urllib2 Handler处理器和自定义opener
Posted alexzhang92
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了urllib2 Handler处理器和自定义opener相关的知识,希望对你有一定的参考价值。
Handler处理器 和 自定义Opener
-
opener是 urllib2.OpenerDirector 的实例,我们之前一直都在使用的urlopen,它是一个特殊的opener(也就是模块帮我们构建好的)。
-
但是基本的urlopen()方法不支持代理、cookie等其他的HTTP/HTTPS高级功能。所以要支持这些功能:
- 使用相关的
Handler处理器来创建特定功能的处理器对象; - 然后通过
urllib2.build_opener()方法使用这些处理器对象,创建自定义opener对象; - 使用自定义的opener对象,调用
open()方法发送请求。
- 使用相关的
-
如果程序里所有的请求都使用自定义的opener,可以使用
urllib2.install_opener()将自定义的 opener 对象 定义为 全局opener,表示如果之后凡是调用urlopen,都将使用这个opener(根据自己的需求来选择)
简单的自定义opener()
import urllib2 # 构建一个HTTPHandler 处理器对象,支持处理HTTP请求 http_handler = urllib2.HTTPHandler() # 构建一个HTTPHandler 处理器对象,支持处理HTTPS请求 # http_handler = urllib2.HTTPSHandler() # 调用urllib2.build_opener()方法,创建支持处理HTTP请求的opener对象 opener = urllib2.build_opener(http_handler) # 构建 Request请求 request = urllib2.Request("http://www.baidu.com/") # 调用自定义opener对象的open()方法,发送request请求 response = opener.open(request) # 获取服务器响应内容 print response.read() 这种方式发送请求得到的结果,和使用urllib2.urlopen()发送HTTP/HTTPS请求得到的结果是一样的。 如果在 HTTPHandler()增加 debuglevel=1参数,还会将 Debug Log 打开,这样程序在执行的时候,会把收包和发包的报头在屏幕上自动打印出来,方便调试,有时可以省去抓包的工作。 # 仅需要修改的代码部分: # 构建一个HTTPHandler 处理器对象,支持处理HTTP请求,同时开启Debug Log,debuglevel 值默认 0 http_handler = urllib2.HTTPHandler(debuglevel=1) # 构建一个HTTPHSandler 处理器对象,支持处理HTTPS请求,同时开启Debug Log,debuglevel 值默认 0 https_handler = urllib2.HTTPSHandler(debuglevel=1)
ProxyHandler处理器(代理设置)
使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的。
很多网站会检测某一段时间某个IP的访问次数(通过流量统计,系统日志等),如果访问次数多的不像正常人,它会禁止这个IP的访问。
所以我们可以设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
urllib2中通过ProxyHandler来设置使用代理服务器,下面代码说明如何使用自定义opener来使用代理:
#urllib2_proxy1.py import urllib2 # 构建了两个代理Handler,一个有代理IP,一个没有代理IP httpproxy_handler = urllib2.ProxyHandler({"http" : "124.88.67.81:80"}) nullproxy_handler = urllib2.ProxyHandler({}) proxySwitch = True #定义一个代理开关 # 通过 urllib2.build_opener()方法使用这些代理Handler对象,创建自定义opener对象 # 根据代理开关是否打开,使用不同的代理模式 if proxySwitch: opener = urllib2.build_opener(httpproxy_handler) else: opener = urllib2.build_opener(nullproxy_handler) request = urllib2.Request("http://www.baidu.com/") # 1. 如果这么写,只有使用opener.open()方法发送请求才使用自定义的代理,而urlopen()则不使用自定义代理。 response = opener.open(request) # 2. 如果这么写,就是将opener应用到全局,之后所有的,不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。 # urllib2.install_opener(opener) # response = urlopen(request) print response.read()
免费的开放代理获取基本没有成本,我们可以在一些代理网站上收集这些免费代理,测试后如果可以用,就把它收集起来用在爬虫上面。
免费短期代理网站举例:
如果代理IP足够多,就可以像随机获取User-Agent一样,随机选择一个代理去访问网站。
import urllib2 import random proxy_list = [ {"http" : "124.88.67.81:80"}, {"http" : "124.88.67.81:80"}, {"http" : "124.88.67.81:80"}, {"http" : "124.88.67.81:80"}, {"http" : "124.88.67.81:80"} ] # 随机选择一个代理 proxy = random.choice(proxy_list) # 使用选择的代理构建代理处理器对象 httpproxy_handler = urllib2.ProxyHandler(proxy) opener = urllib2.build_opener(httpproxy_handler) request = urllib2.Request("http://www.baidu.com/") response = opener.open(request) print response.read()
但是,这些免费开放代理一般会有很多人都在使用,而且代理有寿命短,速度慢,匿名度不高,HTTP/HTTPS支持不稳定等缺点(免费没好货)。
所以,专业爬虫工程师或爬虫公司会使用高品质的私密代理,这些代理通常需要找专门的代理供应商购买,再通过用户名/密码授权使用(舍不得孩子套不到狼)。
HTTPPasswordMgrWithDefaultRealm()
HTTPPasswordMgrWithDefaultRealm()类将创建一个密码管理对象,用来保存 HTTP 请求相关的用户名和密码,主要应用两个场景:
- 验证代理授权的用户名和密码 (
ProxyBasicAuthHandler()) - 验证Web客户端的的用户名和密码 (
HTTPBasicAuthHandler())
ProxyBasicAuthHandler(代理授权验证)
如果我们使用之前的代码来使用私密代理,会报 HTTP 407 错误,表示代理没有通过身份验证:
urllib2.HTTPError: HTTP Error 407: Proxy Authentication Required
所以我们需要改写代码,通过:
HTTPPasswordMgrWithDefaultRealm():来保存私密代理的用户密码ProxyBasicAuthHandler():来处理代理的身份验证。
#urllib2_proxy2.py import urllib2 import urllib # 私密代理授权的账户 user = "mr_mao_hacker" # 私密代理授权的密码 passwd = "sffqry9r" # 私密代理 IP proxyserver = "61.158.163.130:16816" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码 passwdmgr = urllib2.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码 passwdmgr.add_password(None, proxyserver, user, passwd) # 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象 # 注意,这里不再使用普通ProxyHandler类了 proxyauth_handler = urllib2.ProxyBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler opener = urllib2.build_opener(proxyauth_handler) # 5. 构造Request 请求 request = urllib2.Request("http://www.baidu.com/") # 6. 使用自定义opener发送请求 response = opener.open(request) # 7. 打印响应内容 print response.read()
HTTPBasicAuthHandler处理器(Web客户端授权验证)
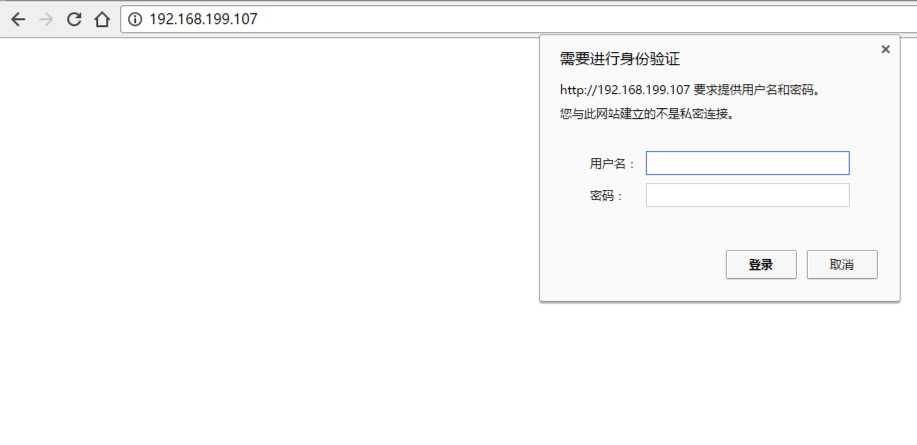
有些Web服务器(包括HTTP/FTP等)访问时,需要进行用户身份验证,爬虫直接访问会报HTTP 401 错误,表示访问身份未经授权:
urllib2.HTTPError: HTTP Error 401: Unauthorized
如果我们有客户端的用户名和密码,我们可以通过下面的方法去访问爬取:
import urllib import urllib2 # 用户名 user = "test" # 密码 passwd = "123456" # Web服务器 IP webserver = "http://192.168.199.107" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码 passwdmgr = urllib2.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 Web服务器、用户名、密码 passwdmgr.add_password(None, webserver, user, passwd) # 3. 构建一个HTTP基础用户名/密码验证的HTTPBasicAuthHandler处理器对象,参数是创建的密码管理对象 httpauth_handler = urllib2.HTTPBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler opener = urllib2.build_opener(httpauth_handler) # 5. 可以选择通过install_opener()方法定义opener为全局opener urllib2.install_opener(opener) # 6. 构建 Request对象 request = urllib2.Request("http://192.168.199.107") # 7. 定义opener为全局opener后,可直接使用urlopen()发送请求 response = urllib2.urlopen(request) # 8. 打印响应内容 print response.read()
Cookie
Cookie 是指某些网站服务器为了辨别用户身份和进行Session跟踪,而储存在用户浏览器上的文本文件,Cookie可以保持登录信息到用户下次与服务器的会话。
Cookie原理
HTTP是无状态的面向连接的协议, 为了保持连接状态, 引入了Cookie机制 Cookie是http消息头中的一种属性,包括:
Cookie名字(Name)
Cookie的值(Value)
Cookie的过期时间(Expires/Max-Age)
Cookie作用路径(Path)
Cookie所在域名(Domain),
使用Cookie进行安全连接(Secure)。
前两个参数是Cookie应用的必要条件,另外,还包括Cookie大小(Size,不同浏览器对Cookie个数及大小限制是有差异的)。
Cookie由变量名和值组成,根据 Netscape公司的规定,Cookie格式如下:
Set-Cookie: NAME=VALUE;Expires=DATE;Path=PATH;Domain=DOMAIN_NAME;SECURE
Cookie应用
Cookies在爬虫方面最典型的应用是判定注册用户是否已经登录网站,用户可能会得到提示,是否在下一次进入此网站时保留用户信息以便简化登录手续。
# 获取一个有登录信息的Cookie模拟登陆 import urllib2 # 1. 构建一个已经登录过的用户的headers信息 headers = { "Host":"www.renren.com", "Connection":"keep-alive", "Upgrade-Insecure-Requests":"1", "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/54.0.2840.99 Safari/537.36", "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8", "Accept-Language":"zh-CN,zh;q=0.8,en;q=0.6", # 便于终端阅读,表示不支持压缩文件 # Accept-Encoding: gzip, deflate, sdch, # 重点:这个Cookie是保存了密码无需重复登录的用户的Cookie,这个Cookie里记录了用户名,密码(通常经过RAS加密) "Cookie": "anonymid=ixrna3fysufnwv; depovince=GW; _r01_=1; JSESSIONID=abcmaDhEdqIlM7riy5iMv; jebe_key=f6fb270b-d06d-42e6-8b53-e67c3156aa7e%7Cc13c37f53bca9e1e7132d4b58ce00fa3%7C1484060607478%7C1%7C1484060607173; jebecookies=26fb58d1-cbe7-4fc3-a4ad-592233d1b42e|||||; ick_login=1f2b895d-34c7-4a1d-afb7-d84666fad409; _de=BF09EE3A28DED52E6B65F6A4705D973F1383380866D39FF5; p=99e54330ba9f910b02e6b08058f780479; ap=327550029; first_login_flag=1; [email protected]; ln_hurl=http://hdn.xnimg.cn/photos/hdn521/20140529/1055/h_main_9A3Z_e0c300019f6a195a.jpg; t=214ca9a28f70ca6aa0801404dda4f6789; societyguester=214ca9a28f70ca6aa0801404dda4f6789; id=327550029; xnsid=745033c5; ver=7.0; loginfrom=syshome" } # 2. 通过headers里的报头信息(主要是Cookie信息),构建Request对象 urllib2.Request("http://www.renren.com/", headers = headers) # 3. 直接访问renren主页,服务器会根据headers报头信息(主要是Cookie信息),判断这是一个已经登录的用户,并返回相应的页面 response = urllib2.urlopen(request) # 4. 打印响应内容 print response.read()
但是这样做太过复杂,我们先需要在浏览器登录账户,并且设置保存密码,并且通过抓包才能获取这个Cookie,那有么有更简单方便的方法呢?
cookielib库 和 HTTPCookieProcessor处理器
在Python处理Cookie,一般是通过cookielib模块和 urllib2模块的HTTPCookieProcessor处理器类一起使用。
cookielib模块:主要作用是提供用于存储cookie的对象
HTTPCookieProcessor处理器:主要作用是处理这些cookie对象,并构建handler对象。
cookielib 库
该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
CookieJar:管理HTTP cookie值、存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失。
FileCookieJar (filename,delayload=None,policy=None):从CookieJar派生而来,用来创建FileCookieJar实例,检索cookie信息并将cookie存储到文件中。filename是存储cookie的文件名。delayload为True时支持延迟访问访问文件,即只有在需要时才读取文件或在文件中存储数据。
MozillaCookieJar (filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与
Mozilla浏览器 cookies.txt兼容的FileCookieJar实例。LWPCookieJar (filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与
libwww-perl标准的 Set-Cookie3 文件格式兼容的FileCookieJar实例。
其实大多数情况下,我们只用CookieJar(),如果需要和本地文件交互,就用 MozillaCookjar() 或 LWPCookieJar()
我们来做几个案例:
1)获取Cookie,并保存到CookieJar()对象中
# urllib2_cookielibtest1.py import urllib2 import cookielib # 构建一个CookieJar对象实例来保存cookie cookiejar = cookielib.CookieJar() # 使用HTTPCookieProcessor()来创建cookie处理器对象,参数为CookieJar()对象 handler=urllib2.HTTPCookieProcessor(cookiejar) # 通过 build_opener() 来构建opener opener = urllib2.build_opener(handler) # 4. 以get方法访问页面,访问之后会自动保存cookie到cookiejar中 opener.open("http://www.baidu.com") ## 可以按标准格式将保存的Cookie打印出来 cookieStr = "" for item in cookiejar: cookieStr = cookieStr + item.name + "=" + item.value + ";" ## 舍去最后一位的分号 print cookieStr[:-1]
我们使用以上方法将Cookie保存到cookiejar对象中,然后打印出了cookie中的值,也就是访问百度首页的Cookie值。
运行结果如下:
BAIDUID=4327A58E63A92B73FF7A297FB3B2B4D0:FG=1;BIDUPSID=4327A58E63A92B73FF7A297FB3B2B4D0;H_PS_PSSID=1429_21115_17001_21454_21409_21554_21398;PSTM=1480815736;BDSVRTM=0;BD_HOME=0
2. 访问网站获得cookie,并把获得的cookie保存在cookie文件中
# urllib2_cookielibtest2.py import cookielib import urllib2 # 保存cookie的本地磁盘文件名 filename = ‘cookie.txt‘ # 声明一个MozillaCookieJar(有save实现)对象实例来保存cookie,之后写入文件 cookiejar = cookielib.MozillaCookieJar(filename) # 使用HTTPCookieProcessor()来创建cookie处理器对象,参数为CookieJar()对象 handler = urllib2.HTTPCookieProcessor(cookiejar) # 通过 build_opener() 来构建opener opener = urllib2.build_opener(handler) # 创建一个请求,原理同urllib2的urlopen response = opener.open("http://www.baidu.com") # 保存cookie到本地文件 cookiejar.save()
3. 从文件中获取cookies,做为请求的一部分去访问
# urllib2_cookielibtest2.py import cookielib import urllib2 # 创建MozillaCookieJar(有load实现)实例对象 cookiejar = cookielib.MozillaCookieJar() # 从文件中读取cookie内容到变量 cookie.load(‘cookie.txt‘) # 使用HTTPCookieProcessor()来创建cookie处理器对象,参数为CookieJar()对象 handler = urllib2.HTTPCookieProcessor(cookiejar) # 通过 build_opener() 来构建opener opener = urllib2.build_opener(handler) response = opener.open("http://www.baidu.com")
利用cookielib和post登录人人网
import urllib import urllib2 import cookielib # 1. 构建一个CookieJar对象实例来保存cookie cookie = cookielib.CookieJar() # 2. 使用HTTPCookieProcessor()来创建cookie处理器对象,参数为CookieJar()对象 cookie_handler = urllib2.HTTPCookieProcessor(cookie) # 3. 通过 build_opener() 来构建opener opener = urllib2.build_opener(cookie_handler) # 4. addheaders 接受一个列表,里面每个元素都是一个headers信息的元祖, opener将附带headers信息 opener.addheaders = [("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36")] # 5. 需要登录的账户和密码 data = {"email":"[email protected]", "password":"alaxxxxxime"} # 6. 通过urlencode()转码 postdata = urllib.urlencode(data) # 7. 构建Request请求对象,包含需要发送的用户名和密码 request = urllib2.Request("http://www.renren.com/PLogin.do", data = postdata) # 8. 通过opener发送这个请求,并获取登录后的Cookie值, opener.open(request) # 9. opener包含用户登录后的Cookie值,可以直接访问那些登录后才可以访问的页面 response = opener.open("http://www.renren.com/410043129/profile") # 10. 打印响应内容 print response.read()
模拟登录要注意几点:
- 登录一般都会先有一个HTTP GET,用于拉取一些信息及获得Cookie,然后再HTTP POST登录。
- HTTP POST登录的链接有可能是动态的,从GET返回的信息中获取。
- password 有些是明文发送,有些是加密后发送。有些网站甚至采用动态加密的,同时包括了很多其他数据的加密信息,只能通过查看JS源码获得加密算法,再去破解加密,非常困难。
- 大多数网站的登录整体流程是类似的,可能有些细节不一样,所以不能保证其他网站登录成功。
这个测试案例中,为了想让大家快速理解知识点,我们使用的人人网登录接口是人人网改版前的隐藏接口(嘘....),登录比较方便。
当然,我们也可以直接发送账号密码到登录界面模拟登录,但是当网页采用javascript动态技术以后,想封锁基于 HttpClient 的模拟登录就太容易了,甚至可以根据你的鼠标活动的特征准确地判断出是不是真人在操作。
所以,想做通用的模拟登录还得选别的技术,比如用内置浏览器引擎的爬虫(关键词:Selenium ,PhantomJS),这个我们将在以后会学习到。
以上是关于urllib2 Handler处理器和自定义opener的主要内容,如果未能解决你的问题,请参考以下文章