正则表达式
Posted kuruma
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式相关的知识,希望对你有一定的参考价值。
直接量语法
/pattern/attributes
创建 RegExp 对象的语法:
new RegExp(pattern, attributes);
五大属性
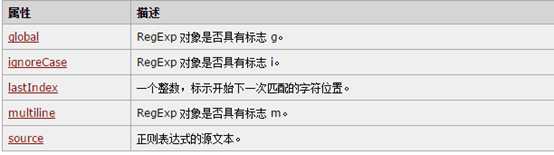
global:如果设置了new RegExp(‘s’,’g’),g(全局)被设置,所以global为true;
ignoreCase:同上,ignoreCase,对应的是i(大小写是否敏感);
lastIndex, var reg=/d/g;
var r=reg.exec(‘a1b2c3‘);
console.log(reg.lastIndex); //2
r=reg.exec(‘a1b2c3‘);
console.log(reg.lastIndex); //4
multiline:同上上:multiline对应m(多行匹配)
Source:var str = "Visit W3School.com.cn";
var patt1 = new RegExp("W3S","g");
document.write("The regular expression is: " + patt1.source);// W3S
方法
Var reg = /d/g;//正则表达式
Var str = ‘1c2v3r’;//你需要匹配的内容
RegExp 对象方法
RegExp对象方法就是 reg.fun(str)

Complie, 创建正则对象有两种方法:字面量和构造函数。compile基本等同于构造方法方式,且已被废弃。
Exec ,var result = reg.exec(str);它将返回一个数组
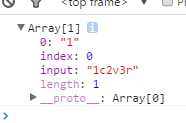
注释:只能执行一次,返回的数组就是当前的匹配内容的信息
0,表示需要匹配的内容,index表示匹配的位置,input匹配的内容 ;
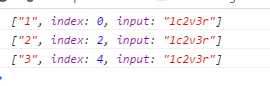
如果你想把全部的匹配出来:

Result:
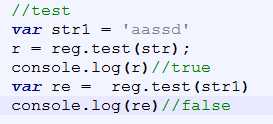
Test: 返回值为true或者false
reg.test(str);
String对象方法
Var reg = /d/;//正则表达式
Var str = ‘1c2v3r’;//你需要匹配的内容
String对象方法 str.fun(reg);与regExp对象方法相反

Search,search() 方法不执行全局匹配,它将忽略标志 g。它同时忽略 regexp 的 lastIndex 属性,并且总是从字符串的开始进行检索,这意味着它总是返回 stringObject 的第一个匹配的位置;它对i是支持的
它的返回值是检索的位置,若没有返回-1
Str.search(reg);//0;
Match, 返回数组,该方法类似 indexOf() 和 lastIndexOf(),但是它返回指定的值,而不是字符串的位置,而是检索出来的内容数组形式展现
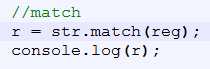
Result:

注释:(多个结果的返回,要加g,否知只返回第一个内容,若没有匹配结果则返回null)
注意:对多个数字的匹配
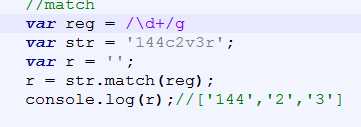
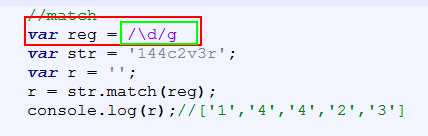
若只是单个
Replace,一些字符替换另一些字符,或替换一个与正则表达式匹配的子串。
Replace(reg/str, 替换的内容)

如果 regexp 具有全局标志 g,那么 replace() 方法将替换所有匹配的子串。否则,它只替换第一个匹配子串。
如果replace方法的第一个参数传入的是带分组的正则表达式,我们在第二个参数中可以使
用以下来获取相应的分组内容
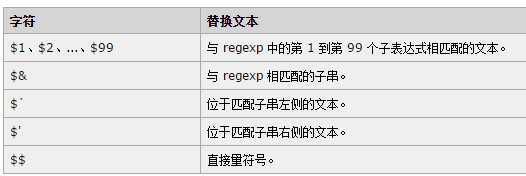

Result:@#1#@@#2#@@#3#@;
strObj.replace(regObj,function(){})
replace的fun方法
把replace方法的第二个参数传入一个function,这个function会在每次匹配替换的时候调用,算是个每次替换的回调函数,我们使用了回调函数的第一个参数,也就是匹配内容,其实回调函数一共有四个参数
第一个参数很简单,是匹配字符串
第二个参数是正则表达式分组内容,没有分组则没有该参数
第三个参数是匹配项在字符串中的index
第四个参数则是原字符串

自己尝试一下输出结果
Split, 用于把一个字符串分割成字符串数组,返回数组
Str.split(reg/需要分割的标识,取返回数组的长度);其方法类似js数组方法的操作;

以上是关于正则表达式的主要内容,如果未能解决你的问题,请参考以下文章