Paper Reading - Attention Is All You Need ( NIPS 2017 )
Posted zlian2016
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Paper Reading - Attention Is All You Need ( NIPS 2017 )相关的知识,希望对你有一定的参考价值。
Link of the Paper: https://arxiv.org/abs/1706.03762
Motivation:
- The inherently sequential nature of Recurrent Models precludes parallelization within training examples.
- Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences. In all but a few cases, however, such attention mechanisms are used in conjunction with a recurrent network.
Innovation:
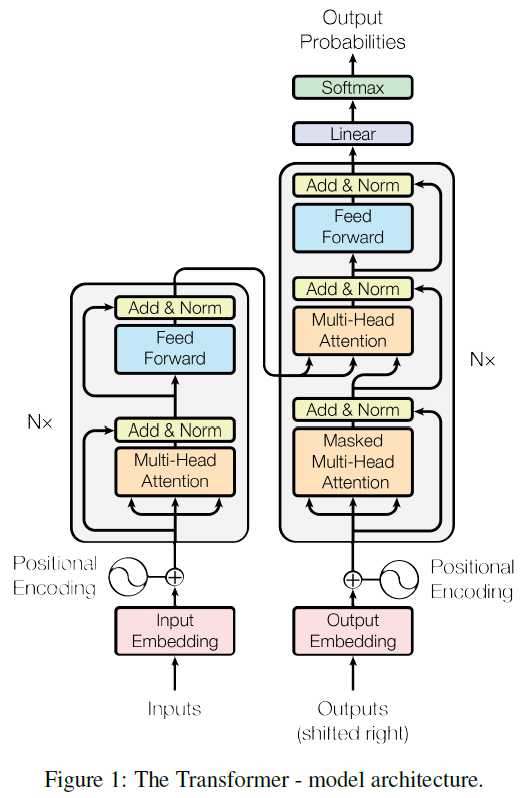
- The first sequence transduction model, the Transformer, relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or Convolutions. The Transformer follows the overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
- Encoder: The encoder is composed of a stack of N = 6 identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network. The authors employ a residual connection around each of the two sub-layers, followed by layer normalization. That is, the output of each sub-layer is LayerNorm (x + Sublayer(x)), where Sublayer(x) is the function implemented by the sub-layer itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension dmodel = 512.
- Decoder: The decoder is also composed of a stack of N = 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, they employ residual connections around each of the sub-layers, followed by layer normalization. They also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
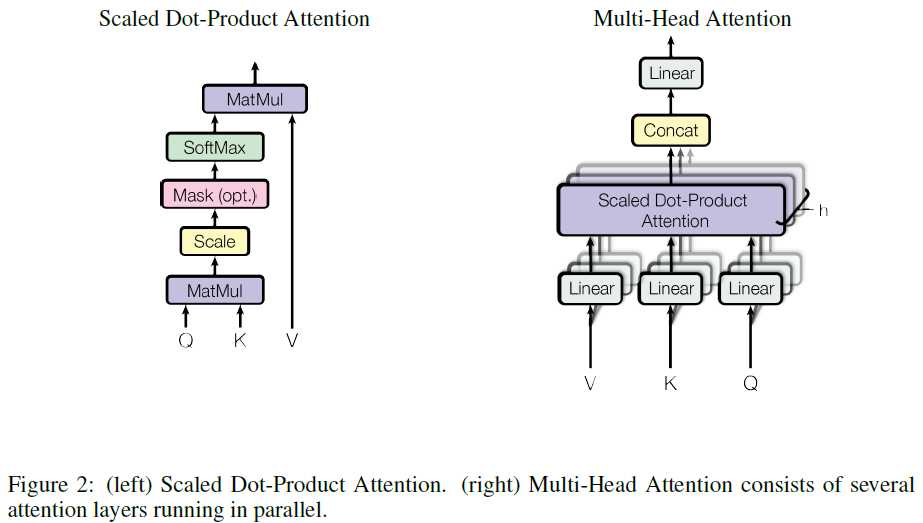
- Scaled Dot-Product Attention and Multi-Head Attention.
General Points:
- An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
以上是关于Paper Reading - Attention Is All You Need ( NIPS 2017 )的主要内容,如果未能解决你的问题,请参考以下文章