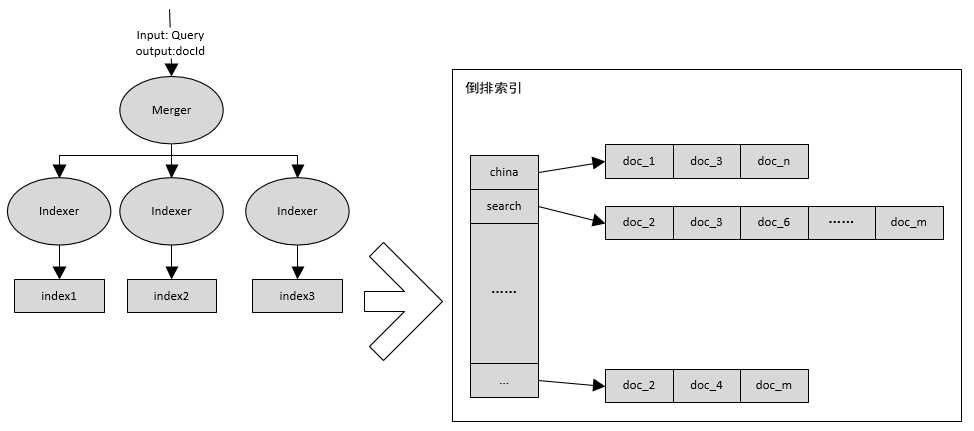
在SQL Server 中提供了一种名为全文索引的技术,可以大大提高从长字符串里搜索数
据的速度,不用在用LIKE这样低效率的模糊查询了。
下面简明的介绍如何使用Sql2008 全文索引
一、检查服务里面带有Full-text字样的服务是否存在并开启

如果不存在带有Full-text字样的服务的,确认是否安装了sqlserverFullTextSearch
--检查数据库PS2是否支持全文索引,如果不支持
--则使用sp_fulltext_database 打开该功能
if(select databaseproperty(‘PS2‘,‘isfulltextenabled‘))=0 execute sp_fulltext_database ‘enable‘
二、新建全文目录
全文目录是用来存储全文索引的
三、为表定义全文索引
四、点击下一步,按提示选择
1.确认下一步
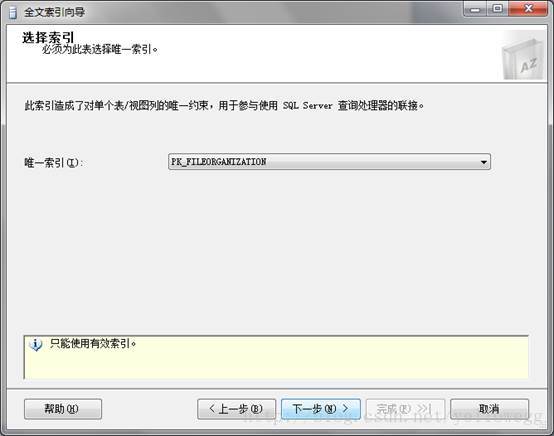
2.选择唯一索引,通常是主键
3.选择要建立的全文索引列,对于断字符的选择如果列存的是中文就选择chinese,如果是英文就选择English

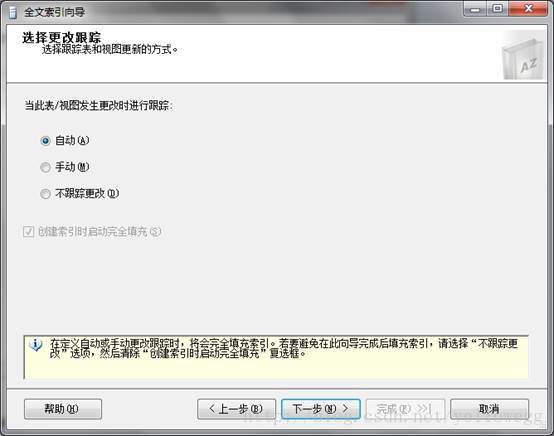
4.选择索引更新方式,可以先自动更新,以后数据量大了可以设置添加全文索引的计划
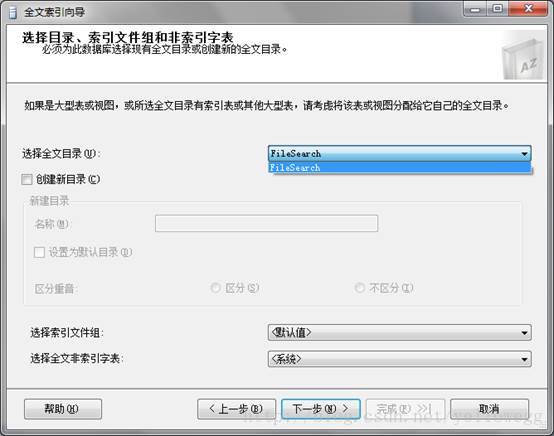
5.选择全文目录
五、全文索引的SQL查询关键字
建立好全文索引后就可以使用SQL语句来查询了,主要用带三个关键字 CONTAINS、FREETEXT、CONTAINSTABLE和FREETEXTTABLE
1. CONTAINS
搜索单个词和短语的精确或模糊的匹配项,要搜索的内容必须是个有意义的词语,比如说“苹果”、“建设厅”,不能是一些没意义的词语,比如“阿迪撒啊是”,“儿儿的”这样的词语即使
LIKE是能查询出来,但全文索引对这样没意义的词语可能没有建立索引,查不出来
- SELECT *
- FROM dbo.Business
- WHERE CONTAINS(Address,‘旅游‘)
实现功能:查询Business表中Address列包含“旅游”的行

2. FREETEXT
和CONTAINS类似,不同的是它会先把要查询的词语先进性分词然后在查询匹配项
- 01.select *
- 02.from dbo.Business
- 03.where freetext(Address,‘带婴儿旅游‘)

3.CONTAINSTABLE
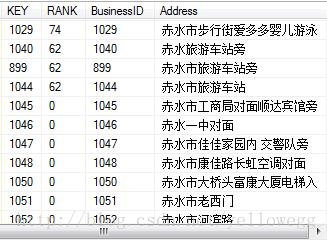
在查询方式上与 CONTAINS 几乎一样。但CONTAINSTABLE 返回的是符合查询条件的表,在 SQL 语句中我们可以把它当作一个普通的表来使用,并且使用 CONTAINSTABLE 的查询对每一行返回一个相关性排名值 (RANK) 和全文键 (KEY)。
- SELECT *
- FROM Business AS FT_TBL
- INNER JOIN CONTAINSTABLE(Business, *, ‘ISABOUT (婴儿 WEIGHT (.8),赤水 WEIGHT (.4) )‘)
- AS KEY_TBL ON FT_TBL.BusinessId = KEY_TBL.[KEY]
- ORDER BY KEY_TBL.RANK DESC
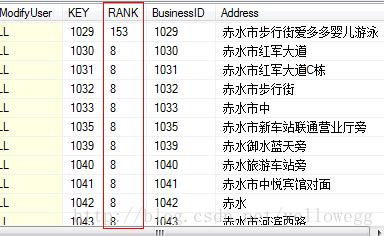
ISABOUT 是这种查询的关键字,weight 指定了一个介于 0~1之间的数,类似系数。表示不同条件有不同的侧重。
CONTAINSTABLE 返回的表包含有特殊的两列:KEY,RANK。
被全文索引的表必须有唯一索引。这个唯一的索引列在返回的表中就成为 KEY。我们通常把它作为表连接的条件。
在某些网站搜索时,结果中会出现表示匹配程度的数字,RANK 与此类似。它的值在0~1000之间,标识每一行与查询条件的匹配程度,程度越高,RANK 的值大,通常情况下,按照 RANK 的降序排列。
4. FREETEXTTABLE
在查询方式上与 FREETEXT 几乎一样。但 FREETEXTTABLE 返回的是符合查询条件的表,在 SQL 语句中我们可以把它当作一个普通的表来使用,并且使用 FREETEXT 的查询对每一行返回一个相关性排名值 (RANK) 和全文键 (KEY)。
- SELECT * ,
- BusinessID ,
- Address
- FROM Business AS FT_TBL
- INNER JOIN FREETEXTTABLE(Business, Address, ‘ISABOUT (带婴儿旅游 WEIGHT (.8),赤水 WEIGHT (.4) )‘)
- AS KEY_TBL ON FT_TBL.BusinessId = KEY_TBL.[KEY]
- ORDER BY KEY_TBL.RANK DESC
--activate,是激活表的全文检索能力,也就是在全文目录中注册该表
execute sp_fulltext_table ‘ProSearch‘,‘activate‘
--填充全文索引目录
execute sp_fulltext_catalog ‘ProSearchCatalog‘,‘start_full‘
--查询全文索引是否建立完毕(0:完毕;1:正在建立)
select fulltextcatalogproperty(‘ProSearchCatalog‘,‘populateStatus‘)
三、介绍一下全文索引的一些相关操作
查看全文检索的配置情况:
sp_help_fulltext_catalogs -- 检查数据库有哪些全文目录 sp_help_fulltext_tables ProSearchCatalog -- 查看哪些表把全文索引建立在T_testData下 sp_help_fulltext_columns ProSearch -- 查看test表哪些字段配置了全文索引
drop fulltext index on test -- 撤销test上的全文检索 drop fulltext catalog FT_testData -- 撤销全文目录FT_testData
详细介绍请查看全文:https://cnblogs.com/qianzf/
原文博客的链接地址:https://cnblogs.com/qzf/
全文索引需要注意:
- 表中必须有一个唯一性索引,当并不需要是主键。
- 一个表中只能有一个全文索引。
- 你需要告诉你的脚本你想使用全文索引,如何告诉呢?那就是使用关键字:CONTAINS、FULLTEXT、CONTAINSTABLE、FREETEXTTABLE。例如:SELECT * FROM table_name WHERE CONTAINS(fullText_column,‘"search contents*"‘);需要记住CONTAINS等在不同场景、需求下的用法。
- 如果定义了变量作为传入值,那么就要注意是否需要在set字符的时候的前面加入N标识。
- 要对表设置全文索引,那就得先对数据库设置了全文索引,这样点击表右键的时候,“全文索引”选项才能用。
- 脚本在查找的时候是不区分大小写的。解决办法:SELECT * FROM Table_name WHERE Column_name=‘A‘ COLLATE Chinese_PRC_CS_AI;或者SELECT * FROM Table_name WHERE ASCII(Column_name) = ASCII(‘A‘);
- Microsoft SQL Server 全文引擎 (MSFTESQL) 不是基于某一特定行中存储的值来构造 B 树结构,而是基于要索引的文本中的各个标记来创建倒排、堆积且压缩的索引结构。
- 全文索引并不一定能达到like这个谓词的效果,如LIKE ‘%qq%‘。这正是本篇文章想要说明的。
- 如果数据库是在移动盘符上,好像就无法设置:数据库-属性-文件-“使用全文索引”了,这个时候chckbox是不可用的。(这个大家可以求证一下)
- 关于搜索结果的排序问题,全文索引并没有这个功能,也就是匹配度排序或者说是相似度排序。
- Lucene中有一个Similarity类,Lucene Practical Scoring Function就包含了得分的计算公式,tf、idf。
参考转载:
1.全文索引的使用:https://www.cnblogs.com/qianzf/p/7131741.html
2.全文索引中的小坑:https://www.cnblogs.com/liwei225/p/5101716.html (核心意思就是一般不能绝对实现%%的功能,会出现许多不)
3.倒序排序的概念/全文索引的原理:https://www.cnblogs.com/gered/p/9561710.html