf架构相关的知识,希望对你有一定的参考价值。
目前总共4篇:
tensorflow的架构图如下:
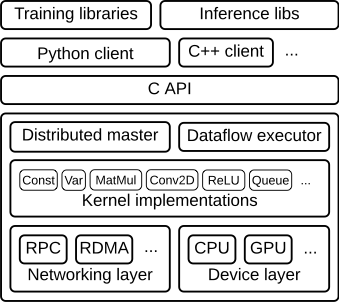
我们主要使用的是Python client + C API + Distributed master + Dataflow executor(worker & ps)。
- client:
定义计算数据流图(声明变量、执行Add操作等已经开始构建图了);
使用session.run()将图(graph def)发送给。 - Distributed master
根据session.run()传递的参数填充、优化数据流图
使用placer.cc对数据流图中每个node分配机器和设备(CPU/GPU)
使用graph_partition.cc根据placer结果将图切分到不同的机器上,并添加Send/Recv操作
分发子图到worker & ps上 - Dataflow executor(worker service)
执行图运算(包括Send/Recv操作)
交互关系图如下:

注:"/job:worker/task:0" and "/job:ps/task:0" are both tasks with worker services。
下面是一段分布式训练示例代码:
‘‘‘
Distributed Tensorflow 0.8.0 example of using data parallelism and share model parameters.
Trains a simple sigmoid neural network on mnist for 20 epochs on three machines using one parameter server.
Change the hardcoded host urls below with your own hosts.
Run like this:
python train.py --job_name="ps" --task_index=0
python train.py --job_name="ps" --task_index=1
python train.py --job_name="worker" --task_index=0
python train.py --job_name="worker" --task_index=1
More details here: ischlag.github.io
‘‘‘
from __future__ import print_function
import tensorflow as tf
import sys
import time
# cluster specification
parameter_servers = ["node1:2221", "node1:2222"]
workers = [ "node1:2223", "node1:2224"]
cluster = tf.train.ClusterSpec({"ps":parameter_servers, "worker":workers})
# input flags
tf.app.flags.DEFINE_string("job_name", "", "Either ‘ps‘ or ‘worker‘")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
FLAGS = tf.app.flags.FLAGS
# start a server for a specific task
# ensorflowpython rainingserver_lib.py (line 97)
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
# config
batch_size = 100
learning_rate = 0.0005
training_epochs = 20
logs_path = "/tmp/mnist/log"
# load mnist data set
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets(‘MNIST_data‘, one_hot=True)
if FLAGS.job_name == "ps":
server.join()
elif FLAGS.job_name == "worker":
# Between-graph replication
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
# count the number of updates
global_step = tf.get_variable(‘global_step‘, [],
initializer = tf.constant_initializer(0),
trainable = False)
# input images
with tf.name_scope(‘input‘):
# None -> batch size can be any size, 784 -> flattened mnist image
x = tf.placeholder(tf.float32, shape=[None, 784], name="x-input")
# target 10 output classes
y_ = tf.placeholder(tf.float32, shape=[None, 10], name="y-input")
# model parameters will change during training so we use tf.Variable
tf.set_random_seed(1)
# with tf.name_scope("weights"):
# W1 = tf.Variable(tf.random_normal([784, 100]))
# W2 = tf.Variable(tf.random_normal([100, 10]))
#
# # bias
# with tf.name_scope("biases"):
# b1 = tf.Variable(tf.zeros([100]))
# b2 = tf.Variable(tf.zeros([10]))
#
# # implement model
# with tf.name_scope("softmax"):
# # y is our prediction
# z2 = tf.add(tf.matmul(x,W1),b1)
# a2 = tf.nn.sigmoid(z2)
# z3 = tf.add(tf.matmul(a2,W2),b2)
# y = tf.nn.softmax(z3)
with tf.name_scope("weights"):
W1 = tf.Variable(tf.random_normal([784, 10]))
# bias
with tf.name_scope("biases"):
b1 = tf.Variable(tf.zeros([10]))
# implement model
with tf.name_scope("softmax"):
# y is our prediction
z2 = tf.add(tf.matmul(x,W1),b1)
y = tf.nn.softmax(z2)
# specify cost function
with tf.name_scope(‘cross_entropy‘):
# this is our cost
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
# specify optimizer
with tf.name_scope(‘train‘):
# optimizer is an "operation" which we can execute in a session
grad_op = tf.train.GradientDescentOptimizer(learning_rate)
‘‘‘
rep_op = tf.train.SyncReplicasOptimizer(grad_op,
replicas_to_aggregate=len(workers),
replica_id=FLAGS.task_index,
total_num_replicas=len(workers),
use_locking=True)
train_op = rep_op.minimize(cross_entropy, global_step=global_step)
‘‘‘
train_op = grad_op.minimize(cross_entropy, global_step=global_step)
‘‘‘
init_token_op = rep_op.get_init_tokens_op()
chief_queue_runner = rep_op.get_chief_queue_runner()
‘‘‘
with tf.name_scope(‘Accuracy‘):
# accuracy
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# create a summary for our cost and accuracy
tf.summary.scalar("cost", cross_entropy)
tf.summary.scalar("accuracy", accuracy)
# merge all summaries into a single "operation" which we can execute in a session
summary_op = tf.summary.merge_all()
init_op = tf.initialize_all_variables()
print("Variables initialized ...")
sv = tf.train.Supervisor(logdir=‘/tmp/distributed_mnist‘, is_chief=(FLAGS.task_index == 0),
global_step=global_step,
init_op=init_op)
begin_time = time.time()
frequency = 100
with sv.prepare_or_wait_for_session(server.target) as sess:
‘‘‘
# is chief
if FLAGS.task_index == 0:
sv.start_queue_runners(sess, [chief_queue_runner])
sess.run(init_token_op)
‘‘‘
# create log writer object (this will log on every machine)
writer = tf.summary.FileWriter(logs_path, graph=tf.get_default_graph())
# perform training cycles
start_time = time.time()
for epoch in range(training_epochs):
# number of batches in one epoch
batch_count = int(mnist.train.num_examples/batch_size)
count = 0
for i in range(batch_count):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# perform the operations we defined earlier on batch
_, cost, summary, step = sess.run(
[train_op, cross_entropy, summary_op, global_step],
feed_dict={x: batch_x, y_: batch_y})
writer.add_summary(summary, step)
count += 1
if count % frequency == 0 or i+1 == batch_count:
elapsed_time = time.time() - start_time
start_time = time.time()
print("Step: %d," % (step+1),
" Epoch: %2d," % (epoch+1),
" Batch: %3d of %3d," % (i+1, batch_count),
" Cost: %.4f," % cost,
" AvgTime: %3.2fms" % float(elapsed_time*1000/frequency))
count = 0
print("Test-Accuracy: %2.2f" % sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
print("Total Time: %3.2fs" % float(time.time() - begin_time))
print("Final Cost: %.4f" % cost)
sv.stop()
print("done")
这里,我们使用的是Between-graph replication和Asynchronous training训练方式。
注意,tf支持多种训练方式,参考:https://www.tensorflow.org/deploy/distributed#replicated_training
- Between-graph replication:需要设置tf.train.replica_device_setter;
- Asynchronous training :使用GradientDescentOptimizer。
如果使用同步训练,需要使用SyncReplicasOptimizer。
以上是关于tensorflow源码学习之一 -- tf架构的主要内容,如果未能解决你的问题,请参考以下文章