爬取拉钩网.记录
Posted chenfeng30
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取拉钩网.记录相关的知识,希望对你有一定的参考价值。
昨天在scdn微信公众号看见一篇文章爬取拉勾网,自己前段时间也学习了爬虫所以练习一下,实践是检验真理的唯一标准.Let‘s do it.
第一步 登录(需要登录的网站需要自己登录之后需要的cookie不然自己会爬两页就断了,卡了很久才知道需要登录的原因,刚开始一直未某页错误因为之前遇到微博也是某页json放回数据错误,但是这次自己调试的过程发现it‘s ok,不是这个错误,之后问了大佬才知道登录需要cookie所以一定要登录。)
第二步 选择好职位 python和工作地点,然后我们观察,有30页,每页15个信息,点下一页url没变化,所以推断是ajax获取数据。所以我们检查元素看下。![]()
![]() 图1
图1
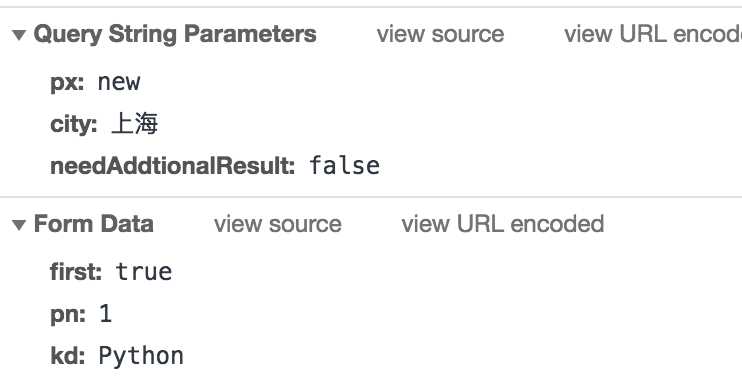 (因为是post提交方式,所以这是提交方式)图2
(因为是post提交方式,所以这是提交方式)图2
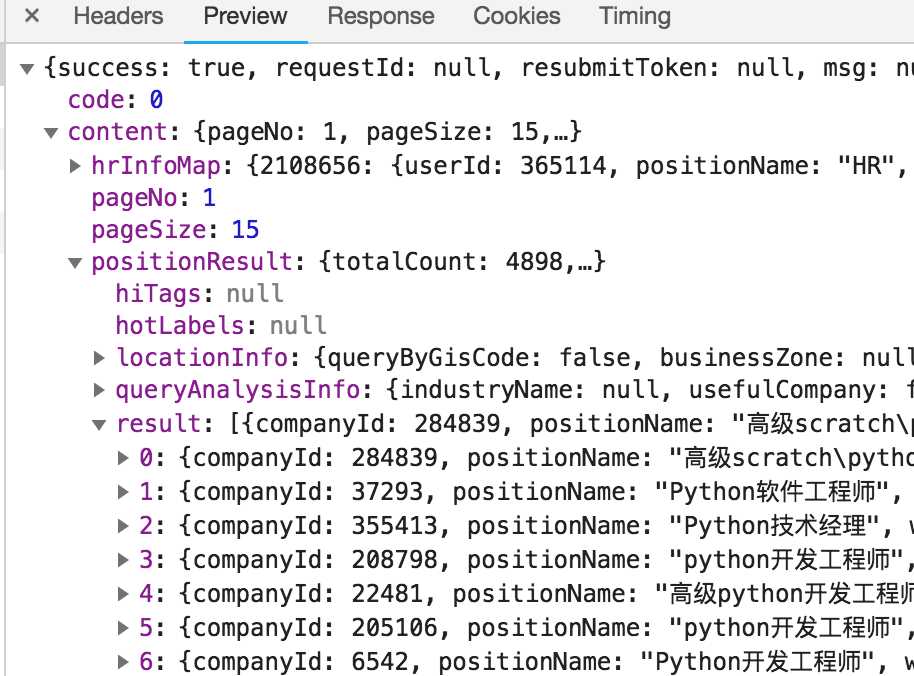
 (这是json返回的数据用来分析抓取)图三
(这是json返回的数据用来分析抓取)图三
第三步:写代码
思路是先构造请求在放回json最后解析(爬虫一般思路请求解析存储)
从图一图二写出:
url = "https://www.lagou.com/jobs/positionAjax.json"
querystring = {"px": "new", "city": city, "needAddtionalResult": "false"}
payload = "first=false&pn=" + str(page) + "&kd="+str(kd)
cookie ="_ga=GA1.2.1677642684.1533083099; user_trace_token=20180801082502-5525b120-9521-11e8-a086-5254005c3644; LGUID=20180801082502-5525b4ed-9521-11e8-a086-5254005c3644; WEBTJ-ID=20180830193906-1658aa1387effa-0d48b3aebf7538-34637908-1296000-1658aa1387f4; _gid=GA1.2.183924778.1535629147; X_HTTP_TOKEN=840afea5ca10f8de67f7e3185741e2d3; JSESSIONID=ABAAABAAAIAACBI74880516788D36C37A80301A549A5342; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; PRE_HOST=www.baidu.com; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1535629173,1535629312,1535687304,1535687309; LGSID=20180831114858-ca3b004c-acd0-11e8-be5c-525400f775ce; PRE_UTM=m_cf_cpc_baidu_pc; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Fbaidu.php%3Fsc.060000jZYuibWkd0MhS3CQd3smmhBTeqVX5_PolefrGF5TIf5szlkm2x13wCtZCOdy8AO6U6C3ToaZi6K9Smcp__Sa1Vkf7euDLanB1FJIexW5U6PUBnD5DAk3uaCD-PPqOmu03Wk3K_wp8J_1TTNnr1P8k_yfKFCKh21XjN1qpELJedn0.DY_NR2Ar5Od663rj6tJQrGvKD7ZZKNfYYmcgpIQC8xxKfYt_U_DY2yP5Qjo4mTT5QX1BsT8rZoG4XL6mEukmryZZjzqAM-HgguoLtVviEGzF4T5MY3IMo9vUt5M8se5gjlSXZ1tT5ot_rSVi_nYQAeIEvX26.U1Yk0ZDqs2v4VnL30ZKGm1Yk0Zfqs2v4VnL30A-V5HcsP0KM5yF-TZns0ZNG5yF9pywd0ZKGujYd0APGujYdn6KVIjYknjDLg1DsnH-xnH0zndtknjfvg1nvnjD0pvbqn0KzIjYzn100uy-b5HDYn19xnWDsrHwxnWm1PHKxnW04nWb0mhbqnW0Y0AdW5HTLP16dn101n-tknj0kg17xnH0zg100TgKGujYs0Z7Wpyfqn0KzuLw9u1Ys0A7B5HKxn0K-ThTqn0KsTjYkPH6Ln1RsnHc10A4vTjYsQW0snj0snj0s0AdYTjYs0AwbUL0qn0KzpWYs0Aw-IWdsmsKhIjYs0ZKC5H00ULnqn0KBI1Ykn0K8IjYs0ZPl5fKYIgnqPHDzPjmdrHndP1ndrj0sPjDYPfKzug7Y5HDdn1RvrjT1nWbzPWc0Tv-b5HbsrH61PWPBnj0snj-9m100mLPV5H04nYmLnRujnbndnDf3f1f0mynqnfKsUWYs0Z7VIjYs0Z7VT1Ys0ZGY5H00UyPxuMFEUHYsg1Kxn7tsg100uA78IyF-gLK_my4GuZnqn7tsg1Kxn1D3P10kg100TA7Ygvu_myTqn0Kbmv-b5Hcvrjf1PHfdP6K-IA-b5iYk0A71TAPW5H00IgKGUhPW5H00Tydh5H00uhPdIjYs0AulpjYs0Au9IjYs0ZGsUZN15H00mywhUA7M5HD0UAuW5H00mLFW5HDzPjnd%26ck%3D5280.1.101.282.601.285.595.150%26shh%3Dwww.baidu.com%26us%3D1.0.2.0.0.0.0%26ie%3DUTF-8%26f%3D8%26tn%3Dbaidu%26wd%3Dlagouwang%26oq%3Dlagouwang%26rqlang%3Dcn%26bc%3D110101; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Flp%2Fhtml%2Fcommon.html%3Futm_source%3Dm_cf_cpc_baidu_pc%26m_kw%3Dbaidu_cpc_xm_e110f9_d2162e_%25E6%258B%2589%25E5%258B%25BE%25E7%25BD%2591; LG_LOGIN_USER_ID=97836cca9baae98b3bc9e98a6d4b90742819cb3566e9d2e07476f3f854565b8d; _putrc=32CB89CF2B125447123F89F2B170EADC; login=true; unick=%E9%99%88%E9%94%8B; gate_login_token=b7a027846efc45e2e717c78913f3947fef48be926751aa8a03476b8d97ed8b3d; index_location_city=%E5%85%A8%E5%9B%BD; TG-TRACK-CODE=index_search; _gat=1; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1535687451; LGRID=20180831115119-1e7c8703-acd1-11e8-be5c-525400f775ce; SEARCH_ID=fdb566c9ec454718aa420a6042cece8d"
headers = {‘cookie‘: cookie,‘origin‘: "https://www.lagou.com",‘x-anit-forge-code‘: "0",‘accept-encoding‘: "gzip, deflate, br",‘accept-language‘: "zh-CN,zh;q=0.8,en;q=0.6",‘user-agent‘: "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",‘content-type‘: "application/x-www-form-urlencoded; charset=UTF-8",‘accept‘: "application/json, text/javascript, */*; q=0.01",‘referer‘: "https://www.lagou.com/jobs/list_Java?px=new&city=%E6%88%90%E9%83%BD",‘x-requested-with‘: "XMLHttpRequest",‘connection‘: "keep-alive",‘x-anit-forge-token‘: "None",‘cache-control‘: "no-cache",‘postman-token‘: "91beb456-8dd9-0390-a3a5-64ff3936fa63"}
response = requests.request("POST", url, data=payload.encode(‘utf-8‘), headers=headers, params=querystring)
# print(response.text)
hjson = json.loads(response.text)
接下来就是解析了
hjson = json.loads(response.text)
a = "page"+str(page)
print(a)
for i in range(15):
positionName=hjson[‘content‘][‘positionResult‘][‘result‘][i][‘positionName‘]
companyId = hjson[‘content‘][‘positionResult‘][‘result‘][i][‘companyId‘]
positionId= hjson[‘content‘][‘positionResult‘][‘result‘][i][‘positionId‘]
salary = hjson[‘content‘][‘positionResult‘][‘result‘][i][‘salary‘]
city= hjson[‘content‘][‘positionResult‘][‘result‘][i][‘city‘]
district= hjson[‘content‘][‘positionResult‘][‘result‘][i][‘district‘]
companyShortName= hjson[‘content‘][‘positionResult‘][‘result‘][i][‘companyShortName‘]
education= hjson[‘content‘][‘positionResult‘][‘result‘][i][‘education‘]
workYear= hjson[‘content‘][‘positionResult‘][‘result‘][i][‘workYear‘]
industryField= hjson[‘content‘][‘positionResult‘][‘result‘][i][‘industryField‘]
financeStage= hjson[‘content‘][‘positionResult‘][‘result‘][i][‘financeStage‘]
companySize= hjson[‘content‘][‘positionResult‘][‘result‘][i][‘companySize‘]
job_desc = get_job_desc(positionId)
positionName_list.append(positionName)
salary_list.append(salary)
city_list.append(city)
district_list.append(district)
companyShortName_list.append(companyShortName)
education_list.append(education)
workYear_list.append(workYear)
industryField_list.append(industryField)
financeStage_list.append(financeStage)
companySize_list.append(companySize)
#job_desc_list.append(job_desc)
job_desc_list.append(‘‘)
print("positionName:%s,companyId:%s,salary:%s,district:%s,companyShortName:%s,education:%s,workYear:%s"%(positionName,companyId,salary,district,companyShortName,education,workYear))
#print("position:%s"%(job_desc))
这里面有一个需要注意的是当我获取职位describe的时候我们点击一条信息他会再跳出一个页面,我们需要在从这个页面抓取信息所以需要再次请求所以在写一个函数
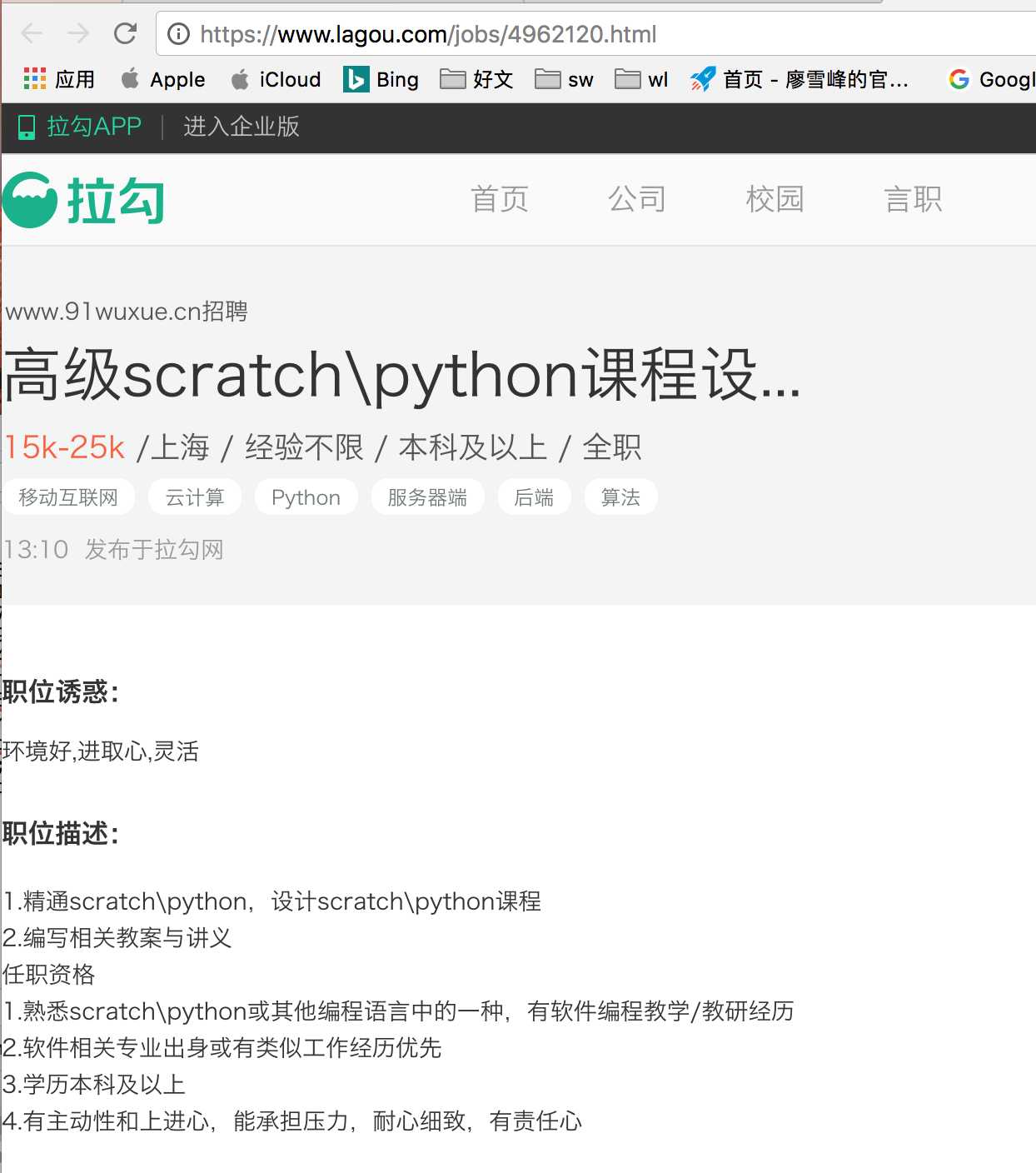 (这时候我们观察url发现如果要构造请求需要有一个4962120那么一串数字在哪里呢?你会发现他出现在图三positionID因为我随便点的所以不一样)所以我们可以通过上面解析解析出来positionID。)图四
(这时候我们观察url发现如果要构造请求需要有一个4962120那么一串数字在哪里呢?你会发现他出现在图三positionID因为我随便点的所以不一样)所以我们可以通过上面解析解析出来positionID。)图四
我们在这个页面检查元素看如何请求解析到职位描述:
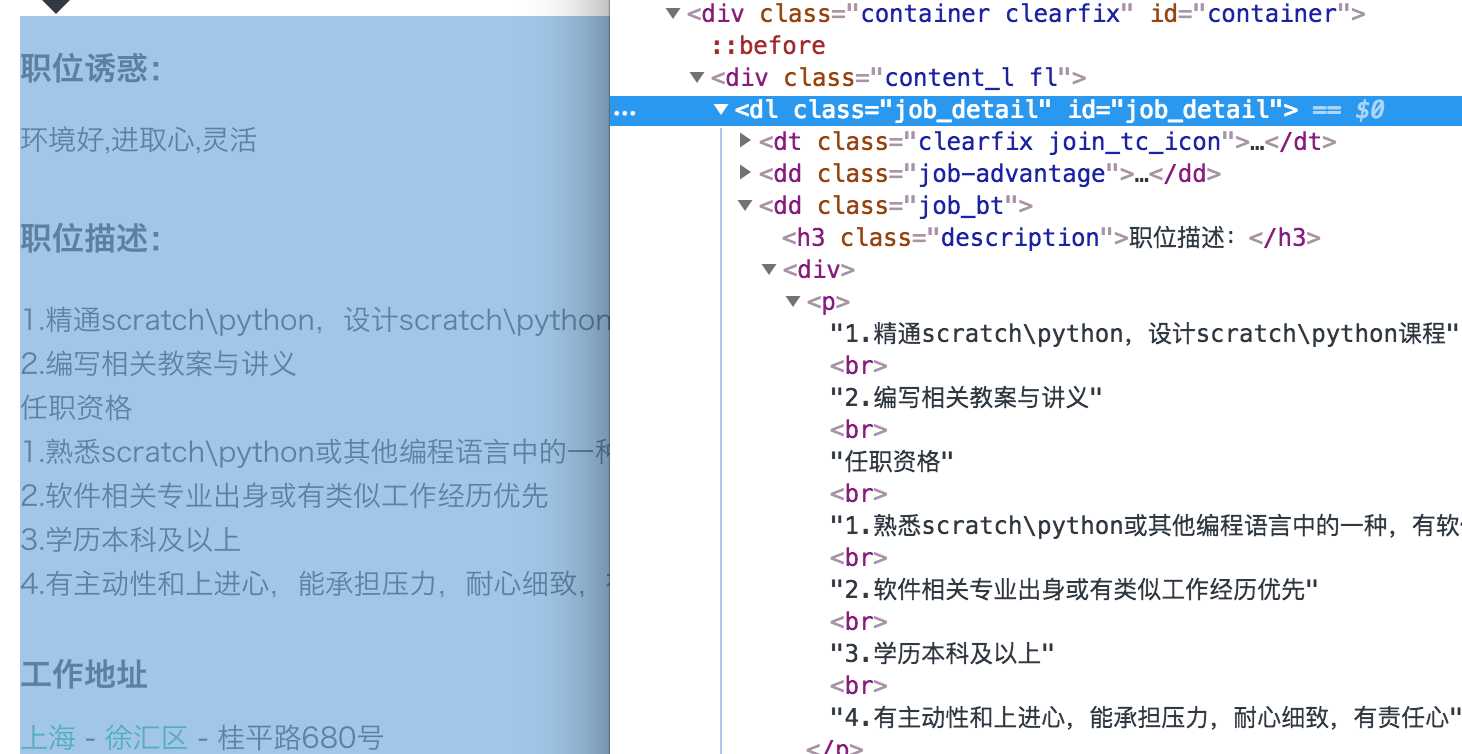
 图五六
图五六
def get_job_desc(id):
构造请求因为是get跟上面不一样一定要加cookie
url = "https://www.lagou.com/jobs/"+str(id)+".html"
cookie ="_ga=GA1.2.1677642684.1533083099; user_trace_token=20180801082502-5525b120-9521-11e8-a086-5254005c3644; LGUID=20180801082502-5525b4ed-9521-11e8-a086-5254005c3644; WEBTJ-ID=20180830193906-1658aa1387effa-0d48b3aebf7538-34637908-1296000-1658aa1387f4; _gid=GA1.2.183924778.1535629147; X_HTTP_TOKEN=840afea5ca10f8de67f7e3185741e2d3; JSESSIONID=ABAAABAAAIAACBI74880516788D36C37A80301A549A5342; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; PRE_HOST=www.baidu.com; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1535629173,1535629312,1535687304,1535687309; LGSID=20180831114858-ca3b004c-acd0-11e8-be5c-525400f775ce; PRE_UTM=m_cf_cpc_baidu_pc; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Fbaidu.php%3Fsc.060000jZYuibWkd0MhS3CQd3smmhBTeqVX5_PolefrGF5TIf5szlkm2x13wCtZCOdy8AO6U6C3ToaZi6K9Smcp__Sa1Vkf7euDLanB1FJIexW5U6PUBnD5DAk3uaCD-PPqOmu03Wk3K_wp8J_1TTNnr1P8k_yfKFCKh21XjN1qpELJedn0.DY_NR2Ar5Od663rj6tJQrGvKD7ZZKNfYYmcgpIQC8xxKfYt_U_DY2yP5Qjo4mTT5QX1BsT8rZoG4XL6mEukmryZZjzqAM-HgguoLtVviEGzF4T5MY3IMo9vUt5M8se5gjlSXZ1tT5ot_rSVi_nYQAeIEvX26.U1Yk0ZDqs2v4VnL30ZKGm1Yk0Zfqs2v4VnL30A-V5HcsP0KM5yF-TZns0ZNG5yF9pywd0ZKGujYd0APGujYdn6KVIjYknjDLg1DsnH-xnH0zndtknjfvg1nvnjD0pvbqn0KzIjYzn100uy-b5HDYn19xnWDsrHwxnWm1PHKxnW04nWb0mhbqnW0Y0AdW5HTLP16dn101n-tknj0kg17xnH0zg100TgKGujYs0Z7Wpyfqn0KzuLw9u1Ys0A7B5HKxn0K-ThTqn0KsTjYkPH6Ln1RsnHc10A4vTjYsQW0snj0snj0s0AdYTjYs0AwbUL0qn0KzpWYs0Aw-IWdsmsKhIjYs0ZKC5H00ULnqn0KBI1Ykn0K8IjYs0ZPl5fKYIgnqPHDzPjmdrHndP1ndrj0sPjDYPfKzug7Y5HDdn1RvrjT1nWbzPWc0Tv-b5HbsrH61PWPBnj0snj-9m100mLPV5H04nYmLnRujnbndnDf3f1f0mynqnfKsUWYs0Z7VIjYs0Z7VT1Ys0ZGY5H00UyPxuMFEUHYsg1Kxn7tsg100uA78IyF-gLK_my4GuZnqn7tsg1Kxn1D3P10kg100TA7Ygvu_myTqn0Kbmv-b5Hcvrjf1PHfdP6K-IA-b5iYk0A71TAPW5H00IgKGUhPW5H00Tydh5H00uhPdIjYs0AulpjYs0Au9IjYs0ZGsUZN15H00mywhUA7M5HD0UAuW5H00mLFW5HDzPjnd%26ck%3D5280.1.101.282.601.285.595.150%26shh%3Dwww.baidu.com%26us%3D1.0.2.0.0.0.0%26ie%3DUTF-8%26f%3D8%26tn%3Dbaidu%26wd%3Dlagouwang%26oq%3Dlagouwang%26rqlang%3Dcn%26bc%3D110101; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Flp%2Fhtml%2Fcommon.html%3Futm_source%3Dm_cf_cpc_baidu_pc%26m_kw%3Dbaidu_cpc_xm_e110f9_d2162e_%25E6%258B%2589%25E5%258B%25BE%25E7%25BD%2591; LG_LOGIN_USER_ID=97836cca9baae98b3bc9e98a6d4b90742819cb3566e9d2e07476f3f854565b8d; _putrc=32CB89CF2B125447123F89F2B170EADC; login=true; unick=%E9%99%88%E9%94%8B; gate_login_token=b7a027846efc45e2e717c78913f3947fef48be926751aa8a03476b8d97ed8b3d; index_location_city=%E5%85%A8%E5%9B%BD; TG-TRACK-CODE=index_search; _gat=1; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1535687451; LGRID=20180831115119-1e7c8703-acd1-11e8-be5c-525400f775ce; SEARCH_ID=fdb566c9ec454718aa420a6042cece8d"
headers = {‘cookie‘: cookie,‘origin‘: "https://www.lagou.com",‘x-anit-forge-code‘: "0",‘accept-encoding‘: "gzip, deflate, br",‘accept-language‘: "zh-CN,zh;q=0.8,en;q=0.6",‘user-agent‘: "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",‘content-type‘: "application/x-www-form-urlencoded; charset=UTF-8",‘accept‘: "application/json, text/javascript, */*; q=0.01",‘referer‘: "https://www.lagou.com/jobs/list_Java?px=new&city=%E6%88%90%E9%83%BD",‘x-requested-with‘: "XMLHttpRequest",‘connection‘: "keep-alive",‘x-anit-forge-token‘: "None",‘cache-control‘: "no-cache",‘postman-token‘: "91beb456-8dd9-0390-a3a5-64ff3936fa63"}
response = requests.request("GET", url, headers=headers)
接下来是解析利用xpath解析
x = etree.HTML(response.text)
data = x.xpath(‘//*[@id="job_detail"]/dd[2]/div/*/text()‘)
如何把<p>里面文字抓取下来呢利用join??
return ‘‘.join(data)
之后就是保存了
def write_to_csv(city,job):
infos = {‘positionName‘: positionName_list, ‘salary‘: salary_list, ‘city‘: city_list, ‘district‘: district_list, ‘companyShortName‘: companyShortName_list, ‘education‘: education_list,‘workYear‘:workYear_list,‘industryField‘:industryField_list,‘financeStage‘:financeStage_list,‘companySize‘:companySize_list,‘job_desc‘:job_desc_list}
data = pd.DataFrame(infos, columns=[‘positionName‘, ‘salary‘, ‘city‘, ‘district‘, ‘companyShortName‘, ‘education‘,‘workYear‘,‘industryField‘,‘financeStage‘,‘companySize‘,‘job_desc‘])
data.to_csv("lagou-"+city+"-"+job+".csv")
总结
通过这小案例是我明白了cookie的重要性以及get和post请求方式的不同。
最后附上原文地址https://mp.weixin.qq.com/s?__biz=MjM5MjAwODM4MA==&mid=2650703784&idx=1&sn=5f310cd670afeba256d3ddd613132417&chksm=bea6f67b89d17f6d16ee8fc139a4b5dc995d7f4951a8a243aa7849da7572851c5f880acdfe20&mpshare=1&scene=23&srcid=0830xPWlunTlWYdTLjr6Kp1I%23rd(
以及github源码:https://github.com/liaolongfei/lagou/
以上是关于爬取拉钩网.记录的主要内容,如果未能解决你的问题,请参考以下文章