Java集合
Posted 学习java的小学僧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java集合相关的知识,希望对你有一定的参考价值。
1. Java中有哪些集合容器?
Java的集合类主要由Collection和Map这两个接口派生而来,其中Collection接口又派生出三个子接口,分别是Set、List、Queue。所有的Java集合类,都是Set、List、Queue和Map这四个接口的实现类,这四个接口将集合分成了四大类。
| 集合 | 特征 |
|---|---|
| Set | 无序的、元素不可重复的集合 |
| List | 有序的、元素可以重复的集合 |
| Queue | 先进先出的队列 |
| Map | 具有映射关系的(key-value)的集合 |
这些接口拥有众多的实现类,其中最常用的实现类有HashSet、TreeSet、ArrayList、LinkedList、ArrayDeque、HashMap、TreeMap等。
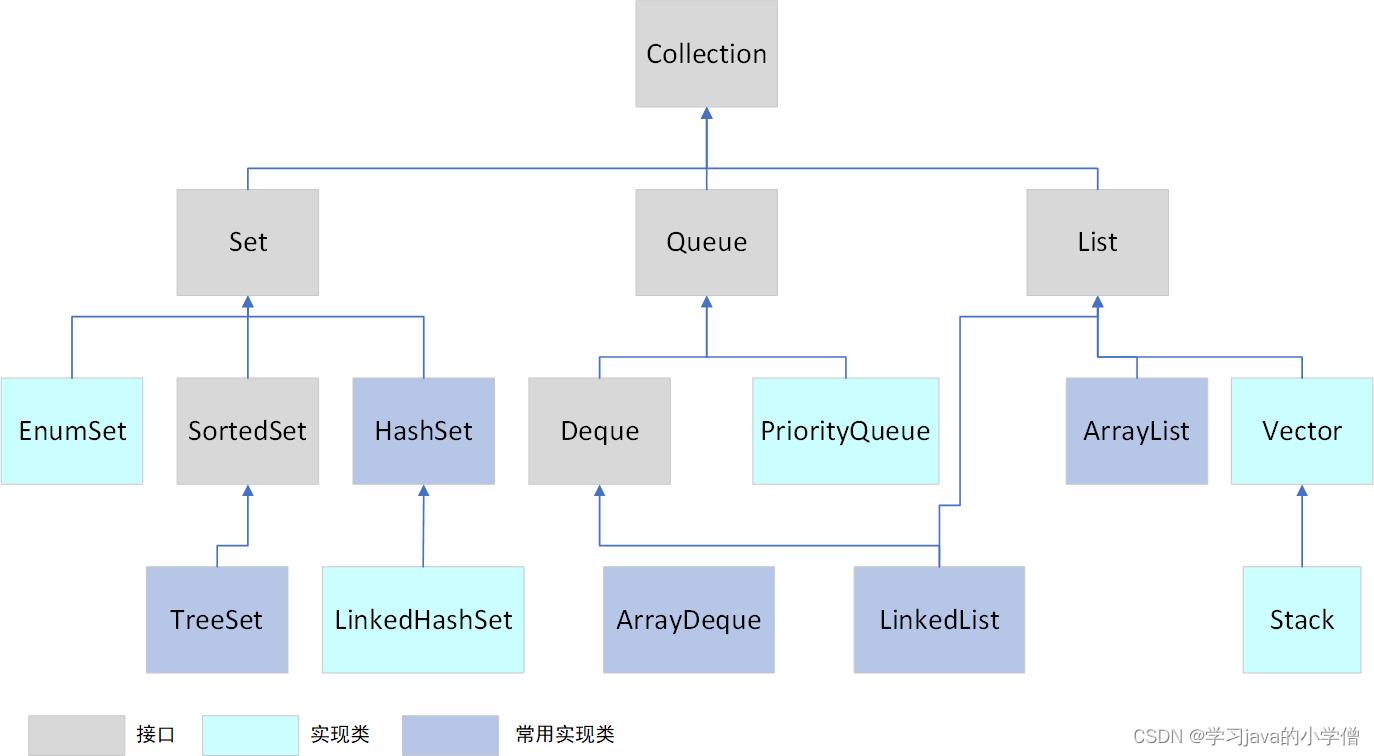
Collection体系继承树:
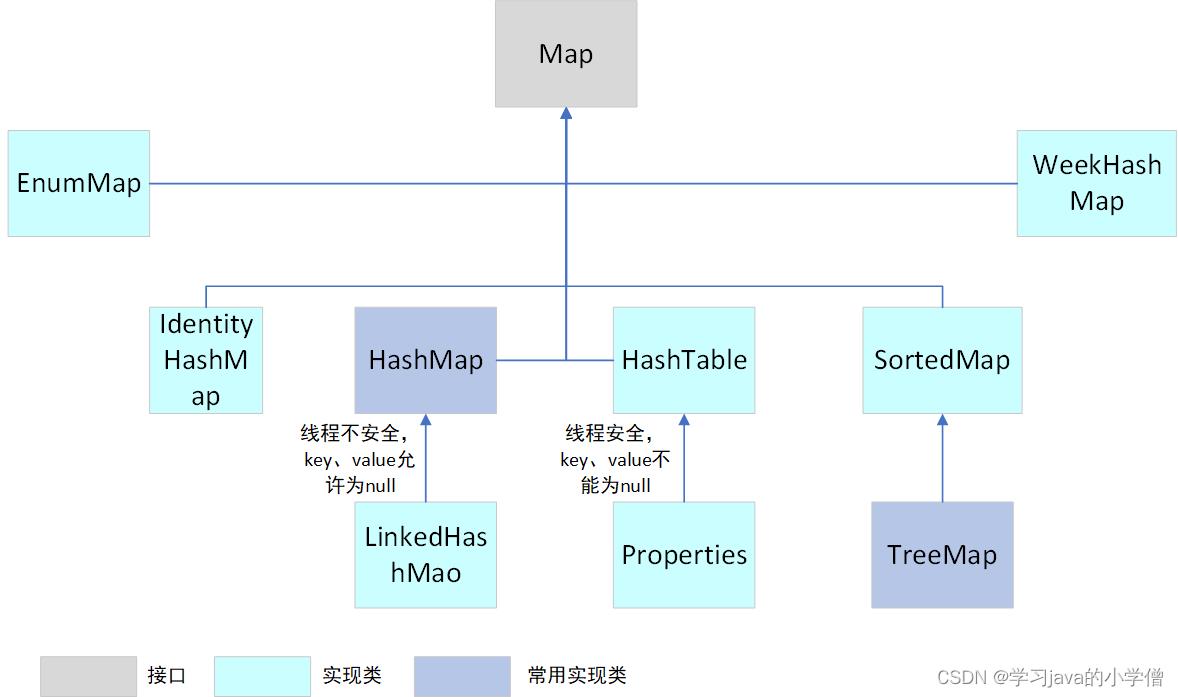
Map体系继承树:
2. Java中的容器,线程安全和线程不安全的分别有哪些?
java.util包下的集合类大部分都是线程不安全的,例如我们常用的HashSet、TreeSet、ArraryList、LinkedList、ArraryDeque、HashMap、TreeMap,这些都是线程不安全的集合类,但是它们的优点是性能好。如果需要使用线程安全的及黑雷,可以使用Collections工具类提供的synchronizedXXX()方法,将这些集合类包装秤线程安全的集合类。
java.util包下也有线程安全的集合类,例如Vector、HashTable。这些集合类都是比较古老的API,虽然实现了线程安全,但是性能很差,所以及时是需要使用线程安全的集合类,也建议将线程不安全的集合类包装成线程安全集合类的方式,而不是直接使用这些古老的API。
从Java5开始,Java在java.util.concurrent包下提供了大量支持高效并发访问的集合类,它们既能包装良好的访问性能,又能包装线程安全。这些集合类可以分为两个部分:
-
以concurrent开头的集合类:
以concurrent开头的集合类代表了支持并发访问的集合,可以支持多个线程并发写入访问,这些写入线程的操作都是线程安全的,但读取操作不必锁定。以concurrent开头的集合类采用了更复杂的算法来保证永远不会锁住整个集合,因此在并发写入时有较好的性能
-
以CopyOnWrite开头的集合类
以CopyOnWrite开头的集合类采用复制顶层数组的方式来实现写操作。当线程对此类集合执行读取操作时,线程将会直接读取集合本身,无须加锁与阻塞。当线程对此类集合执行写入操作时,集合会在底层复制一份新的数组,接下来对新的数组执行写入操作。由于对集合的写入操作都是对数组的副本执行操作,因此它是线程安全的。
3. Map接口有哪些实现类?
Map接口又很多实现类,其中比较常用的有:HashMap、LinkedHashMap、TreeMap、ConcurrentHashMap。
对于不需要排序的场景,优先考虑使用HashMap,因为它是性能最好的Map实现。如果需要保证线程安全,则可以使用ConcurrentHashMap,它的性能好于Hashtable,因为它在put时采用分段锁/CAS的加锁机制,而不像Hashtable那样,无论是put还是get都做同步处理。
对于需要排序的场景,如果需要按插入顺序排序,则可以使用LinkedHashMap,如果需要将key按自然顺序排列甚至自定义顺序排列,则可以选择TreeMap。如果需要保证线程安全,则可以使用Collections工具类将上述实现类包装成线程安全的Map。
4. 关于HashMap
4.1 HashMap的特点
- HashMap是线程不安全的实现
- HashMap可以使用null作为key或value
4.2 JDK7和JDK8中HashMap的区别
JDK7中的HashMap,是基于数组+链表,其底层维护一个Entry数组。它会根据计算的hashCode将对应的KV键值对存储到该数组中,一旦发生hashCode冲突,那么就会将该KV键值对放到对应的已有元素的后面,此时便形成了一个链表式的存储结构。但是该实现方案有一个明显的缺点,即当Hash冲突严重时,在桶上形成的链表会变得越来越长,这样在查询的时候效率会越来越低,其时间复杂度为O(N)。
JDK8中的HashMap,是基于数组+链表+红黑树来实现的,其底层维护一个Node数组。当链表存储的数据个数大于等于8的时候,不再采用链表存储,而采用了红黑树存储结构。主要实在查询的时间复杂度上进行优化,链表尾O(N),而红黑树一直都是O(logN),可以大大的提高查找性能。
4.3 HashMap的put过程
HashMap是最经典的Map实现,下面从HashMap的视角介绍put的过程:
-
首次扩容
先判断数组是否为空,若数组为空则进行第一次扩容(resize);
-
计算索引
通过hash算法,计算键值对在数组中的索引
-
插入数据
- 如果当前位置元素为空,则直接插入数据;
- 如果当前位置元素非空,且key已存在,则直接覆盖其Value;
- 如果当前位置元素非空,且key不存在,则讲数据链到链表末端;
- 如果链表长度达到8,则将链表转成红黑树,并将数据插入树中;
-
再次扩容
如果数组中元素个数超过threshold,则再次进行扩容操作。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qrKOfepZ-1675355668440)(C:\\Users\\pc\\AppData\\Roaming\\Typora\\typora-user-images\\image-20230122145725107.png)]
4.4 HashMap的扩容机制
1. 数组的初始容量为16,容量是以2的次方扩充的,一是为了提高性能使用足够大的数组,二是为了能使用位运算代替取模运算。
1. 数组是否需要扩容是通过负载因子判断的,如果当前元素个数为数组容量的0.75,就会扩充数组。0.75是默认的负载因子,可由构造器传入。也可以设置大于1的负载因子,这样数组不会扩充,牺牲性能,节省内存。
1. 为了解决碰撞冲突,数组中的元素是单向链表结构。当链表长度达到一个阈值(7/8),会将链表转换成红黑树提高性能;而当链表长度缩短为另一个阈值时(6),又会将红黑树转换回单链表。
1. 检查链表长度转换成红黑树之前,还会先检测当前数组是否达到一个阈值(64),如果没有达到这个容量,会放弃转换,先去扩充数组。所以上面说链表调整阈值时7/8,因为会有一次放弃转换的操作。
4.5 HashMap中的循环链表的产生
在多线程的情况下,当重新调整HashMap大小的时候,就会存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历。如果条件竞争发生了,那么就会产生死循环了。
4.6 HashMap为什么用红黑树而不用B树
B/B+树多用于外存上,B/B+树也被称为一个磁盘友好的数据结构。
HashMap本来是数组+链表的形式,由于链表具有查找慢的特点,所以需要被查找效率更高的树结构来代替。如果用B/B+树的话,在数据量不是很多的情况下,数据都会“挤在”一个节点中,这个时候后遍历效率就退化成了链表。
4.7 HashMap是如何解决哈希冲突的?
为了解决碰撞,数组中的元素是单向链表的类型。当链表长度达到一个阈值时,会将链表转换成红黑树提高性能。而当链表长度缩小到一个阈值时,又会将红黑树转换回单项链表提高性能。
4.8 HashMap和HashTable的区别
- Hashtable是一个线程安全的Map实现,但HashMap是线程不安全的实现,所以HashMap比Hashtable的性能高一点。
- Hashtable不允许使用null作为key和value,如果试图把null值放进hashtable中,将会引发空指针异常,但HashMap可以使用null作为key或value。
4.9 ConcurrentHashMap的实现
在JDK1.7中的实现:
在JDK1.7中,ConcurrentHashMap 是由 Segment 数据结构和 HashEntry 数组结构构成,采取分段锁来保证安全性。Segment 是 ReentrantLock 重入锁,在 ConcurrentHashMap 中扮演锁的角色,HashEntry 则用于存储键值对数据。一个 ConcurrentHashMap 里包含一个 Segment 数组,一个Segment 里包含一个 HashEntry 数组,Segment 的结构和 HashMap 类似,是一个数组和链表结构。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S8TXpZXl-1675355668441)(C:\\Users\\pc\\AppData\\Roaming\\Typora\\typora-user-images\\image-20230130184253566.png)]
JDK 1.8中的实现:
JDK1.8 的实现已经摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 Synchronized 和 CAS 来操作,整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G62F5tWv-1675355668442)(C:\\Users\\pc\\AppData\\Roaming\\Typora\\typora-user-images\\image-20230130184458764.png)]
4.10 ConcurrentHashMap是怎么分段分组的?
get操作:
Segment的get操作实现非常简单和高效,先经过一次再散列,然后使用这个散列值通过散列运算定位到 Segment,再通过散列算法定位到元素。get操作的高效之处在于整个get过程都不需要加锁,除非读到空的值才会加锁重读。原因就是将使用的共享变量定义成 volatile 类型。
put操作:
当执行put操作时,会经历两个步骤:
-
判断是否需要扩容;
-
定位到添加元素的位置,将其放入 HashEntry 数组中。
插入过程会进行第一次 key 的 hash 来定位 Segment 的位置,如果该 Segment 还没有初始化,即通过CAS 操作进行赋值,然后进行第二次 hash 操作,找到相应的 HashEntry 的位置,这里会利用继承过来的锁的特性,在将数据插入指定的 HashEntry 位置时(尾插法),会通过继承 ReentrantLock 的tryLock() 方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用 tryLock() 方法去获取锁,超过指定次数就挂起,等待唤醒。
4.11 对LinkedHashMap的理解
LinkedHashMap使用双向链表来维护key-value对的顺序(其实只需要考虑key的顺序),该链表负责维护Map的迭代顺序,迭代顺序与key-value对的插入顺序保持一致。
LinkedHashMap可以避免对HashMap、Hashtable里的key-value对进行排序(只要插入key-value对时保持顺序即可),同时又可避免使用TreeMap所增加的成本。
LinkedHashMap需要维护元素的插入顺序,因此性能略低于HashMap的性能。但因为它以链表来维护内部顺序,所以在迭代访问Map里的全部元素时将有较好的性能。
4.12 介绍LinkedHashMap的底层原理
LinkedHashMap继承于HashMap,它在HashMap的基础上,通过维护一条双向链表,解决了HashMap不能随时保持遍历顺序和插入顺序一致的问题。在实现上,LinkedHashMap很多方法直接继承自HashMap,仅为维护双向链表重写了部分方法。
淡蓝色的箭头表示前驱引用,红色箭头表示后继引用。每当有新的键值对节点插入时,新节点最终会接在tail引用指向的节点后面。而tail引用则会移动到新的节点上,这样一个双向链表就建立起来了[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LVANpYZo-1675355668443)(C:\\Users\\pc\\AppData\\Roaming\\Typora\\typora-user-images\\image-20230130190333679.png)]
5. 如何获得一个线程安全的Map
- 使用Collection工具类,将线程不安全的Map包装成线程安全的Map
- 使用java.util.concurrent包下的Map,如ConcurrentHashMap;
- 不建议使用Hashtable,虽然Hashtable是线程安全的,但是性能较差。
使用HashTable
Map<String, String> hashtable = new Hashtable<>();
@SuppressWarnings("unchecked")
public synchronized V get(Object key)
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next)
if ((e.hash == hash) && e.key.equals(key))
return (V)e.value;
return null;
实现原理是在增删改查的方法上使用了synchronized锁机制,在多线程环境下,无论是读数据还是修改数据,在同一时刻只能有一个线程在执行synchronized方法(所有线程竞争同一把锁),因为对整个表进行锁定。所以线程越多,对该map的竞争越激烈,效率越低。
使用Collections.synchronizedMap
Map<String, String> synchronizedHashMap
=Collections.synchronizedMap(new HashMap<String, String>());
调用synchronizedMap()方法后会返回一个SynchronizedMap类的对象,而在SynchronizedMap类中使用了synchronized同步关键字来保证对Map的操作是安全的。
实现原理是使用工具类里的静态方法,把传入的HashTable包装成同步的,即在增删改查的方法上增加了synchronized锁机制,每次操作hashmap都需要先获取到这个对象锁,这个对象锁加了synchronized修饰,其实现方式和HashTable差不多,效率也很低。
使用ConcurrentHashMap
实现原理是HashTable是对整个表进行加锁,而ConcurrentHashMap是把表进行分段,初始情况下分成16段,每一段都有一把锁。当多个线程访问不同的段时,因为获取到的锁是不同的,所以可以并行访问。效率比HashTable。
6. TreeMap
TreeMap基于红黑树(Red-Black tree)实现。映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。TreeMap的基本操作containsKey、get、put、remove方法,它的时间复杂度是log(N)。
TreeMap包含几个重要的成员变量:root、size、comparator。其中root是红黑树的根节点。它是Entry类型,Entry是红黑树的节点,它包含了红黑树的6个基本组成:key、value、left、right、parent和color。Entry节点根据根据Key排序,包含的内容是value。Entry中key比较大小是根据比较器comparator来进行判断的。size是红黑树的节点个数。
7. Map与Set的区别
Set代表无序的,元素不可重复的集合;
Map代表具有映射关系(key-value)的集合,其所有的key是一个Set集合,即key无序且不能重复。
8. List和Set有什么区别
Set代表无序的,元素不可重复的集合;
List代表有序的,元素可以重复的集合。
9. ArrayList和LinkedList有什么区别?
- ArrayList的实现是基于数组,LinkedList的实现是基于双向链表;
- 对于随机访问ArrayList要优于LinkedList,ArrayList可以根据下标,以O(1)时间复杂度对元素进行随机访问,而LinkedList的每个元素都依靠地址指针和它后一个元素连接在一起,查找某个元素的时间复杂度是O(N)。
- 对于插入和删除操作,LinkedList要优于ArrayList,因为当元素被添加到LinkedList任意位置的时候,不需要像ArrayList那样重新计算大小或者更新索引。
- LinkedList比ArrayList更占内存,因为LinkedList的节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向后一个元素。
10. 有哪些线程安全的List
- Vector
- Vector是比较古老的API,虽然保证了线程安全,但是由于效率低一般不建议使用。
- Collections.SynchronizedList
- SynchronizedList是Collections的内部类,Collections提供了synchronizedList方法,可以将一个线程不安全的List包装成线程安全的List,即SynchronizedList。它比Vector有更好的扩展性和兼容性,但是它所有的方法都带有同步锁,也不是性能最优的List。
- CopyOnWriteArrayList
- CopyOnWriteArrayList是Java 1.5在java.util.concurrent包下增加的类,它采用复制底层数组的方式来实现写操作。当线程对此类集合执行读取操作时,线程将会直接读取集合本身,无须加锁与阻塞。当线程对此类集合执行写入操作时,集合会在底层复制一份新的数组,接下来对新的数组执行写入操作。由于对集合的写入操作都是对数组的副本执行操作,因此它是线程安全的。在所有线程安全的List中,它是性能最优的方案。
11. ArrayList的数据结构
- ArrayList的底层是用数组来实现的,默认第一次插入元素时创建大小为10的数组,超出限制时会增加50%的容量,并且数据以 System.arraycopy() 复制到新的数组,因此最好能给出数组大小的预估值。
- 按数组下标访问元素的性能很高,这是数组的基本优势。直接在数组末尾加入元素的性能也高,但如果按下标插入、删除元素,则要用 System.arraycopy() 来移动部分受影响的元素,性能就变差了,这是基本劣势。
12. 谈谈CopyOnWriteArrayList的原理
- CopyOnWriteArrayList是Java并发包里提供的并发类,简单来说它就是一个线程安全且读操作无锁的ArrayList。正如其名字一样,在写操作时会复制一份新的List,在新的List上完成写操作,然后再将原引用指向新的List。这样就保证了写操作的线程安全。
- CopyOnWriteArrayList允许线程并发访问读操作,这个时候是没有加锁限制的,性能较高。而写操作的时候,则首先将容器复制一份,然后在新的副本上执行写操作,这个时候写操作是上锁的。结束之后再将原容器的引用指向新容器。注意,在上锁执行写操作的过程中,如果有需要读操作,会作用在原容器上。因此上锁的写操作不会影响到并发访问的读操作。
- 优点:读操作性能很高,因为无需任何同步措施,比较适用于读多写少的并发场景。在遍历传统的List时,若中途有别的线程对其进行修改,则会抛出ConcurrentModifificationException异常。而CopyOnWriteArrayList由于其"读写分离"的思想,遍历和修改操作分别作用在不同的List容器,所以在使用迭代器进行遍历时候,也就不会抛出ConcurrentModifificationException异常了。
- 缺点:
- 一是内存占用问题,毕竟每次执行写操作都要将原容器拷贝一份,数据量大时,对内存压力较大,可能会引起频繁GC。
- 二是无法保证实时性,Vector对于读写操作均加锁同步,可以保证读和写的强一致性。而CopyOnWriteArrayList由于其实现策略的原因,写和读分别作用在新老不同容器上,在写操作执行过程中,读不会阻塞但读取到的却是老容器的数据。
13. 说一说TreeSet和HashSet的区别
HashSet、TreeSet中的元素都是不能重复的,并且它们都是线程不安全的,二者的区别是:
- HashSet中的元素可以是null,但TreeSet中的元素不能是null;
- HashSet不能保证元素的排列顺序,而TreeSet支持自然排序、定制排序两种排序的方式;
- HashSet底层是采用哈希表实现的,而TreeSet底层是采用红黑树实现的。
14. HashSet的底层结构
HashSet是基于HashMap实现的,默认构造函数是构建一个初始容量为16,负载因子为0.75 的HashMap。它封装了一个 HashMap 对象来存储所有的集合元素,所有放入 HashSet 中的集合元素实际上由 HashMap 的 key 来保存,而 HashMap 的 value 则存储了一个 PRESENT,它是一个静态的Object 对象。
- HashSet底层是采用哈希表实现的,而TreeSet底层是采用红黑树实现的。
14. HashSet的底层结构
HashSet是基于HashMap实现的,默认构造函数是构建一个初始容量为16,负载因子为0.75 的HashMap。它封装了一个 HashMap 对象来存储所有的集合元素,所有放入 HashSet 中的集合元素实际上由 HashMap 的 key 来保存,而 HashMap 的 value 则存储了一个 PRESENT,它是一个静态的Object 对象。
以上是关于Java集合的主要内容,如果未能解决你的问题,请参考以下文章