一次活动引发的血案
Posted zyfd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一次活动引发的血案相关的知识,希望对你有一定的参考价值。
本文来自网易云社区
作者: 方金德
“咚咚”,接连收到好几个报警短信,显示线上集群的几个tomcat应用的接连端口异常。不好,线上可能出状况了,访问网站,果然已经显示为维护中了。赶紧登陆到服务器,但服务器的cpu,load,内存,io等基本指标都还是挺正常的,应用日志端也没有明显异常信息,不过nginx的访问日志的确显示后端服务器都已基本为504请求超时了。不管那么多了,距离上次发布已经有几个小时了,应该不是新版本bug直接导致的问题,先尝试不回滚重启吧。于是火速重启了集群中一个节点,很快线上应用访问正常了。然后把另外两个节点的jvm的stack和memory信息导出来后,也重启后加回到线上。
线上是正常了,但我们其实并没有找到问题的原因。没有找到问题的诱因,也就意味着这个问题可能还会再发生。和相关的同事们再一起排查了一遍线上应用日志和tomcat容器日志,也没有发现什么可挖掘的异常点。再跑到网易的监控平台看历史的监控数据,系统层面的cpu、load、 中断、 memory、 swap、 ioutil、网络流量等都没有特别的异常;jvm层面的gc、thread数也都没有什么明显异常。gc没有问题,直接放弃了memory dump信息的查看。再简单地看了下jstack信息,好像也没有什么异常,统计了下线程数,跟线上的线程数也差不多,猜测应该也不是属于并发超限吧。。。
最近产品这边正在做活动,大概的内容是鼓励用户邀请好友来注册。可能是大奖比较对其口味吧,来了几个不受欢迎的“hacker”用户。不知道他们在哪搞了一推“真实的“urs账号,然后通过脚步注册成为我们的用户(这里说一下,我们产品是直接接受新来访的urs账号为新注册用户的)。最近的日新增用户数和在线用户数分别是平常的3和2倍左右,于是有同事怀疑,是不是访问压力大了导致?这个怀疑非常应景,但我觉得缺少相应的服务器数据说明。如果是访问压力大的原因,不可能cpu,load,网络流量等都还是比较正常的,而且重启后也能一直访问正常。也曾想把这个问题归结到可怜的云主机上,因为现在一些节点,由于云主机超售,到导致cpu steal现象严重,load异常偏高,不过确实这个更加没有根据了,纯yy下吧!~ 好了,连活动导致访问量大这个这么应景的疑点,也没法成为症结。一时间没了想法,线上系统恢复后也运行的挺正常的(包括服务器、jvm等指标以及日志信息),加上最近大家的业务开发任务也挺重的,这个问题的根本原因的排查便被当做一个遗留问题,日后再排查吧。当然,作为技术人员,遇到了解决不了的技术问题,肯定是要“不开心”了。。。
带着这个问题回到了家。平常工作时间思绪比较繁杂,难免导致推断逻辑毛糙。趁着洗澡时没什么杂念,再重新理一遍整个过程。果然是最近脑子不好使了,其实问题还是挺明显的。服务器各项指标是比较正常的,但是前端的nginx连接过来都是504请求超时,那多半应该是后端的tomcat的请求过程被锁住了。有可能是请求被死锁了,也有可能是请求等待内部的其他请求超时了,也就是线程的WAIT或TIMED_WAIT状态。想到这里,发现自己下午只是简单的人肉扫了一下jstack内容和统计了下线程数,真是“too young,too simple,sometime naive”了~ 。
写个脚步扫一下WAIT线程情况吧,“ cat jstack20141127 | sed -n "/WAIT/,/^$/p" ”,在逐个看下具体的堆栈内容。排除了JMS receiver等正常的情况,发现了一个等待异常非常可疑,具体内容如下图。这里我把相关背景这这里简单的描述下。这端逻辑发生在我们产品的认证过滤器AuthenticationFilter,
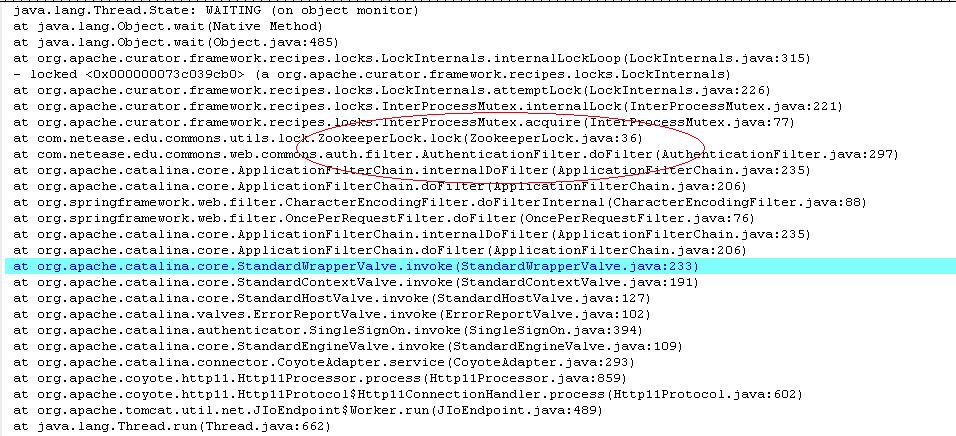
中,主要的逻辑是这样的,首先是检查用户的登录cookie(例如urs cookie等)是否有效,进而判断该urs账号是否已经是我们的用户,如果是就加载用户相关信息到session,否则增加该用户,并更新用户信息到session。其中,我们增加了使用zookeeper实现的分布式互斥锁来防止并发 新增相同的用户记录。 (这里顺便说下,因为ddb数据库不支持非均衡字段unique key,所以无法简单地使用unique key 来实现。当然,使用zookeeper lock来做并发控制本身也是一个更好的选择,可以避免无谓的错误数据库请求。)
再用脚步扫描了这种问题的个数,多达200个。200这个数字,正好是tomcat默认的maxThreads值。线上的tomcat应用服务器也的确是使用了这个默认值作为应用容器的过载保护。(发生问题的应用所在的云主机的配置不高,这个配置应该也是合理的。)说也是巧,正在此时,服务器再度报警,症状完全一致。不多想了,赶紧重启,并在间隙中做了必要的场景记录。可重现的问题,是一颗定时炸弹,必须赶紧修复啊。不过既然问题可以规律性的重现,那么肯定也会是好解决的~
好了,重新整理下思绪 ,推断有如下四种可能:
1.lock和unlock不能严格匹配保证,存在有节点被lock住了后没有释放的情况,导致后续相同key的请求被死锁。
2.zookeeper的lock机制本身或者我们的应用方式是否存在问题,例如在lock客户端(即应用服务器)发生重启或网络问题时,是否可能会导致lock节点发生释放泄漏的问题?
3.lock所保护的临界区代码块,内部执行非常缓慢,而外部却因为好友邀请注册活动(加上hacker问题)导致请求量偏大。生产持续大于消费,导致并发情况下lock数量累增并超限。
4.基本同上,但是因为 临界区代码块内部逻辑导致发生死锁。导致lock数量稳增不减,并最后超限。
在逐一分析上述可能之前,我先补充下我们这边的lock设计。

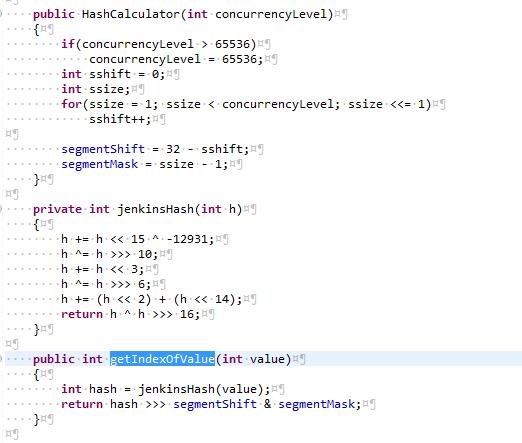
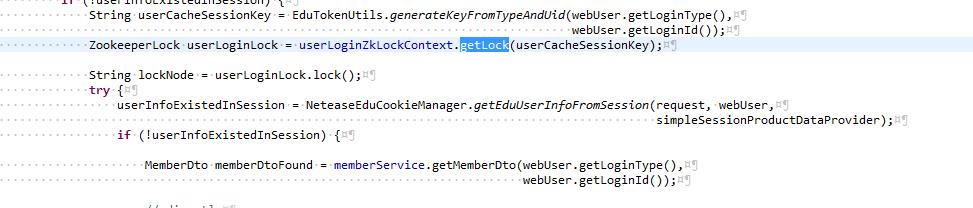
如上图,总体的设计思路同JDK的ConcurrentHashMap。每个lockContext代表一个业务场景,包含了业务场景的描述desciription,命名空间namespace(zookeeper的path prefix),和并发度concurrencyLevel(类似于 ConcurrentHashMap的桶数量 ) 。 lockContext会 对输入key的原生hashcode值做Wang/Jenkins hash计算,再按照 concurrencyLevel取余得到对应lock节点位置。最终index值一样的key会被放在一个节点(桶)上排队(等待锁资源)。例如一个典型的用户登录的lock节点位置如下:/prod-edu-share/locks_v2/userLoginSession/102/[ephemeral node] 。这么做的原因,还是类似于 ConcurrentHashMap的设计初衷,一方面,通过控制桶数量,来控制单位场景使用的资源数(例如zookeeper的节点数,这将限制zookeeper的内存消耗,单个目录下节点数,以及list子节点内容等操作的性能);另外一方面,通过 Wang/Jenkins hash等 有效的hash算法,尽可能均匀地根据数据内容对请求进行分割,以提交整体并发度。 正是因为上述设计,在用户基数大的情况下,不同的用户访问也是有可能会因为hash碰撞到被放在一起排队。不过这本身也是没有问题的,因为正常情况下, 请求总能够被快速处理完成,加上 hash算法够均匀, 桶大小合乎请求并发度需求 ,是不会有功能或者性能问题的。当然,也许可能是现有的hash并发度设置开始显小了?好吧,不管这么样,可以开始分析前面列的四种可能了。
首先,肯定是看case 1,即unlock是否能保证了。仔细的看了unlock的语句位置,它非常准确的立在了正确的finally语句块里面,jvm应该可以保证它不会出问题了。接着就看case 2了, zookeeper lock 毕竟也是个远程服务啊,它本身是否可靠,在系统发生各种异常时(一般是服务器重启,网络不稳定等)。前面提到的finally语句块,只能保证jvm运行时会被运行到,但如果在lock后,unlock执行前,jvm被关闭了呢?再重新仔细去看了zookeeper及lock功能的实现,发现zookeeper lock在实现时已经考虑到这些。lock的排队节点,采用的是session生命周期的ephemeral node,而sessionId是zookeeper成功连接到服务器后,保留着zookeeper实例里面,即位置在jvm内存里面,所以到jvm发生重启后,sessionId就消失了,亦即服务器端session也是迟早要失效的(这个有效期就是session timeout,可通过客户端连接参数进行配置,一般是60s),session失效后,改节点就会从排队中移除,从而不会导致死锁问题。另外一种情况,就是client jvm没有重启,但是网络不稳定,在这种情况下,如果网络是短暂问题,你们底层的curator实现会保证unlock操作被重复运行直至连接恢复,删除操作完成,而网络问题如果是长期的,curator会重复尝试直至session timeout后最终fail,但session node还是会在session invalid后被服务器删除。因此,上述两种网络问题,也都不会导致节点删除泄漏而被死锁。
既然unlock操作或者session ephemeral node在底层机制上是有保障的,那么问题就应该出现在临界区代码块的实现上了。事实上,我们在应用这个zookeeper lock的业务场景还是挺广泛了,但发生WAIT的线程却只有这个一个业务点,一定程度上也能从侧面回应这个结论。由于临界区代码的逻辑还是有点多的,这里我就不贴出来了。大概是判断member是否存在,没有就新增member记录,同时更新用户附属的其他表的初始化信息,然后是记录登录行为,更新相关营销信息(ps:这两者的确是可以异步处理的,可以后续优化,因为不是这个问题的重点,先不提了),最后更新用户信息到session。而逻辑之所以复杂,是因为我们产品上是支持urs,sns以及一些特殊合作网站等多种账号体系。但从技术上讲,就是一些数据库操作、日志操作,cache操作,从代码上看,也没有什么明显问题(不过事后发现自己还是不够仔细啊55~)。不管怎样,还是很容易区分是case3还是4的,因为如果是3,那么线上处于正确的运行态时,处于WAIT的线程数应该是动态的。jstack下线上服务器把,结果是这个数据基本上是比较稳定的,只升不降,而且即便到了晚上12以后,用户很少访问了还是如此。在从zookeeper 服务器端来看,部分桶上的ephemeral node,也是处于只增不删的状态。写了个脚步扫描了下各个桶的临时节点情况,发现有些大部分节点是正常的,但是个别节点数一直居高不下,例如下图中其中一个节点下临时子节点数居然搞到700+,汗 。
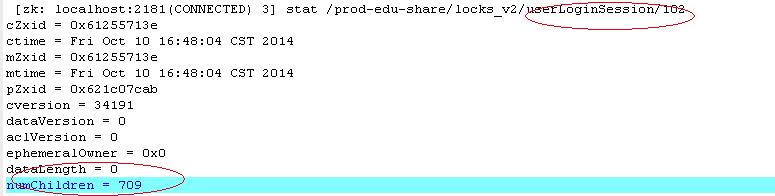
综上,基本可以断定,是属于case4的情况,即存在代码块的死锁。那么到底是哪块逻辑存在问题呢?而此时,已经夜深人困,还是先洗洗睡吧。
第二天到了公司,与相关同事同步了上述信息和推理。大家随即检测相关代码块哪里存在死锁问题。果然是“不知庐山真面目,只缘身在此山中”啊。其中一个同事很快发现两个可疑点。一个是从获取用户信息时,会通过远程调用从另外一个产品获取用户在那个产品中的信息,该远程调用会不会也在走类似的认证过滤器时被阻塞呢?(ps:这里要说明下,因为我们几个产品间的用户体系从逻辑上是互通的,在数据库层面是统一的,但由于历史问题尚未完成member的服务化,因此需要通过几个产品共享同一个锁进行并发控制。 )针对这个问题,我们再一起仔细看了代码,发现该远程调用走的是dubbo服务,因此不会走web的认证过滤器;同时在具体的逻辑里面,也没有调用相同的userLoginSession锁对象,因此可以排除。而另一个可疑点,是前面提到的那个特殊产品提供的账号登录验证的代理服务,这家伙正好是一个基于http的实现,按照其url pattern的定义,会被web认证过滤器扫描到的,尽管该远程服务其实是不需要也不应该经过认证过滤器的。开发者疏忽了,不管怎样,先赶紧去除吧。
至此,问题已经明朗了。当存在这种新账号类型的用户在应用A上新注册时,A应用便会先上锁,然后发远程请求给应用B,应用B因为相同用户请求相同的锁而发生死锁,非常典型的死锁实例。。。至于为什么这个问题之前没有爆发,最近才爆发,就涉及到一系列的历史问题了,这里就不再赘述了。大概是,其中该特殊账号类型的登录支持在产品A的加入,以及用户登录控制锁的统一(之前的登录锁实现是独立的,亦即没有跨产品并发控制效果,后面做了修复),都是最近一段时间才上线的功能。虽然二者确实是引发问题的根本原因,但是该特殊账号类型的登录用户量比较少,问题没有被暴露出来;而最近的邀请注册活动导致了大量的新用户注册行为,虽然账号类型是urs为主,但还是会因为hash而碰撞,继而累积导致http连接池耗尽,是问题的导火线。纸终究还是包不住火啊~
后面问题的解决,还出了点小插曲。就是按照设想,只要把几个产品的集群都重启下,就能消除所有的遗留session ephemeral node。然而在重启完成后,监控相关服务器发现还是存在零星的死锁线程,在60秒后(session 超时时间)还是如此,并且还在缓慢增加中。。。再分析下,原来是服务器的重启顺序不合理导致。得先把存在问题的产品服务器集群完全重启完成后,再去重启其他几个产品集群。终于,死锁线程都消失了,再监控了一段时间,也没有再新增。开心了!~
最后,总结下几点经验教训吧:
1.使用分布式锁时,一定要检查所包含的临界区代码块,以及间接调用的同步远程服务,确保其不会再请求相同的锁。因为远程服务不太好像本地线程一样实现锁的可重入性。
2.zookeeper非常有必要增加锁目录下ephemeral节点数的监控,以便能及时发现潜在的死锁问题。
3.分析问题时,还是要有局外人的怀疑精神,敢于怀疑一切未经重新验证的功能点。
4.俗话说,“三国臭皮匠,顶个诸葛亮”,团队成员之间的分享和讨论才是解决问题的关键。
网易云大礼包:https://www.163yun.com/gift
本文来自网易云社区,经作者方金德授权发布。
相关文章:
【推荐】 Android 应用防止被二次打包指南
【推荐】 块存储、文件存储、对象存储这三者的本质差别
【推荐】 感觉要火!妹子实地采访网易猪厂程序员七夕怎么过
以上是关于一次活动引发的血案的主要内容,如果未能解决你的问题,请参考以下文章